
Yapay Zeka
Deepfake Dedektörleri Yeni Bir Zemin Peşinde: Gizli Yayılma Modelleri ve GAN'lar

Görüş Son zamanlarda, 2017'nin sonlarından beri neredeyse tamamen otomatik kodlayıcıO zamanlar halkın hayranlığına (ve dehşetdahil olmak üzere daha az durgun mimarilere adli ilgi duymaya başlamıştır. gizli difüzyon gibi modeller DALL-E2 ve Kararlı DifüzyonÜretici Düşman Ağlarının (GAN'lar) çıktısının yanı sıra. Örneğin, Haziran ayında UC Berkeley sonuçları yayınladı o zamanlar baskın olan DALL-E 2'nin çıktısı için bir dedektörün geliştirilmesine yönelik araştırmasından.
Bu artan ilgiyi tetikleyen şey, 2022'de kapalı kaynak ve sınırlı erişim ile gizli difüzyon modellerinin yeteneği ve kullanılabilirliğindeki ani evrimsel sıçramadır. serbest İlkbaharda DALL-E 2, ardından yaz sonunda sansasyonel açık kaynak Stabil Difüzyonun Stabil.ai tarafından.
GAN'lar ayrıca uzun süredir çalışılan bu bağlamda, daha az yoğun olmakla birlikte, çok zor insanları ikna edici ve ayrıntılı video tabanlı canlandırmalar için kullanmak; en azından, şimdiye kadar saygıdeğer otomatik kodlayıcı paketleriyle karşılaştırıldığında, örneğin Yüz nakli ve Derin Yüz Laboratuvarı – ve ikincisinin canlı yayın yapan kuzeni, DerinYüzCanlı.
Hareketli Resimler
Her iki durumda da, harekete geçiren faktör, sonraki bir gelişimsel sprint olasılığı gibi görünüyor. video sentez. Ekim ayının başlangıcı - ve 2022'nin ana konferans sezonu - uzun süredir devam eden çeşitli video sentezi hata ayıklarına yönelik ani ve beklenmedik çözümlerin çığı ile karakterize edildi: Facebook'un ortaya çıkmasından hemen sonra. yayınlanan örnekler kendi metinden videoya platformunun ardından Google Research, çıktı alma yeteneğine sahip yeni Imagen-to-Video T2V mimarisini duyurarak bu ilk beğeniyi çabucak bastırdı. yüksek çözünürlüklü görüntüler (Yalnızca 7 katmanlı bir yükseltme ağı aracılığıyla olsa da).
Bu tür şeylerin üçlü olduğuna inanıyorsanız, stable.ai'nin, görünüşe göre bu yılın sonlarında Stable Diffusion'a 'video geliyor' şeklindeki esrarengiz vaadini de göz önünde bulundurun. benzer bir söz verdi, ancak aynı sisteme atıfta bulunup bulunmadıkları belli değil. bu anlaşmazlık mesajı Stability'nin CEO'su Emad Mostaque'tan da söz verildi "ses, video [ve] 3d".
Birkaç yeni birdenbire sunulan teklifle ne olur? ses oluşturma çerçeveleri (bazıları gizli difüzyona dayalıdır) ve yeni bir difüzyon modeli üretebilir. otantik karakter hareketiGAN'lar ve difüzörler gibi 'statik' çerçevelerin sonunda destekleyici olarak yerini alacağı fikri ekler harici animasyon çerçevelerine geçiş gerçek bir çekiş kazanmaya başlıyor.
Kısacası, otomatik kodlayıcı tabanlı video derin sahtekarlıklarının kısıtlı dünyasının, yalnızca etkili bir şekilde alternatif olarak yerini alabileceği görülüyor. bir yüzün orta kısmı, gelecek yıl bu zamanlar, yeni nesil yayılma tabanlı deepfake özellikli teknolojiler tarafından gölgede bırakılabilir - sadece tüm vücutları değil, tüm sahneleri fotogerçekçi olarak taklit etme potansiyeline sahip popüler, açık kaynak yaklaşımlar.
Bu nedenle, belki de anti-deepfake araştırma topluluğu, görüntü sentezini ciddiye almaya başlıyor ve bunun sadece üretmekten daha fazla amaca hizmet edebileceğini fark ediyor. sahte LinkedIn profil fotoğrafları; ve tüm zorlu gizli uzayları zamansal hareket açısından başarabilirse, gerçekten harika bir doku oluşturucu olarak hareket edin, bu aslında fazlasıyla yeterli olabilir.
Blade Runner
Sırasıyla gizli yayılma ve GAN tabanlı derin sahte algılamayı ele alan en son iki makale, sırasıyla, DE-FAKE: Metinden Görüntüye Difüzyon Modelleriyle Oluşturulan Sahte Görüntülerin Tespiti ve İlişkilendirilmesi, CISPA Helmholtz Bilgi Güvenliği Merkezi ve Salesforce arasındaki bir işbirliği; Ve BLADERUNNER: Sentetik (Yapay Zeka Tarafından Oluşturulan) StyleGAN Yüzler için Hızlı Karşı TedbirMIT Lincoln Laboratuvarı'ndan Adam Dorian Wong'dan.
Yeni yöntemi açıklamadan önce, ikinci makalenin bir görüntünün bir GAN tarafından oluşturulup oluşturulmadığını belirlemeye yönelik önceki yaklaşımları incelemesi biraz zaman alıyor (makale özellikle NVIDIA'nın StyleGAN ailesini ele alıyor).
'Brady Bunch' yöntemi – belki de anlamsız referans 1970'lerde TV izlemeyen veya 1990'ların film uyarlamalarını kaçıran herkes için - GAN yüzünün belirli bölümlerinin ezberci ve şablonlu doğası nedeniyle kesinlikle işgal edeceği sabit konumlara dayalı olarak GAN sahte içeriği tanımlar. 'üretim süreci'.

2022'de SANS enstitüsünden bir web yayınıyla öne sürülen 'Brady Bunch' yöntemi: GAN tabanlı bir yüz oluşturucu, belirli durumlarda fotoğrafın kaynağına inanarak belirli yüz özelliklerinin beklenmedik bir şekilde tekdüze yerleşimini gerçekleştirecektir. Kaynak: https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
Bilinen başka bir yararlı gösterge, StyleGAN'ın gerektiğinde birden çok yüzü işleme konusunda sık sık başarısız olması (aşağıdaki ilk görüntü), ayrıca aksesuar koordinasyonunda yetenek eksikliği (aşağıda ortadaki görüntü) ve doğaçlamanın başlangıcı olarak bir ince çizgi kullanma eğilimidir. şapka (aşağıdaki üçüncü resim).

Araştırmacının dikkat çektiği üçüncü yöntem ise fotoğraf bindirme (bir örneği şurada görülebilir. Ağustos makalemiz Birden fazla görüntüyü tek bir görüntüde birleştirmek için CombineZ serisi gibi bileşimsel 'görüntü harmanlama' yazılımını kullanan, genellikle yapıdaki altta yatan ortaklıkları ortaya çıkaran - potansiyel bir sentez göstergesi.

Yeni makalede önerilen mimarinin başlığı (muhtemelen tüm SEO tavsiyelerine aykırıdır) Blade Runner, atıfta bulunarak Voight-Kampff testi bilim kurgu serisindeki düşmanların 'sahte' olup olmadığını belirleyen şey.
İşlem hattı iki aşamadan oluşur; bunlardan ilki, thispersondoesnotexist.com veya oluşturulmuş.fotoğraflar gibi bilinen GAN-face web sitelerinden alınan verileri değerlendirebilen PapersPlease analizcisidir.

Kodun kısaltılmış bir sürümü GitHub'da incelenebilse de (aşağıya bakın), bu modül hakkında OpenCV ve DLIB toplanan malzemedeki yüzleri belirlemek ve tespit etmek için kullanılır.
İkinci modül, Aramızda dedektör. Sistem, yukarıda ayrıntılı olarak açıklanan 'Brady Bunch' senaryosunda örneklenen, StyleGAN'ın yüz çıktısının kalıcı bir özelliği olan fotoğraflarda koordineli göz yerleşimini aramak için tasarlanmıştır. Aramızda, standart bir 68-yer işareti dedektörü tarafından desteklenmektedir.

Blade Runner paketinde yüz yer işareti çizim kodu kullanılan Intelligent Behavior Learning Group (IBUG) aracılığıyla yüz noktası ek açıklamaları.
Aramızda, PapersPlease'den bilinen 'Brady demeti' koordinatlarına dayalı olarak önceden eğitilmiş yer işaretlerine bağlıdır ve StyleGAN tabanlı yüz görüntülerinin canlı, web'e bakan örneklerine karşı kullanılması amaçlanır.
Yazarın öne sürdüğü Blade Runner, burada ele alınan derin sahte algılama türü için şirket içi çözümler geliştirmek için kaynakları olmayan şirketler veya kuruluşlar için tasarlanmış bir tak ve çalıştır çözümü ve "zaman kazanmak için geçici bir önlem". daha kalıcı karşı önlemler'.
Aslında, bu kadar değişken ve hızlı büyüyen bir güvenlik sektöründe, ısmarlama çok fazla or kaynakları yetersiz olan bir şirketin şu anda güvenle başvurabileceği kullanıma hazır bulut sağlayıcı çözümleri.
Blade Runner karşı düşük performans gösterse de gözlüklü StyleGAN-sahte insanlar, bu, benzer durumlarda gizlenen temel referans noktaları olarak göz tasvirlerini değerlendirebilmeyi bekleyen benzer sistemlerde nispeten yaygın bir sorundur.
Blade Runner'ın küçültülmüş bir versiyonu serbest GitHub'da kaynak açmak için. Açık kaynak deposunun işlemi başına tek bir fotoğraf yerine birden çok fotoğrafı işleyebilen, daha zengin özelliklere sahip tescilli bir sürüm mevcuttur. Yazar, zamanın elverdiği ölçüde GitHub sürümünü eninde sonunda aynı standarda yükseltmeyi planladığını söylüyor. Ayrıca, StyleGAN'ın muhtemelen bilinen veya mevcut zayıflıklarının ötesine geçeceğini ve yazılımın da aynı şekilde birlikte gelişmesi gerekeceğini kabul ediyor.
DE-SAHTE
DE-FAKE mimarisi, yalnızca metinden görüntüye difüzyon modelleri tarafından üretilen görüntüler için 'evrensel algılama' elde etmeyi değil, aynı zamanda ayırt etmek için bir yöntem sağlamayı amaçlar. hangi gizli difüzyon (LD) modeli görüntüyü üretti.
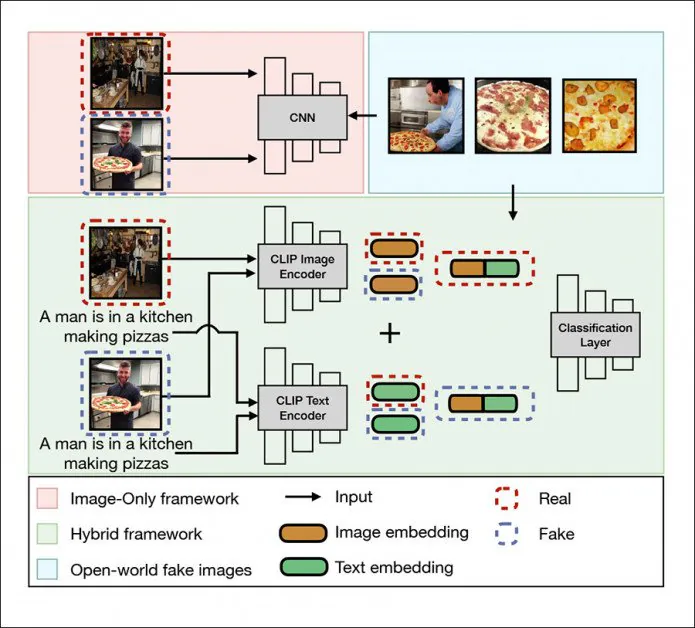
DE-FAKE'deki evrensel algılama çerçevesi, yerel görüntüleri, hibrit bir çerçeveyi (yeşil) ve açık dünya görüntülerini (mavi) ele alır. Kaynak: http://export.arxiv.org/pdf/2210.06998
Dürüst olmak gerekirse, şu anda bu oldukça kolay bir iş çünkü tüm popüler LD modelleri - kapalı veya açık kaynak - dikkate değer ayırt edici özelliklere sahip.
Ek olarak, çoğu, kafa kesmeye yatkınlık gibi bazı ortak zayıflıkları paylaşır. keyfi yol DALL-E 2, Stable Diffusion ve MidJourney gibi sistemlere güç sağlayan devasa veri kümelerine kare olmayan web kazınmış görüntülerin alınması:

Gizli yayılma modelleri, tüm bilgisayarlı görme modellerinde olduğu gibi, kare formatlı girdi gerektirir; ancak LAION5B veri kümesini besleyen toplu web kazıma, yüzleri (veya başka herhangi bir şeyi) tanıma ve bunlara odaklanma yeteneği gibi hiçbir 'lüks ekstra' sunmuyor ve görüntüleri doldurmak yerine oldukça acımasızca kesiyor (bu da kaynağın tamamını koruyacaktır) görüntü, ancak daha düşük çözünürlükte). Bir kez eğitildikten sonra bu 'ürünler' normalleşir ve sıklıkla Stabil Difüzyon gibi gizli difüzyon sistemlerinin çıktısında ortaya çıkar. Kaynaklar: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac ve Kararlı Difüzyon.
DE-FAKE'in algoritmadan bağımsız olması, otomatik kodlayıcı anti-deepfake araştırmacılarının uzun zamandır el üstünde tuttuğu bir hedef olması amaçlanıyor ve şu anda LD sistemleri açısından oldukça ulaşılabilir bir hedef.
Mimari, OpenAI'nin Karşıt Dil-Görüntü Ön Eğitimini kullanır (CLIP) çok modlu kitaplık - 'sahte' LD görüntülerinden gömmeler çıkarmanın ve gözlemlenen modeller ve sınıflar üzerinde bir sınıflandırıcı eğitmenin bir yolu olarak, Stable Difüzyon'da önemli bir öğe ve hızla yeni görüntü/video sentez sistemleri dalgasının kalbi haline geliyor.
Oluşturma süreci hakkında bilgi tutan PNG parçalarının, yükleme işlemleri ve başka nedenlerle uzun süredir ortadan kaldırıldığı daha "kara kutu" senaryosunda, araştırmacılar Salesforce'u kullanıyor BLIP çerçevesi (ayrıca bir bileşen en az bir Dağılımı) görüntüleri, onları oluşturan bilgi istemlerinin olası anlamsal yapısı için 'körü körüne' yoklamak için.

Araştırmacılar, MSCOCO ve Flickr2k'den yararlanan bir eğitim ve test veri kümesi oluşturmak için Stable Diffusion, Latent Diffusion (kendisi ayrı bir ürün), GLIDE ve DALL-E 30'yi kullandı.
Normalde, yeni bir çerçeve için araştırmacıların deneylerinin sonuçlarına oldukça kapsamlı bir şekilde bakardık; ancak gerçekte, DE-FAKE'nin bulguları, içinde faaliyet gösterdiği değişken ortam ve sahip olduğu sistem dikkate alındığında, proje başarısının anlamlı bir ölçüsü olmaktan ziyade, daha sonraki yinelemeler ve benzer projeler için gelecekteki bir kıyaslama noktası olarak daha yararlı görünmektedir. gazetenin denemelerinde rekabet ediyor, neredeyse üç yaşında - görüntü sentezi sahnesinin gerçekten yeni ortaya çıktığı zamandan beri.

En soldaki iki resim: 2019'da ortaya çıkan, test edilen dört LD sisteminde DE-FAKE'e (en sağdaki iki resim) karşı tahmin edilebileceği gibi daha az başarılı olan "zorlu" önceki çerçeve.
Ekibin sonuçları iki nedenden dolayı ezici bir çoğunlukla olumlu: karşılaştırabileceğimiz çok az önceki çalışma var (ve hiçbiri adil bir karşılaştırma sunmuyor, yani Stable Diffusion'ın açık kaynak olarak piyasaya sürülmesinden bu yana yalnızca on iki haftayı kapsıyor).
İkinci olarak, yukarıda bahsedildiği gibi, LD görüntü sentezi alanı üstel bir hızla gelişiyor olsa da, mevcut tekliflerin çıktı içeriği, kendi yapısal (ve oldukça öngörülebilir) eksiklikleri ve tuhaflıkları nedeniyle (çoğu muhtemelen düzeltilecek) etkili bir şekilde filigran haline geliyor. en azından Kararlı Yayılma durumunda, daha iyi performans gösteren 1.5 kontrol noktasının (yani sisteme güç sağlayan 4 GB eğitimli model) piyasaya sürülmesiyle.
Aynı zamanda Stability, sistemin V2 ve V3 için net bir yol haritasına sahip olduğunu zaten belirtmişti. Son üç ayın manşetlere konu olan olayları göz önüne alındığında, OpenAI ve görüntü sentezi alanındaki diğer rakip oyuncuların herhangi bir kurumsal uyuşukluğu muhtemelen ortadan kalkmış olacak, bu da benzer şekilde hızlı bir ilerleme hızı bekleyebileceğimiz anlamına geliyor. kapalı kaynak görüntü sentezi alanı.
İlk olarak 14 Ekim 2022'de yayınlandı.















