
มุมมองของแอนเดอร์สัน
วิธีการตรวจสอบข้อมูลนิติเวชสำหรับ Deepfakes รุ่นใหม่

แม้ว่าการปลอมแปลงบุคคลธรรมดาจะกลายเป็นเรื่อง ความกังวลของสาธารณชนเพิ่มมากขึ้น และกำลังเพิ่มมากขึ้น กรรม ในภูมิภาคต่างๆ การพิสูจน์ว่าโมเดลที่ผู้ใช้สร้างขึ้น เช่น โมเดลเพื่อการแก้แค้นแบบลามก ได้รับการฝึกฝนมาจากรูปภาพของบุคคลใดบุคคลหนึ่งโดยเฉพาะ ยังคงเป็นความท้าทายอย่างยิ่ง
หากจะกล่าวถึงปัญหาในบริบทนี้ องค์ประกอบสำคัญของการโจมตีด้วย Deepfake คือการกล่าวอ้างอย่างเท็จว่ารูปภาพหรือวิดีโอนั้นแสดงถึงบุคคลใดบุคคลหนึ่ง การกล่าวเพียงว่าบุคคลในวิดีโอนั้นเป็นตัวตน #A แทนที่จะเป็นเพียงคนหน้าตาเหมือนเท่านั้น เพียงพอที่จะก่อให้เกิดอันตรายได้และไม่จำเป็นต้องใช้ AI ในสถานการณ์นี้
อย่างไรก็ตาม หากผู้โจมตีสร้างภาพหรือวิดีโอด้วย AI โดยใช้โมเดลที่ฝึกมาจากข้อมูลของบุคคลจริง ระบบจดจำใบหน้าของโซเชียลมีเดียและเครื่องมือค้นหาจะเชื่อมโยงเนื้อหาปลอมกับเหยื่อโดยอัตโนมัติ โดยไม่ต้องระบุชื่อในโพสต์หรือข้อมูลเมตา ภาพที่สร้างโดย AI เพียงอย่างเดียวก็รับประกันการเชื่อมโยงได้แล้ว
ยิ่งบุคคลมีรูปลักษณ์ที่โดดเด่นมากเท่าไร ก็ยิ่งหลีกเลี่ยงไม่ได้มากขึ้นเท่านั้น จนกระทั่งเนื้อหาที่แต่งขึ้นปรากฏในผลการค้นหารูปภาพและในที่สุด ไปถึงเหยื่อแล้ว.
หันหน้าเข้าหากัน
วิธีการที่ใช้กันมากที่สุดในการเผยแพร่โมเดลที่เน้นเรื่องตัวตนในปัจจุบันคือผ่าน การปรับตัวระดับต่ำ (LoRA) โดยที่ผู้ใช้จะฝึกภาพจำนวนเล็กน้อยเป็นเวลาไม่กี่ชั่วโมงเทียบกับน้ำหนักของแบบจำลองพื้นฐานที่ใหญ่กว่ามาก เช่น การแพร่กระจายที่เสถียร (สำหรับภาพนิ่งเป็นส่วนใหญ่) หรือ วิดีโอฮันหยวนสำหรับวิดีโอแบบ Deepfake
ที่พบมากที่สุด เป้าหมาย ของ LoRA รวมถึง สายพันธุ์ใหม่ ของ LoRA ที่ใช้พื้นฐานวิดีโอนั้น เป็นผู้หญิงที่มีชื่อเสียง ซึ่งชื่อเสียงของพวกเธอทำให้พวกเธอถูกปฏิบัติเช่นนี้โดยได้รับการวิพากษ์วิจารณ์จากสาธารณชนน้อยกว่าในกรณีของเหยื่อที่ 'ไม่เป็นที่รู้จัก' เนื่องจากถือว่าผลงานลอกเลียนแบบดังกล่าวได้รับการคุ้มครองภายใต้ 'การใช้งานโดยชอบ' (อย่างน้อยก็ในสหรัฐอเมริกาและยุโรป)

ดาราสาวครองรายชื่อ LoRA และ Dreambooth บนพอร์ทัล civit.ai ปัจจุบัน LoRA ที่ได้รับความนิยมสูงสุดมียอดดาวน์โหลดมากกว่า 66,000 ครั้ง ซึ่งถือว่ามาก เนื่องจากการใช้ AI ในลักษณะนี้ยังคงถูกมองว่าเป็นกิจกรรม "นอกกระแส"
ไม่มีเวทีสาธารณะดังกล่าวสำหรับเหยื่อของการทำดีปเฟกที่ไม่ได้เป็นคนดัง ซึ่งจะปรากฏตัวในสื่อเฉพาะเมื่อมีการดำเนินคดี หรือเมื่อมีเหยื่อออกมาพูดในสื่อยอดนิยมเท่านั้น
อย่างไรก็ตาม ในทั้งสองสถานการณ์ โมเดลที่ใช้ปลอมแปลงตัวตนเป้าหมายได้ "กลั่น" ข้อมูลการฝึกอบรมจนหมดสิ้นลงใน พื้นที่แฝง ของแบบจำลองที่ทำให้ยากที่จะระบุภาพต้นฉบับที่นำมาใช้
ถ้ามัน คือ เป็นไปได้ที่จะทำเช่นนั้นภายในขอบเขตข้อผิดพลาดที่ยอมรับได้ ซึ่งจะทำให้สามารถดำเนินคดีกับผู้ที่แบ่งปัน LoRA ได้ เนื่องจากการทำเช่นนี้ไม่เพียงพิสูจน์เจตนาในการปลอมแปลงตัวตนอย่างลึกซึ้ง (เช่น ตัวตนของบุคคลที่ 'ไม่เปิดเผย' แม้ว่าผู้กระทำความผิดจะไม่เคยระบุชื่อบุคคลดังกล่าวระหว่างกระบวนการหมิ่นประมาทก็ตาม) แต่ยังทำให้ผู้ที่อัปโหลดต้องเผชิญกับข้อกล่าวหาละเมิดลิขสิทธิ์อีกด้วย (ถ้ามี)
อย่างหลังนี้จะมีประโยชน์ในเขตอำนาจศาลที่การบังคับใช้กฎหมายเกี่ยวกับเทคโนโลยี deepfaking ยังขาดหรือล่าช้าอยู่
การเปิดรับแสงมากเกินไป
วัตถุประสงค์ของการฝึกโมเดลพื้นฐาน เช่น โมเดลพื้นฐานหลายกิกะไบต์ที่ผู้ใช้สามารถดาวน์โหลดจาก Hugging Face ก็คือเพื่อให้โมเดลนั้นทำงานได้ดีทั่วไปและยืดหยุ่นได้ ซึ่งเกี่ยวข้องกับการฝึกอบรมในจำนวนภาพที่หลากหลายเพียงพอ และด้วยการตั้งค่าที่เหมาะสม และการสิ้นสุดการฝึกอบรมก่อนที่แบบจำลองจะ "โอเวอร์ฟิต" กับข้อมูล
An โมเดลโอเวอร์ฟิต ได้พบข้อมูลซ้ำๆ กันหลายครั้ง (มากเกินไป) ในระหว่างกระบวนการฝึกอบรม ซึ่งมีแนวโน้มที่จะสร้างภาพที่มีความคล้ายคลึงกันมากเกินไป จึงเปิดเผยแหล่งที่มาของข้อมูลฝึกอบรม

ตัวตนของ 'Ann Graham Lotz' สามารถจำลองได้เกือบสมบูรณ์แบบในโมเดล Stable Diffusion V1.5 การสร้างใหม่เกือบจะเหมือนกับข้อมูลการฝึกอบรมทุกประการ (ด้านซ้ายในภาพด้านบน) แหล่งที่มา: https://arxiv.org/pdf/2301.13188
อย่างไรก็ตาม ผู้สร้างมักจะทิ้งโมเดลที่ปรับให้พอดีเกินไปแทนที่จะแจกจ่าย เนื่องจากโมเดลเหล่านี้ไม่เหมาะสมกับวัตถุประสงค์อยู่แล้ว ดังนั้น นี่จึงถือเป็น "รายได้ก้อนโต" ทางนิติเวชที่ไม่น่าจะเกิดขึ้นได้ ในทุกกรณี หลักการนี้ใช้ได้กับการฝึกโมเดลพื้นฐานที่มีราคาแพงและมีปริมาณมากมากกว่า ซึ่ง หลายรุ่น ของรูปภาพเดียวกันที่แทรกเข้าไปในชุดข้อมูลต้นทางขนาดใหญ่อาจทำให้สามารถเรียกใช้รูปภาพสำหรับฝึกอบรมบางภาพได้ง่าย (ดูรูปภาพและตัวอย่างด้านบน)
สิ่งต่าง ๆ แตกต่างกันเล็กน้อยในกรณีของโมเดล LoRA และ Dreambooth (แม้ว่า Dreambooth จะไม่เป็นที่นิยมอีกต่อไปเนื่องจากขนาดไฟล์ที่ใหญ่) ในกรณีนี้ ผู้ใช้จะเลือกภาพที่หลากหลายของวัตถุในจำนวนจำกัด และใช้ภาพเหล่านี้ในการฝึก LoRA

ทางด้านซ้ายเป็นเอาต์พุตจาก Hunyuan Video LoRA ทางด้านขวาเป็นข้อมูลที่ทำให้สามารถเปรียบเทียบได้ (ใช้รูปภาพโดยได้รับอนุญาตจากบุคคลที่ปรากฎในภาพ)
บ่อยครั้ง LoRA จะมีคำทริกเกอร์ที่ผ่านการฝึกมา เช่น [ชื่อคนดัง]อย่างไรก็ตาม บ่อยครั้งที่วิชาที่ได้รับการฝึกอบรมโดยเฉพาะจะปรากฏในผลลัพธ์ที่สร้างขึ้น แม้จะไม่มีคำกระตุ้นดังกล่าวเนื่องจากแม้แต่ LoRA ที่มีความสมดุลดี (กล่าวคือ ไม่เกินพอดี) ก็ยัง "มุ่งเน้น" อยู่กับเนื้อหาที่ใช้ฝึกอบรมอยู่บ้าง และมักจะรวมเนื้อหานั้นไว้ในผลลัพธ์ใดๆ
แนวโน้มนี้ เมื่อรวมเข้ากับจำนวนภาพจำกัดซึ่งเหมาะสมที่สุดสำหรับชุดข้อมูล LoRA จะเปิดเผยโมเดลต่อการวิเคราะห์นิติเวช ดังที่เราจะเห็นต่อไป
การเปิดเผยข้อมูล
เรื่องเหล่านี้ได้รับการกล่าวถึงในเอกสารใหม่จากเดนมาร์ก ซึ่งเสนอวิธีการในการระบุภาพต้นฉบับ (หรือกลุ่มของภาพต้นฉบับ) ในกล่องดำ การโจมตีอนุมานความเป็นสมาชิก (MIA) เทคนิคนี้เกี่ยวข้องกับการใช้โมเดลที่ผ่านการฝึกอบรมมาโดยเฉพาะ ซึ่งออกแบบมาเพื่อช่วยเปิดเผยข้อมูลต้นทางโดยการสร้าง "ดีปเฟก" ของตัวเอง:

ตัวอย่างภาพ 'ปลอม' ที่สร้างขึ้นโดยวิธีการใหม่ โดยเพิ่มระดับของ Classifier-Free Guidance (CFG) ขึ้นเรื่อยๆ จนถึงจุดทำลาย แหล่งที่มา: https://arxiv.org/pdf/2502.11619
แม้ว่า งาน, ชื่อ การโจมตีการอนุมานความเป็นสมาชิกสำหรับภาพใบหน้าต่อโมเดลการแพร่กระจายแฝงที่ปรับแต่งอย่างละเอียดถือเป็นผลงานที่น่าสนใจอย่างยิ่งในวรรณกรรมเกี่ยวกับหัวข้อนี้โดยเฉพาะ นอกจากนี้ยังเป็นเอกสารที่เข้าถึงได้ยากและเขียนได้กระชับและต้องการการถอดรหัสอย่างมาก ดังนั้น เราจะครอบคลุมอย่างน้อยหลักการพื้นฐานเบื้องหลังโครงการนี้ที่นี่ และตัวอย่างผลลัพธ์ที่ได้
ในความเป็นจริง หากมีใครสักคนปรับแต่งโมเดล AI บนใบหน้าของคุณ วิธีการของผู้เขียนสามารถช่วยพิสูจน์ได้ด้วยการมองหาสัญญาณที่บ่งบอกถึงการจดจำในภาพที่โมเดลสร้างขึ้น
ในกรณีแรก โมเดล AI เป้าหมายจะถูกปรับแต่งบนชุดข้อมูลของภาพใบหน้า ทำให้มีแนวโน้มที่จะสร้างรายละเอียดจากภาพเหล่านั้นในผลลัพธ์ได้มากขึ้น ต่อมา โหมดการโจมตีของตัวจำแนกประเภทจะได้รับการฝึกโดยใช้ภาพที่สร้างโดย AI จากโมเดลเป้าหมายเป็น "ภาพบวก" (สมาชิกที่คาดว่าจะเป็นของชุดการฝึก) และภาพอื่นๆ จากชุดข้อมูลอื่นเป็น "ภาพลบ" (ไม่ใช่สมาชิก)
การเรียนรู้ความแตกต่างที่ละเอียดอ่อนระหว่างกลุ่มเหล่านี้ทำให้โมเดลการโจมตีสามารถคาดการณ์ได้ว่ารูปภาพที่กำหนดนั้นเป็นส่วนหนึ่งของชุดข้อมูลปรับแต่งละเอียดเดิมหรือไม่
การโจมตีจะมีประสิทธิผลมากที่สุดในกรณีที่มีการปรับแต่งโมเดล AI อย่างละเอียด ซึ่งหมายความว่ายิ่งโมเดลมีความเฉพาะทางมากเท่าไร การตรวจจับว่ามีการใช้รูปภาพบางภาพก็จะง่ายขึ้นเท่านั้น โดยทั่วไปแล้วสิ่งนี้จะใช้กับ LoRA ที่ออกแบบมาเพื่อจำลองคนดังหรือบุคคลทั่วไป
ผู้เขียนยังพบว่าการเพิ่มลายน้ำที่มองเห็นได้ให้กับภาพฝึกอบรมทำให้การตรวจจับง่ายขึ้นอีกด้วย แม้ว่าลายน้ำที่ซ่อนอยู่จะไม่ได้ช่วยมากนักก็ตาม
ที่น่าประทับใจคือ แนวทางนี้ได้รับการทดสอบในการตั้งค่าแบบกล่องดำ ซึ่งหมายความว่าแนวทางนี้สามารถทำงานได้โดยไม่ต้องเข้าถึงรายละเอียดภายในของโมเดล แต่เข้าถึงได้เฉพาะเอาต์พุตเท่านั้น
วิธีการที่ได้มานั้นต้องใช้การประมวลผลอย่างเข้มข้น ดังที่ผู้เขียนยอมรับ อย่างไรก็ตาม คุณค่าของงานนี้อยู่ที่การระบุแนวทางสำหรับการวิจัยเพิ่มเติม และพิสูจน์ว่าสามารถดึงข้อมูลออกมาได้อย่างสมจริงจนถึงค่าความคลาดเคลื่อนที่ยอมรับได้ ดังนั้น เนื่องจากลักษณะสำคัญ จึงไม่จำเป็นต้องใช้บนสมาร์ทโฟนในขั้นตอนนี้
วิธีการ/ข้อมูล
มีการใช้ชุดข้อมูลหลายชุดจากมหาวิทยาลัยเทคนิคแห่งเดนมาร์ก (DTU สถาบันเจ้าภาพสำหรับนักวิจัยสามคนของเอกสารฉบับนี้) ในการศึกษาเพื่อปรับแต่งโมเดลเป้าหมายและเพื่อการฝึกอบรมและทดสอบโหมดการโจมตี
ชุดข้อมูลที่ใช้ได้รับการดึงมาจาก วงโคจรของ DTU:
ดีซีนดีทียู ชุดภาพฐาน
ดีดีทียู ภาพที่คัดลอกมาจาก DTU Orbit
ดีซีนดีทียู พาร์ติชั่นของ DDTU ที่ใช้ปรับแต่งโมเดลเป้าหมายให้ละเอียดยิ่งขึ้น
ดันซีนDTU พาร์ติชั่น DDTU ที่ไม่ได้ใช้ปรับแต่งโมเดลการสร้างภาพใดๆ แต่ใช้เพื่อทดสอบหรือฝึกโมเดลการโจมตีแทน
wmDseenDTU พาร์ติชั่นของ DDTU ที่มีลายน้ำที่มองเห็นได้ ซึ่งใช้ปรับแต่งโมเดลเป้าหมายให้ละเอียดยิ่งขึ้น
เอชดับบลิวเอ็มดีเอส พาร์ติชั่นของ DDTU ที่มีลายน้ำที่ซ่อนอยู่ ซึ่งใช้สำหรับปรับแต่งโมเดลเป้าหมายให้ละเอียดยิ่งขึ้น
ดีเจนDTU ภาพที่สร้างขึ้นโดย แบบจำลองการแพร่กระจายแฝง (LDM) ซึ่งได้รับการปรับแต่งอย่างละเอียดบนชุดภาพ DseenDTU
ชุดข้อมูลที่ใช้ในการปรับแต่งโมเดลเป้าหมายประกอบด้วยคู่ภาพ-ข้อความที่มีคำบรรยาย บลิป โมเดลคำบรรยาย (บางทีอาจไม่ใช่เรื่องบังเอิญที่เป็นหนึ่งในโมเดลแบบไม่เซ็นเซอร์ที่ได้รับความนิยมมากที่สุดในชุมชน AI ทั่วไป)
BLIP ถูกกำหนดให้เติมคำนำหน้าวลี 'ภาพถ่ายหัวของ dtu' ต่อคำอธิบายแต่ละข้อ
นอกจากนี้ ยังมีการใช้ชุดข้อมูลหลายชุดจากมหาวิทยาลัย Aalborg (AAU) ในการทดสอบ โดยทั้งหมดได้มาจาก คลังข้อมูล AU VBN:
ดาอู รูปภาพคัดลอกมาจาก AAU vbn
ดีซีนเอยู พาร์ติชั่นของ DAAU ที่ใช้ปรับแต่งโมเดลเป้าหมายให้เหมาะสม
ดันซีนAAU พาร์ติชั่นของ DAAU ที่ไม่ได้ใช้ปรับแต่งโมเดลการสร้างภาพใดๆ แต่ใช้ในการทดสอบหรือฝึกโมเดลการโจมตี
ดีเจนเอยู รูปภาพที่สร้างโดย LDM ที่ปรับแต่งละเอียดบนชุดภาพ DseenAAU
เทียบเท่ากับชุดก่อนๆ วลี 'ภาพถ่ายหัวไหล่ของ' ถูกนำมาใช้ ซึ่งจะทำให้มั่นใจได้ว่าป้ายกำกับทั้งหมดในชุดข้อมูล DTU ปฏิบัติตามรูปแบบ 'ภาพถ่ายหัวของ dtu ของ (…)'เสริมสร้างคุณลักษณะหลักของชุดข้อมูลในระหว่างการปรับแต่งอย่างละเอียด
การทดสอบ
มีการทดลองหลายครั้งเพื่อประเมินว่าการโจมตีโดยการอนุมานความเป็นสมาชิกมีประสิทธิภาพดีเพียงใดกับโมเดลเป้าหมาย การทดสอบแต่ละครั้งมีจุดมุ่งหมายเพื่อพิจารณาว่าสามารถดำเนินการโจมตีที่ประสบความสำเร็จได้หรือไม่ภายในโครงร่างที่แสดงด้านล่าง โดยที่โมเดลเป้าหมายได้รับการปรับแต่งให้เหมาะสมบนชุดข้อมูลภาพที่ได้รับมาโดยไม่ได้รับอนุญาต

โครงร่างสำหรับแนวทาง
หลังจากที่ได้ปรับแต่งโมเดลให้ละเอียดแล้วและสอบถามเพื่อสร้างรูปภาพเอาต์พุต รูปภาพเหล่านี้จะถูกนำไปใช้เป็นตัวอย่างเชิงบวกเพื่อฝึกโมเดลการโจมตี ในขณะที่รูปภาพที่ไม่เกี่ยวข้องเพิ่มเติมจะถูกรวมไว้เป็นตัวอย่างเชิงลบ
โมเดลการโจมตีได้รับการฝึกโดยใช้ การเรียนรู้ภายใต้การดูแล จากนั้นจึงทดสอบกับภาพใหม่เพื่อดูว่าภาพเหล่านั้นเป็นส่วนหนึ่งของชุดข้อมูลที่ใช้ในการปรับแต่งโมเดลเป้าหมายหรือไม่ เพื่อประเมินความแม่นยำของการโจมตี จะใช้ข้อมูลทดสอบ 15% เก็บไว้เพื่อการตรวจสอบ.
เนื่องจากโมเดลเป้าหมายได้รับการปรับแต่งอย่างละเอียดบนชุดข้อมูลที่ทราบ สถานะการเป็นสมาชิกจริงของแต่ละภาพจึงได้รับการกำหนดไว้แล้วเมื่อสร้างข้อมูลฝึกอบรมสำหรับโมเดลการโจมตี การตั้งค่าที่ควบคุมนี้ช่วยให้ประเมินได้อย่างชัดเจนว่าโมเดลการโจมตีสามารถแยกแยะระหว่างรูปภาพที่เป็นส่วนหนึ่งของชุดข้อมูลการปรับแต่งอย่างละเอียดและรูปภาพที่ไม่อยู่ในชุดข้อมูลได้อย่างมีประสิทธิภาพเพียงใด
สำหรับการทดสอบเหล่านี้ เราใช้ Stable Diffusion V1.5 แม้ว่าโมเดลที่ค่อนข้างเก่านี้จะปรากฏในงานวิจัยจำนวนมากเนื่องจากต้องมีการทดสอบอย่างสม่ำเสมอและมีงานวิจัยก่อนหน้านี้จำนวนมากที่ใช้โมเดลนี้ แต่กรณีการใช้งานนี้เหมาะสม V1.5 ยังคงเป็นที่นิยมสำหรับการสร้าง LoRA ในชุมชนผู้ชื่นชอบ Stable Diffusion เป็นเวลานาน แม้จะมีการเปิดตัวเวอร์ชันต่อมาหลายเวอร์ชัน และแม้จะมีการถือกำเนิดของ การไหล – เพราะโมเดลนี้ไม่มีการเซ็นเซอร์ใดๆ เลย
รูปแบบการโจมตีของนักวิจัยมีพื้นฐานมาจาก เรสเน็ต-18โดยยังคงน้ำหนักที่ฝึกไว้ล่วงหน้าของโมเดลไว้ ชั้นสุดท้ายของ ResNet-18 ที่มี 1000 นิวรอนถูกแทนที่ด้วย เชื่อมต่ออย่างเต็มที่ ชั้นที่มีเซลล์ประสาท 2 เซลล์ การฝึกอบรม ปิด เป็นหมวดหมู่ ข้ามเอนโทรปีและ อดัม Optimizer ถูกนำมาใช้
สำหรับการทดสอบแต่ละครั้ง โมเดลการโจมตีจะได้รับการฝึกห้าครั้งโดยใช้วิธีที่แตกต่างกัน เมล็ดพันธุ์สุ่ม เพื่อคำนวณช่วงความเชื่อมั่น 95% สำหรับตัวชี้วัดที่สำคัญ ซีโร่ช็อต การจำแนกประเภทด้วย CLIP โดยใช้แบบจำลองเป็นพื้นฐาน
(โปรดทราบว่าตารางผลลัพธ์เบื้องต้นดั้งเดิมในเอกสารนั้นสั้นและเข้าใจยากเป็นพิเศษ ดังนั้น ฉันจึงได้ปรับปรุงใหม่ด้านล่างในรูปแบบที่ใช้งานง่ายยิ่งขึ้น โปรดคลิกที่รูปภาพเพื่อดูในความละเอียดที่ดีขึ้น)
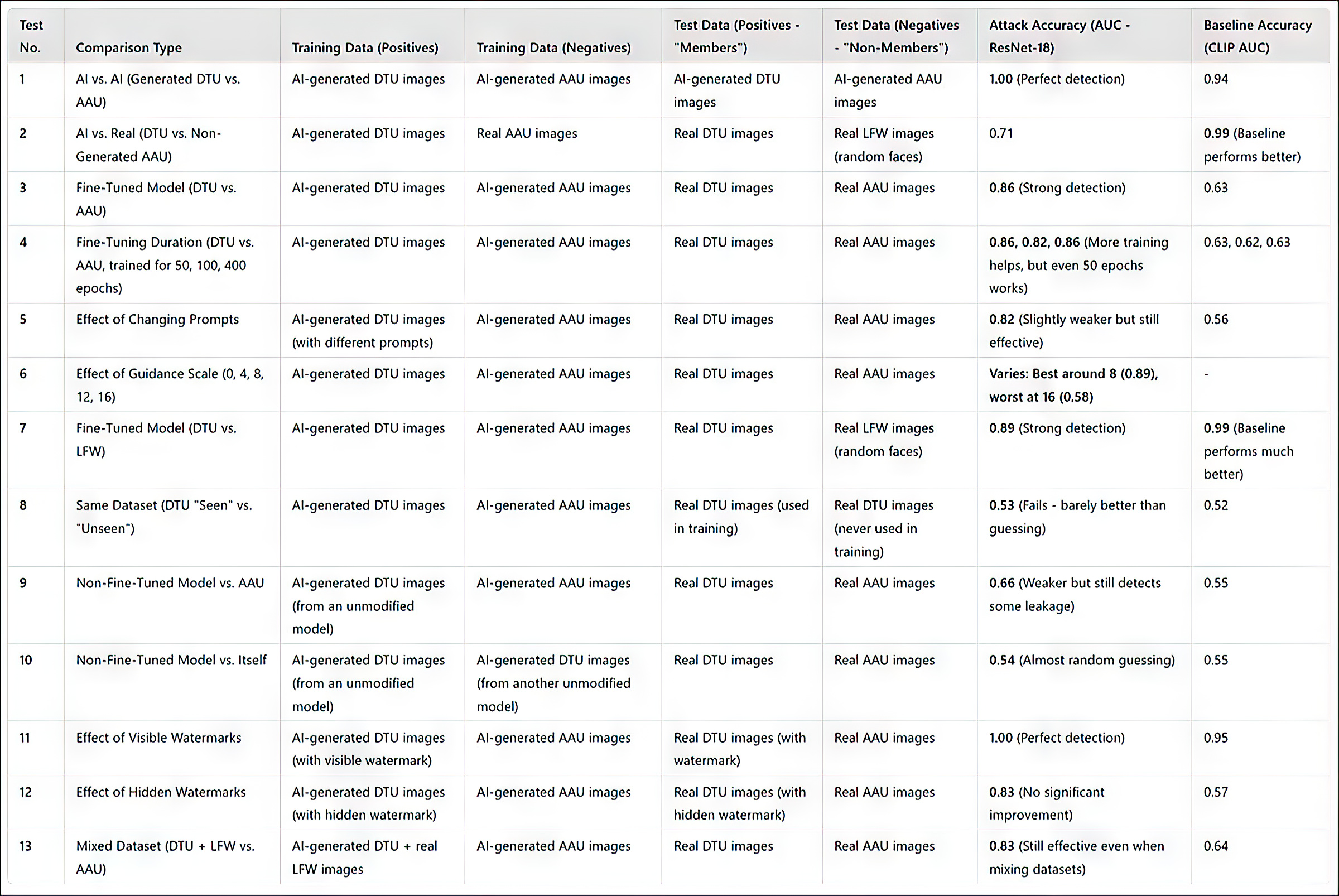
สรุปผลการทดสอบทั้งหมด คลิกที่ภาพเพื่อดูความละเอียดสูง
วิธีโจมตีของนักวิจัยพิสูจน์แล้วว่ามีประสิทธิภาพมากที่สุดเมื่อกำหนดเป้าหมายไปที่โมเดลที่ปรับแต่งอย่างละเอียด โดยเฉพาะโมเดลที่ฝึกจากชุดภาพเฉพาะ เช่น ใบหน้าของบุคคล อย่างไรก็ตาม แม้ว่าการโจมตีจะสามารถระบุได้ว่ามีการใช้ชุดข้อมูลหรือไม่ แต่กลับมีปัญหาในการระบุภาพแต่ละภาพภายในชุดข้อมูลนั้น
ในทางปฏิบัติ แนวทางหลังไม่จำเป็นต้องเป็นอุปสรรคต่อการใช้แนวทางดังกล่าวในเชิงนิติวิทยาศาสตร์ ถึงแม้ว่าการพิสูจน์ว่ามีการใช้ชุดข้อมูลที่มีชื่อเสียง เช่น ImageNet ในแบบจำลองจะมีคุณค่าค่อนข้างน้อย แต่ผู้โจมตีบุคคลทั่วไป (ไม่ใช่ผู้มีชื่อเสียง) มักจะมีแหล่งข้อมูลให้เลือกน้อยกว่ามาก และจำเป็นต้องใช้ประโยชน์จากกลุ่มข้อมูลที่มีอยู่ เช่น อัลบั้มโซเชียลมีเดียและคอลเลกชันออนไลน์อื่นๆ อย่างเต็มที่ วิธีนี้จะสร้าง "แฮช" ซึ่งสามารถเปิดเผยได้โดยวิธีการต่างๆ ที่ระบุไว้
เอกสารดังกล่าวระบุว่าอีกวิธีหนึ่งในการปรับปรุงความแม่นยำคือการใช้รูปภาพที่สร้างโดย AI ในฐานะ "ผู้ที่ไม่ใช่สมาชิก" แทนที่จะพึ่งพารูปภาพจริงเพียงอย่างเดียว วิธีนี้จะป้องกันไม่ให้มีอัตราความสำเร็จที่สูงเกินจริง ซึ่งอาจทำให้ผลลัพธ์คลาดเคลื่อนได้
ผู้เขียนได้ตั้งข้อสังเกตว่าปัจจัยเพิ่มเติมที่ส่งผลกระทบอย่างมากต่อการตรวจจับคือลายน้ำ เมื่อภาพฝึกมีลายน้ำที่มองเห็นได้ การโจมตีก็จะมีประสิทธิภาพสูง ในขณะที่ลายน้ำที่ซ่อนอยู่แทบไม่มีข้อได้เปรียบเลย

ภาพทางขวาสุดแสดงลายน้ำที่ 'ซ่อน' จริงที่ใช้ในการทดสอบ
ในที่สุด ระดับของการแนะนำในการสร้างข้อความเป็นรูปภาพก็มีบทบาทเช่นกัน โดยมีสมดุลที่เหมาะสมที่ระดับการแนะนำประมาณ 8 แม้ว่าจะไม่มีการแจ้งโดยตรง แต่โมเดลที่ปรับแต่งอย่างละเอียดก็ยังมีแนวโน้มที่จะสร้างผลลัพธ์ที่คล้ายกับข้อมูลการฝึกอบรม ซึ่งช่วยเสริมประสิทธิภาพของการโจมตี
สรุป
น่าเสียดายที่บทความที่น่าสนใจนี้ถูกเขียนขึ้นด้วยวิธีการที่ไม่สามารถเข้าถึงได้เช่นนี้ ทั้งที่ควรจะเป็นประโยชน์สำหรับผู้สนับสนุนความเป็นส่วนตัวและนักวิจัย AI ทั่วไปเช่นกัน
แม้ว่าการโจมตีโดยการอนุมานความเป็นสมาชิกอาจกลายเป็นเครื่องมือทางนิติวิทยาศาสตร์ที่น่าสนใจและมีประโยชน์ แต่สิ่งที่สำคัญยิ่งกว่าสำหรับกลุ่มการวิจัยนี้คือการพัฒนาหลักการทั่วไปที่สามารถนำไปปฏิบัติได้ เพื่อป้องกันไม่ให้กลายเป็นเกมตีตัวตุ่นแบบเดียวกับที่เกิดขึ้นกับการตรวจจับแบบดีปเฟกโดยทั่วไป เมื่อการเปิดตัวโมเดลใหม่ส่งผลเสียต่อการตรวจจับและระบบนิติวิทยาศาสตร์ที่คล้ายคลึงกัน
เนื่องจากมีหลักฐานบางอย่างของหลักการชี้นำระดับสูงที่ได้รับการชี้แจงในงานวิจัยใหม่นี้ เราจึงหวังว่าจะได้เห็นงานเพิ่มเติมในทิศทางนี้
เผยแพร่ครั้งแรกวันศุกร์ที่ 21 กุมภาพันธ์ 2025











