Yapay Zekâ
AudioSep : Tanımladığınız Her Şeyi Ayırın
LASS veya Dil-Sorgulanan Ses Kaynağı Ayrımı, CASA veya Hesaplamalı İşitsel Sahne Analizi için yeni bir paradigmadır ve doğal bir dilsel sorgu kullanarak bir ses karışımından bir hedef sesi ayırmayı amaçlar. Bu, dijital ses görevleri ve uygulamaları için doğal ve ölçeklenebilir bir arayüze sahiptir.尽管 LASS çerçeveleri, son birkaç yılda müzik aletleri gibi belirli ses kaynaklarında istenen performansı elde etme konusunda önemli ölçüde ilerlemiştir, ancak açık alanda hedef sesi ayıramazlar.
AudioSep, LASS çerçevelerinin hiện geçerli sınırlamalarını doğal dilsel sorgular kullanarak hedef ses ayırma yoluyla çözmeyi amaçlayan bir temel modeldir. AudioSep çerçevesinin geliştiricileri, modeli geniş bir büyük ölçekli çok modelli veri setlerinde kapsamlı bir şekilde eğittiler ve müzik aleti ayırma, ses olayı ayırma ve konuşma artırma dahil olmak üzere çeşitli ses görevlerinde çerçevenin performansını değerlendirdiler. AudioSep’in ilk performansı, etkileyici sıfır-ateş öğrenme yetenekleri sergileyerek ve güçlü ses ayırma performansı sağlayarak ölçütleri karşılar.
Bu makalede, AudioSep çerçevesinin çalışmasına daha derinlemesine bakacağız, modelin mimarisini, eğitim ve değerlendirme için kullanılan veri setlerini ve AudioSep modelinin çalışmasıyla ilgili temel kavramları değerlendireceğiz. Böylece, CASA çerçevesine temel bir giriş ile başlayalım.
CASA, USS, QSS, LASS Çerçeveleri : AudioSep için Temel
CASA veya Hesaplamalı İşitsel Sahne Analizi çerçevesi, geliştiricilerin insan işitsel sistemleri gibi karmaşık ses ortamlarını algılayabilen makine dinleme sistemleri tasarlamalarına olanak tanıyan bir çerçevedir. Ses ayırma, özellikle hedef ses ayırma, CASA çerçevesi içinde temel bir araştırma alanıdır ve “kokteyl partisi problemi”ni veya bireysel ses kaynak kayıtlarından veya dosyalarından gerçek dünya ses kayıtlarını ayırmayı çözmeyi amaçlar. Ses ayırmanın önemi, müzik kaynak ayırma, ses kaynağı ayırma, konuşma artırma, hedef ses tanımlama ve daha fazlası dahil olmak üzere yaygın uygulamalarına chủ olarak atfedilebilir.
Geçmişte yapılan ses ayırma çalışmalarının çoğu, müzik ayırma veya konuşma ayırma gibi bir veya daha fazla ses kaynağını ayırmaya odaklanmıştır. USS veya Evrensel Ses Ayırma adlı yeni bir model, gerçek dünya ses kayıtlarında keyfi sesleri ayırmayı amaçlar. Ancak, dünyanın içinde var olan çok çeşitli farklı ses kaynakları nedeniyle, bir ses karışımından her ses kaynağını ayırmak zor ve kısıtlayıcı bir görevdir, bu nedenle USS yöntemi gerçek zamanlı çalışan gerçek dünya uygulamaları için uygulanabilir değildir.
USS yönteminin uygulanabilir bir alternatifi, QSS veya Sorgu Tabanlı Ses Ayırma yöntemidir ve bir ses karışımından bir hedef ses kaynağını, belirli bir sorgu kümesine dayanarak ayırmayı amaçlar. Bu, QSS çerçevesinin, kullanıcıların karışımından istedikleri ses kaynaklarını çıkarmalarına olanak tanıyan daha pratik bir çözüm olmasını sağlar.
Daha da önemlisi, geliştiriciler yakın zamanda QSS çerçevesinin bir uzantısı olan LASS veya Dil-Sorgulanan Ses Kaynağı Ayrımı çerçevesini önerdiler ve bu, hedef ses kaynağını doğal dilsel açıklamaları kullanarak bir ses karışımından ayırmayı amaçlar. LASS çerçevesi, kullanıcıların hedef ses kaynaklarını doğal dilsel talimatlar kullanarak çıkarmalarına olanak tanır, bu da dijital ses uygulamalarında geniş bir uygulama yelpazesi sunabilir. Geleneksel ses-sorgulanan veya görme-sorgulanan yöntemlerle karşılaştırıldığında, ses ayırma için doğal dilsel talimatlar kullanmak, esneklik ekler ve sorgu bilgisinin edinilmesini daha kolay ve uygun hale getirir. Ayrıca, önceden tanımlanmış bir dizi talimat veya sorgu kullanan etiket-sorgulanan ses ayırma çerçeveleriyle karşılaştırıldığında, LASS çerçevesi, girişteki sorgu sayısını sınırlamaz ve açık alanlara sorunsuz bir şekilde genelleştirilebilir.
Öncelikle, LASS çerçevesi, etiketli ses-metin eşleştirilmiş veri setlerinde denetimli öğrenimi kullanır. Ancak, bu yaklaşımın temel sorunu, etiketli ve işaretli ses-metin veri setlerinin sınırlı Verfügibilitidir. LASS çerçevesinin, etiketli ses-metin etiketli veri setlerine bağımlılığını azaltmak için, multimodal denetimli öğrenme yaklaşımı kullanılır. Multimodal denetimli öğrenme yaklaşımının temel amacı, CLIP veya Karşıt Dil-Görüntü Ön Eğitim modeli gibi multimodal karşıt öğrenme önceden eğitimli modellerini çerçeveye sorgu kodlayıcı olarak kullanmaktır. CLIP çerçevesi, metin gömme ile diğer modalleri seperti ses veya görüntüyü hizalayabilme yeteneğine sahiptir, bu da geliştiricilerin, veri zengin modallerini kullanarak LASS modellerini eğitmelerine ve sıfır-ateş ayarında metinsel verilerle etkileşime girmelerine olanak tanır. Mevcut LASS çerçeveleri, eğitim için küçük ölçekli veri setlerini kullanır ve LASS çerçevesinin yüzlerce potansiyel alanda uygulamaları henüz keşfedilmemiştir.
LASS çerçevelerinin mevcut sınırlamalarını çözmek için, geliştiriciler AudioSep’i, doğal dilsel açıklamaları kullanarak bir ses karışımından ses ayırmayı amaçlayan bir temel modeli tanıttılar. AudioSep’in hiện odak noktası, mevcut büyük ölçekli multimodal veri setlerini kullanarak LASS modellerinin açık alan uygulamalarında genelleştirilmesini sağlayan bir önceden eğitilmiş ses ayırma modeli geliştirmektir. Özetle, AudioSep modeli: “Açık alan универсал ses ayırma için doğal dilsel sorgular veya açıklamalarla eğitilmiş büyük ölçekli ses ve multimodal veri setleri için temel modeldir”.
AudioSep : Ana Bileşenler ve Mimarisi
AudioSep çerçevesinin mimarisi, iki ana bileşenden oluşur: bir metin kodlayıcı ve bir ayırma modeli.
Metin Kodlayıcı
AudioSep çerçevesi, bir doğal dilsel sorgudan metin gömme çıkarmak için CLIP veya Karşıt Dil-Görüntü Ön Eğitim modeli veya CLAP veya Karşıt Dil-Ses Ön Eğitim modeli metin kodlayıcısını kullanır. Giriş metin sorgusu, “N” token dizisi olarak oluşur ve metin kodlayıcı tarafından işlenerek, verilen giriş dilsel sorgu için metin gömme oluşturulur. Metin kodlayıcı, metin girişi tokenlerini kodlamak için bir dönüşümsel bloklar yığını kullanır ve çıktı temsilleri, dönüşümsel katmanlardan geçirildikten sonra agreglanır, bu da D-boyutlu bir vektör temsilinin geliştirilmesine yol açar, burada D, CLAP veya CLIP modellerinin boyutlarını temsil eder, metin kodlayıcı eğitim süresi boyunca dondurulur.
CLIP modeli, karşıt öğrenme kullanarak büyük ölçekli bir görüntü-metin eşleştirilmiş veri setinde önceden eğitilmiştir, bu nedenle metin kodlayıcı, metinsel açıklamaları paylaşılan bir anlamsal alanda görsel temsillerle eşleştirmeyi öğrenir. AudioSep’in CLIP’in metin kodlayıcısını kullanmasının avantajı, LASS modelini, görsel gömme olarak kullanılabilecek bir alternatif olarak, etiketlenmemiş veya işaretsiz ses-görüntü veri setlerinden eğitebilmesidir.
CLAP modeli, CLIP modeline benzer şekilde çalışır ve karşıt öğrenme hedefini kullanır, bir metin ve bir ses kodlayıcısını kullanarak ses ve dil arasında bir bağlantı kurar, bu da metin ve ses açıklamalarını birleşik bir ses-metin gizli alanda birleştirir.
Ayrılma Modeli
AudioSep çerçevesi, bir ayırma omurgası olarak frekans-alanında ResUNet modelini kullanır ve bir dizi ses kliplerinin karışımını girişe uygular. Çerçeve, önce bir Hann penceresi kullanarak dalga formundan karmaşık bir spektrogram çıkarmaya başlar, pencere boyutu 1024 ve atlama boyutu 320’dir.
Model daha sonra, bir kodlayıcı-dekodlayıcı ağını, büyüklük spektrumunu işlemek için oluşturur. ResUNet kodlayıcı-dekodlayıcı ağı, 6 kodlayıcı bloğu, 6 dekodlayıcı bloğu ve 4 boğaz bloğu içerir. Her kodlayıcı bloğu, 4 artımlı geleneksel bloğu kullanarak spektrumunu bir boğaz özelliğine örnekler, dekodlayıcı blokları ise 4 artımlı konvolüsyonel blokları kullanarak, özelliklerini örnekleyerek ayırma bileşenlerini elde eder. Her kodlayıcı ve dekodlayıcı bloğu, aynı örnek alma veya örnek azaltma oranında çalışan bir atlayış bağlantısı oluşturur. Residual bloğu, 2 sızıntılı ReLU aktivasyon katmanı, 2 toplu normalleştirme katmanı ve 2 CNN katmanı içerir ve ayrıca her bir artımlı bloğun girişi ve çıkışı arasında ek bir artımlı kısayol tanır. ResUNet modeli, karmaşık spektrum X’i girişe uygular ve büyüklük maskesi M’yi çıkışı olarak üretir, faz artığı metin gömme ile koşullandırılır ve spektrumun büyüklüğünü ve açısını kontrol eder. Ayırılan karmaşık spektrum, öngörülen büyüklük maskesi ve faz artığının STFT’si ile çarpılmasıyla elde edilebilir.

AudioSep, ayırma modeli ve metin kodlayıcı arasında, ResUNet’in konvolüsyonel bloklarının dağıtımından sonra bir FiLm veya Özellik-Özgün Doğrusal Modülasyon katmanı kullanır.
Eğitim ve Kayıp
AudioSep modelinin eğitimi sırasında, geliştiriciler yükseklik artırma yöntemini kullanır ve AudioSep çerçevesini, gerçek ve öngörülen dalga formları arasındaki L1 kaybı fonksiyonu kullanarak uçtan uca eğitiyor.
Veri Setleri ve Ölçütler
Önceki bölümlerde bahsedildiği gibi, AudioSep, LASS modellerinin etiketli ses-metin eşleştirilmiş veri setlerine bağımlılığını çözmeyi amaçlayan bir temel modeldir. AudioSep modeli, multimodal öğrenme yetenekleri kazanmak için geniş bir veri seti yelpazesi üzerinde eğitilir ve burada AudioSep çerçevesini eğitmek ve değerlendirmek için kullanılan veri setleri ve ölçütlerin ayrıntılı bir açıklaması sunulacaktır.
AudioSet
AudioSet, YouTube’dan doğrudan alınan 2 milyondan fazla 10 saniyelik ses parçacıklarından oluşan büyük ölçekli bir ses veri setidir. AudioSet veri setindeki her bir ses parçacığı, ses sınıflarının varlığı veya yokluğu tarafından kategorilere ayrılmıştır, ancak ses olaylarının zamanlama ayrıntıları yoktur. AudioSet veri seti, doğal sesler, insan sesleri, araç sesleri ve daha fazlası dahil olmak üzere 500’den fazla farklı ses sınıfı içerir.
VGGSound
VGGSound veri seti, YouTube’dan alınan büyük ölçekli bir görsel-ses veri setidir ve 10 saniye uzunluğunda 200.000’den fazla video kliplerini içerir. VGGSound veri seti, insan sesleri, doğal sesler, kuş sesleri ve daha fazlası dahil olmak üzere 300’den fazla ses sınıfına ayrılmıştır. VGGSound veri setinin kullanılması, hedef sesi üreten nesnenin de ilgili görsel klipte tanımlanabilir olmasını sağlar.
AudioCaps
AudioCaps, halka açık olarak kullanılabilen en büyük ses açıklama veri setidir ve AudioSet veri setinden alınan 10 saniyelik 50.000’den fazla ses parçacıklarından oluşur. AudioCaps veri seti, eğitim verileri, test verileri ve doğrulama verileri olmak üzere üç kategoriye ayrılmıştır ve ses parçacıkları, Amazon Mechanical Turk platformu kullanılarak doğal dilsel açıklamalarla insan tarafından etiketlenmiştir. Eğitim veri setindeki her bir ses parçacığı tek bir açıklamaya sahiptir, test ve doğrulama veri setlerindeki her bir ses parçacığı ise 5 adet gerçek açıklamaya sahiptir.
ClothoV2
ClothoV2, FreeSound platformundan alınan ses parçacıklarından oluşan bir ses açıklama veri setidir ve AudioCaps gibi, her bir ses parçacığı, Amazon Mechanical Turk platformu kullanılarak doğal dilsel açıklamalarla insan tarafından etiketlenmiştir.
WavCaps
WavCaps, AudioSet gibi, 400.000’den fazla ses parçacığından oluşan büyük ölçekli bir ses veri setidir ve yaklaşık 7568 saatlik eğitim verisi içerir. WavCaps veri setindeki ses parçacıkları, BBC Sound Effects, AudioSet, FreeSound, SoundBible ve daha fazlası dahil olmak üzere çeşitli ses kaynaklarından alınmıştır.

Eğitim Ayrıntıları
Eğitim aşamasında, AudioSep modeli, eğitim veri setinden iki farklı ses parçacığını rastgele örnekler ve bunları birleştirerek bir eğitim karışımı oluşturur, her bir ses parçacığının uzunluğu yaklaşık 5 saniyedir. Model daha sonra, Hann penceresi kullanarak dalga formundan karmaşık bir spektrum çıkarmaya başlar, pencere boyutu 1024 ve atlama boyutu 320’dir.
Model daha sonra, metin kodlayıcısı olarak CLIP/CLAP modellerinin metin kodlayıcısını kullanarak metinsel gömme çıkarmak için metin denetimi olarak yapılandırılır. Ayırma modeli için, AudioSep çerçevesi, 30 katman, 6 kodlayıcı bloğu ve 6 dekodlayıcı bloğu içeren bir ResUNet katmanını kullanır, bu da evrensel ses ayırma çerçevesindeki mimariyi takip eder. Ayrıca, her bir kodlayıcı bloğu, 3×3 çekirdek boyutuna sahip iki konvolüsyonel katman içerir ve kodlayıcı bloklarının çıkış özelliklerinin sayısı sırasıyla 32, 64, 128, 256, 512 ve 1024’dir. Dekodlayıcı blokları, kodlayıcı bloklarıyla simetriktir ve geliştiriciler, AudioSep modelini, 96’lık bir toplu boyutu ile Adam optimizatörü kullanarak eğitiyor.
Değerlendirme Sonuçları
Görülen Veri Setlerinde
Aşağıdaki şekil, AudioSep çerçevesinin, eğitim aşamasında görülen veri setlerinde, eğitim veri setleri dahil, performansı karşılaştırır. Aşağıdaki şekil, AudioSep çerçevesinin, Speech Enhancement modelleri, LASS ve CLIP dahil olmak üzere temel sistemlerle karşılaştırıldığında ölçüt değerlendirme sonuçlarını gösterir. CLIP metin kodlayıcısı ile AudioSep modeli, AudioSep-CLIP olarak temsil edilirken, CLAP metin kodlayıcısı ile AudioSep modeli, AudioSep-CLAP olarak temsil edilir.

Şekilden de görülebileceği gibi, AudioSep çerçevesi, ses açıklamaları veya metin etiketleri kullanılarak girdi sorguları olarak iyi performans gösterir ve sonuçlar, AudioSep çerçevesinin önceki benchmark LASS ve ses-sorgulanan ses ayırma modellerine kıyasla üstün performansını gösterir.
Görülmemiş Veri Setlerinde
AudioSep’in sıfır-ateş ayarında performansını değerlendirmek için, geliştiriciler ayrıca görülmemiş veri setlerinde performansını değerlendirdiler ve AudioSep çerçevesi, sıfır-ateş ayarında etkileyici bir ayırma performansı sergiler ve sonuçlar aşağıdaki şekildedir.

Ayrıca, aşağıdaki şekil, AudioSep modelinin Voicebank-Demand konuşma artırma karşılaştırmalı sonuçlarını gösterir.

AudioSep çerçevesinin değerlendirilmesi, görülmemiş veri setlerinde sıfır-ateş ayarında güçlü ve istenen bir performans sergilediğini gösterir ve bu da yeni veri dağılımlarında ses işlem görevlerinin gerçekleştirilmesine olanak tanır.
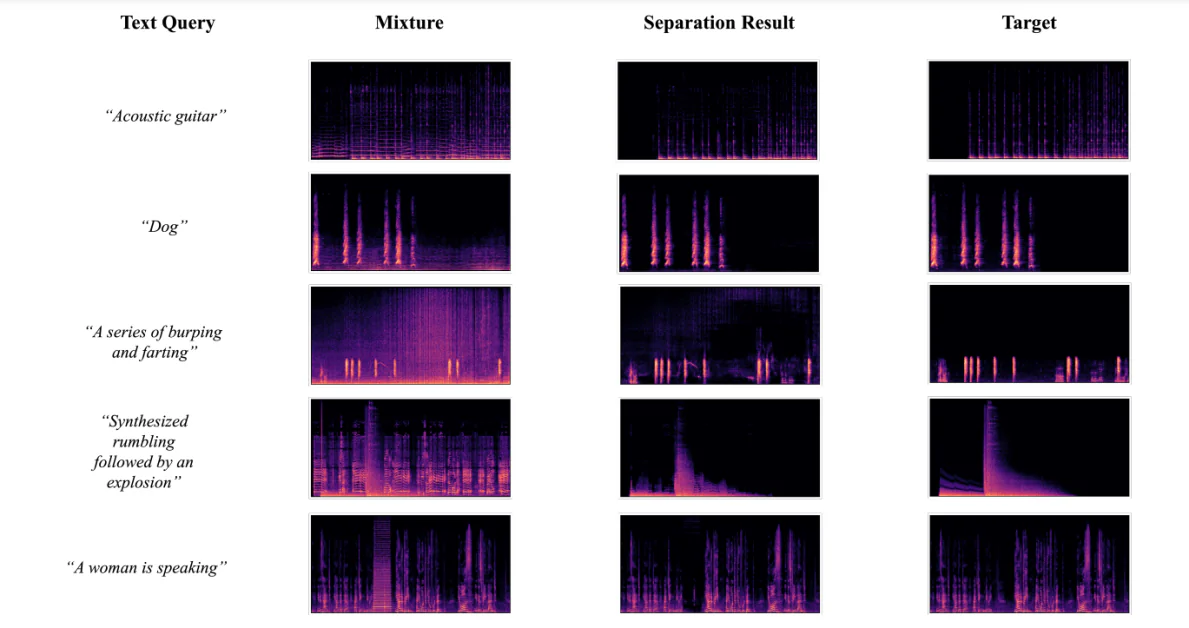
Ayrılma Sonuçlarının Görselleştirilmesi
Aşağıdaki şekil, geliştiricilerin AudioSep-CLAP çerçevesini kullanarak, çeşitli sesler veya sesler için metin sorguları ile hedef ses kaynakları, ses karışımı ve ayrılmış ses kaynakları için spektrogramların görselleştirilmesiyle elde edilen sonuçları gösterir. Sonuçlar, ayrılmış ses kaynağının spektrum deseninin gerçek kaynakla benzer olduğunu gözlemlemeye olanak tanır, bu da deneylerde elde edilen nesnel sonuçları destekler.
Metin Sorgularının Karşılaştırılması
Geliştiriciler, AudioCaps Mini’de AudioSep-CLAP ve AudioSep-CLIP’in performansını değerlendirir ve AudioSet olay etiketleri, AudioCaps açıklamaları ve yeniden etiketlenmiş doğal dilsel açıklamaları kullanarak farklı sorguların etkilerini inceler ve aşağıdaki şekil, AudioCaps Mini’nin bir örneğini gösterir.

SONUÇ
AudioSep, doğal dilsel açıklamaları kullanarak ses ayırma için açık alan evrensel ses ayırma çerçevesi olarak geliştirilen bir temel modeldir. Değerlendirme sonuçları, AudioSep çerçevesinin, ses açıklamaları veya metin etiketleri kullanılarak girdi sorguları olarak sıfır-ateş ve denetimsiz öğrenme yapabilme yeteneğine sahip olduğunu gösterir ve sonuçlar, AudioSep çerçevesinin mevcut durumun en iyi LASS ve ses-sorgulanan ses ayırma çerçevelerine kıyasla güçlü bir performans sergilediğini gösterir. Bu, popüler ses ayırma çerçevelerinin mevcut sınırlamalarını çözmeye yeterli olabileceğini gösterir.












