
Artificiell intelligens
Tre utmaningar framför stabil spridning

Ocuco-landskapet frigöra av stability.ai:s stabila diffusion latent diffusion bildsyntesmodell för ett par veckor sedan kan vara en av de viktigaste tekniska avslöjandena sedan DeCSS 1999; det är definitivt den största händelsen inom AI-genererade bilder sedan 2017 deepfakes kod kopierades över till GitHub och klaffade in i vad som skulle bli DeepFaceLab och Ansikts byte, såväl som deepfake-programvaran för strömning i realtid DeepFaceLive.
I ett slag, användarens frustration över innehållsbegränsningar i DALL-E 2:s bildsyntes-API sopades åt sidan, eftersom det visade sig att Stable Diffusions NSFW-filter kunde inaktiveras genom att ändra en enda kodraden. Porrcentrerade Stable Diffusion Reddits dök upp nästan omedelbart och klipptes lika snabbt ner, medan utvecklar- och användarlägret delade sig på Discord i de officiella och NSFW-gemenskaperna, och Twitter började fyllas på med fantastiska Stable Diffusion-skapelser.
För närvarande tycks varje dag ge en fantastisk innovation från utvecklarna som har antagit systemet, med plugins och tredjepartshjälpmedel som hastigt skrivs för krita, Photoshop, Cinema4D, Blandare, och många andra applikationsplattformar.

Under tiden, promptcraft – den numera professionella konsten att viska AI, som kan bli det kortaste karriäralternativet sedan ”Filofax binder” – håller redan på att bli kommersialiseras, medan tidig monetarisering av Stable Diffusion äger rum på Patreon nivå, med säkerhet om mer sofistikerade erbjudanden som kommer, för dem som inte vill navigera Conda-baserad installationer av källkoden eller de proskriptiva NSFW-filtren för webbaserade implementeringar.
Utvecklingstakten och den fria känslan av utforskning från användarna går i en så svindlande hastighet att det är svårt att se långt fram. I huvudsak vet vi inte exakt vad vi har att göra med ännu, eller vad alla begränsningar eller möjligheter kan vara.
Icke desto mindre, låt oss ta en titt på tre av vad som kan vara de mest intressanta och utmanande hindren för den snabbt bildade och snabbt växande stabila diffusionsgemenskapen att möta och, förhoppningsvis, övervinna.
1: Optimera kakelbaserade rörledningar
Presenterat med begränsade hårdvaruresurser och hårda gränser för upplösningen av träningsbilder, verkar det troligt att utvecklare kommer att hitta lösningar för att förbättra både kvaliteten och upplösningen för stabil diffusion. Många av dessa projekt är inställda på att utnyttja systemets begränsningar, såsom dess ursprungliga upplösning på bara 512×512 pixlar.
Som alltid är fallet med datorseende och bildsyntesinitiativ tränades Stable Diffusion på bilder i kvadratförhållande, i detta fall omsamplade till 512×512, så att källbilderna kunde regleras och passa in i begränsningarna för GPU:erna som tränade modellen.
Därför "tänker" stabil diffusion (om den alls tänker) i 512×512 termer, och säkert i kvadratiska termer. Många användare som för närvarande undersöker systemets gränser rapporterar att stabil diffusion ger de mest tillförlitliga och minst glitchy resultaten vid detta ganska begränsade bildförhållande (se "att adressera extremiteter" nedan).
Även om olika implementeringar har uppskalning via RealESRGAN (och kan fixa dåligt renderade ansikten via GFPGAN) flera användare utvecklar för närvarande metoder för att dela upp bilder i 512x512px sektioner och sy ihop bilderna för att bilda större sammansatta verk.

Denna 1024×576-rendering, en upplösning som vanligtvis är omöjlig i en enda stabil diffusionsrendering, skapades genom att kopiera och klistra in filen attention.py Python från filen DoggettX fork of Stable Diffusion (en version som implementerar kakelbaserad uppskalning) till en annan gaffel. Källa: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Även om vissa initiativ av detta slag använder originalkod eller andra bibliotek, txt2imghd port av GOBIG (ett läge i den VRAM-hungriga ProgRockDiffusion) är inställd på att tillhandahålla denna funktion till huvudgrenen snart. Medan txt2imghd är en dedikerad port för GOBIG, involverar andra ansträngningar från communityutvecklare olika implementeringar av GOBIG.

En bekvämt abstrakt bild i den ursprungliga renderingen på 512x512px (vänster och andra från vänster); uppskalad av ESGRAN, som nu är mer eller mindre inbyggt i alla stabila diffusionsdistributioner; och ges "särskild uppmärksamhet" via en implementering av GOBIG, som producerar detaljer som, åtminstone inom gränserna för bildsektionen, verkar bättre uppskalade. Source: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Den typ av abstrakta exempel som presenteras ovan har många "små riken" av detaljer som passar denna solipsistiska inställning till uppskalning, men som kan kräva mer utmanande koddrivna lösningar för att producera icke-repetitiv, sammanhängande uppskalning som inte se som om den var sammansatt av många delar. Inte minst när det gäller mänskliga ansikten, där vi är ovanligt inställda på aberrationer eller "skakande" artefakter. Därför kan ansikten så småningom behöva en dedikerad lösning.
Stabil Diffusion har för närvarande ingen mekanism för att fokusera uppmärksamheten på ansiktet under en rendering på samma sätt som människor prioriterar ansiktsinformation. Även om vissa utvecklare i Discord-gemenskaperna överväger metoder för att implementera den här typen av "förbättrad uppmärksamhet", är det för närvarande mycket lättare att manuellt (och så småningom automatiskt) förbättra ansiktet efter att den första renderingen har ägt rum.
Ett mänskligt ansikte har en inre och fullständig semantisk logik som inte finns i en "bricka" i det nedre hörnet av (till exempel) en byggnad, och därför är det för närvarande möjligt att mycket effektivt "zooma in" och återrendera en "skissartad" yta i stabil diffusionsutgång.

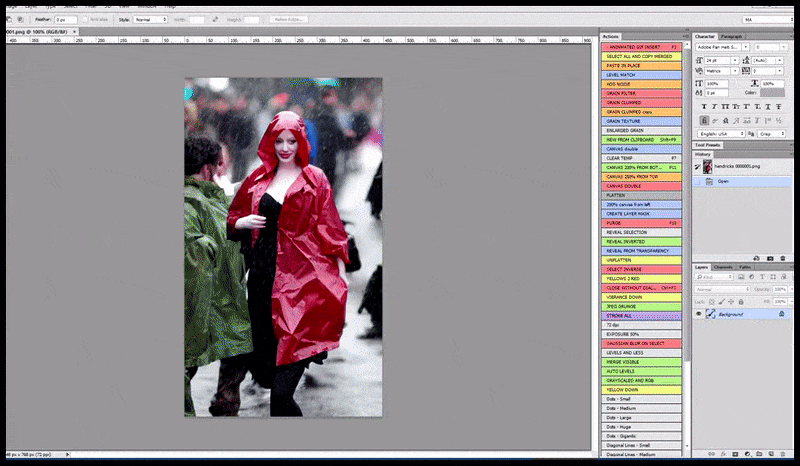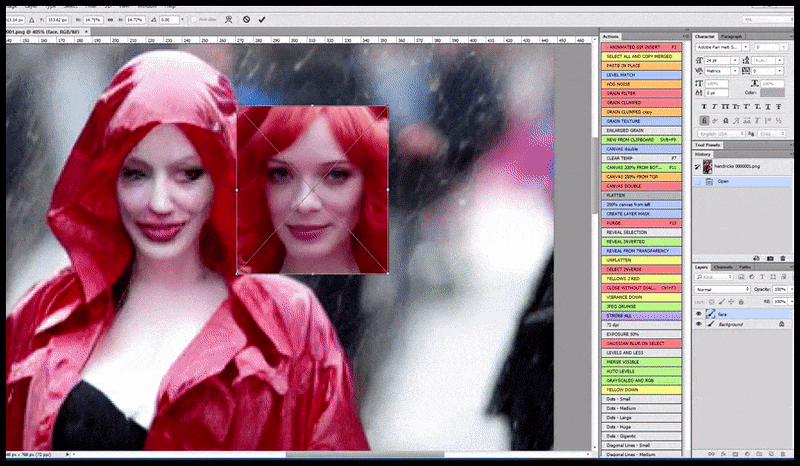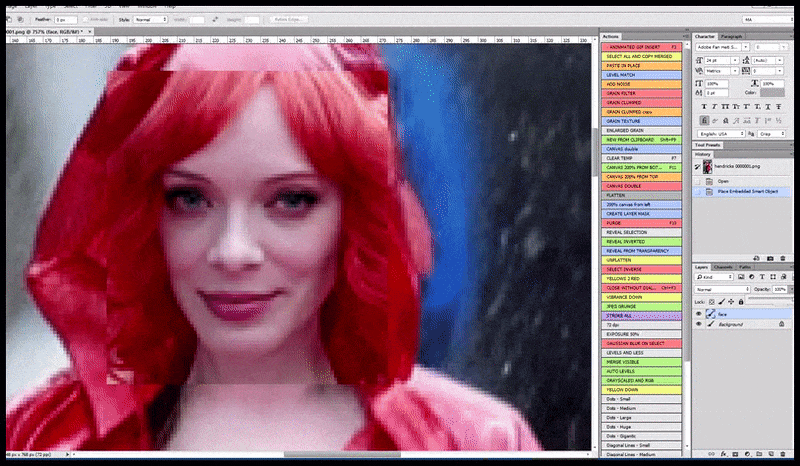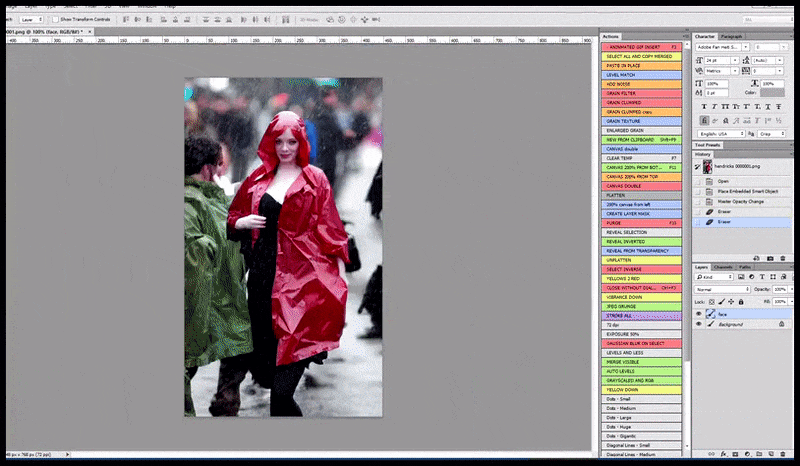
Vänster, Stable Diffusions första insats med det snabba 'Färgfoto i full längd av Christina Hendricks på väg in på en trång plats, iklädd regnrock; Canon50, ögonkontakt, hög detalj, hög ansiktsdetalj”. Till höger, ett förbättrat ansikte som erhålls genom att mata tillbaka det suddiga och skissartade ansiktet från den första renderingen till Stable Diffusions fulla uppmärksamhet med Img2Img (se animerade bilder nedan).
I avsaknad av en dedikerad Textual Inversion-lösning (se nedan), kommer detta endast att fungera för kändisbilder där personen i fråga redan är väl representerad i LAION-dataunderuppsättningarna som tränade Stabil Diffusion. Därför kommer det att fungera på sådana som Tom Cruise, Brad Pitt, Jennifer Lawrence och ett begränsat utbud av äkta medialjus som finns i ett stort antal bilder i källdata.
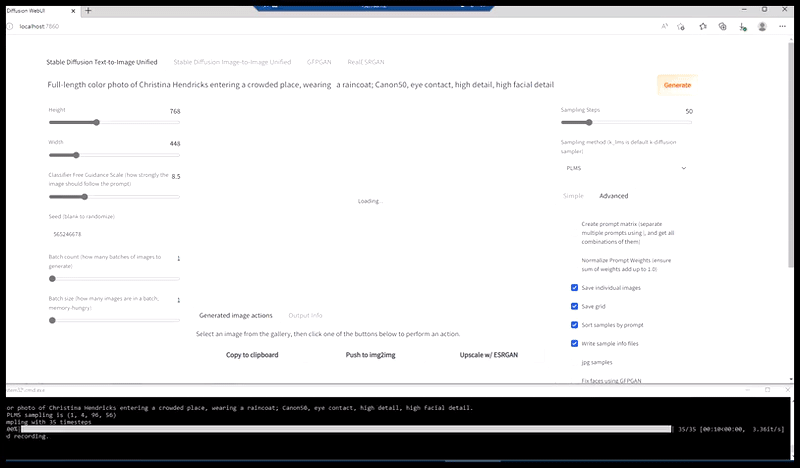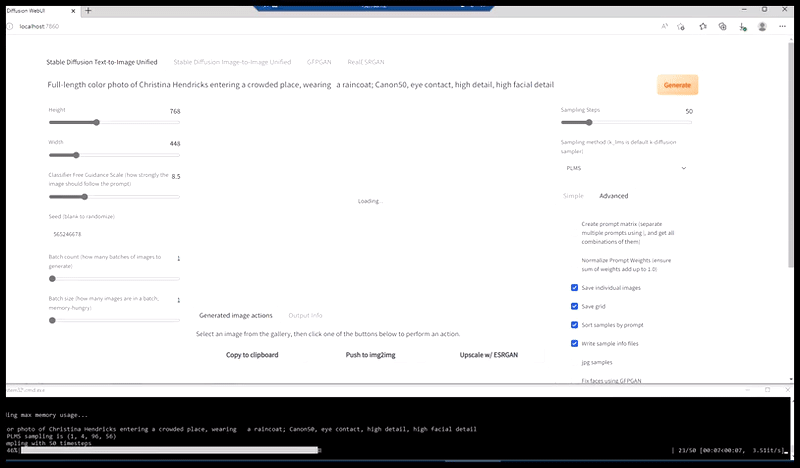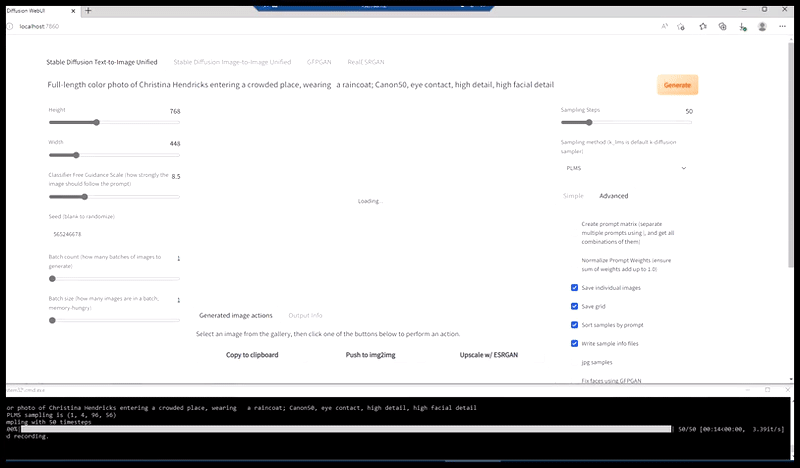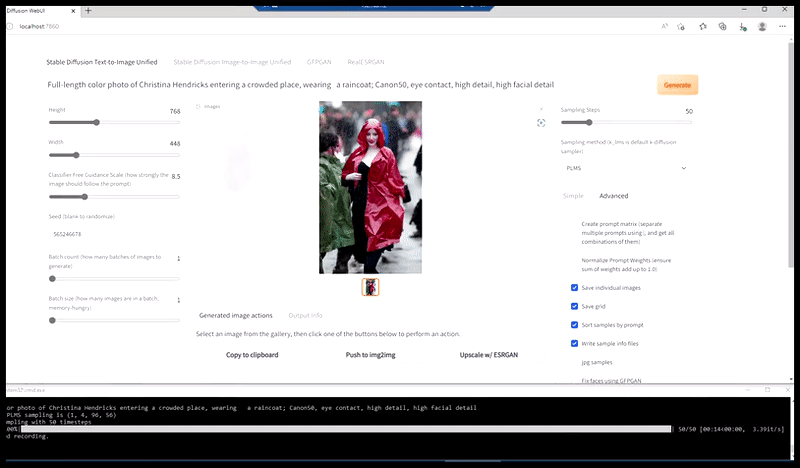
Genererar en trovärdig pressbild med prompten 'Färgfoto i fullängd av Christina Hendricks som går in på en trång plats, iklädd regnrock; Canon50, ögonkontakt, hög detalj, hög ansiktsdetalj”.
För kändisar med långa och långvariga karriärer kommer Stable Diffusion vanligtvis att generera en bild av personen vid en nyligen (dvs. äldre) ålder, och det kommer att vara nödvändigt att lägga till snabba tillägg som t.ex. 'ung' or 'under året [YEAR]' för att producera bilder som ser yngre ut.

Med en framstående, mycket fotograferad och konsekvent karriär som sträcker sig över nästan 40 år, är skådespelerskan Jennifer Connelly en av en handfull kändisar i LAION som låter Stable Diffusion representera en rad åldrar. Källa: förpackning stabil diffusion, lokal, v1.4 kontrollpunkt; åldersrelaterade uppmaningar.
Detta beror till stor del på spridningen av digitala (snarare än dyra, emulsionsbaserade) pressfotografier från mitten av 2000-talet och framåt, och den senare ökningen i volym av bildutdata på grund av ökade bredbandshastigheter.
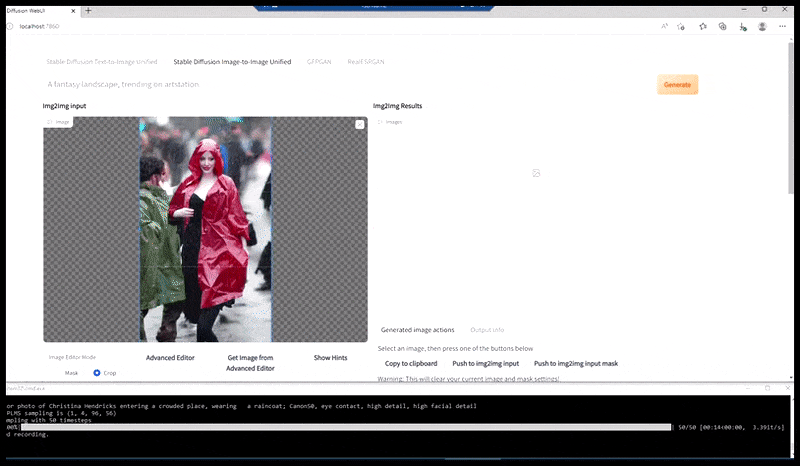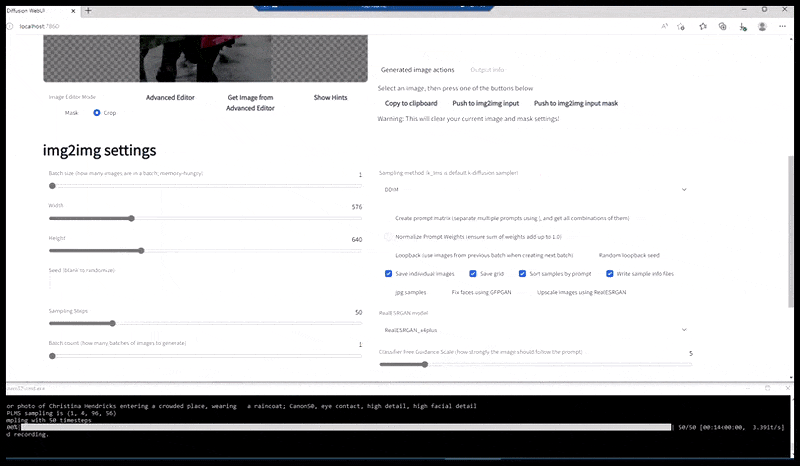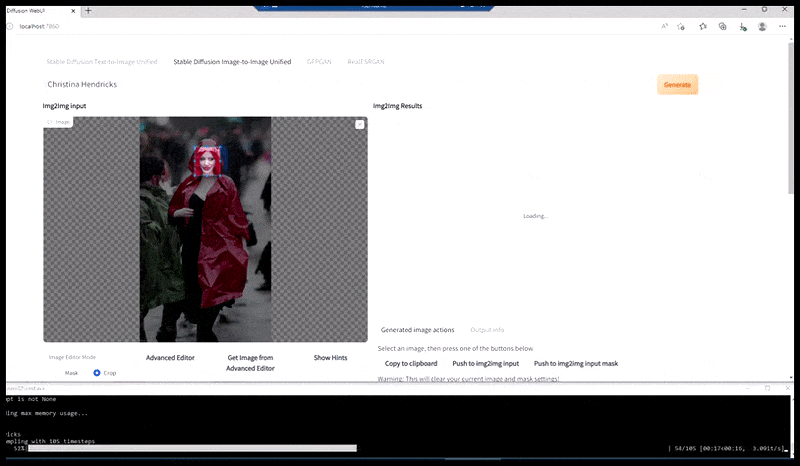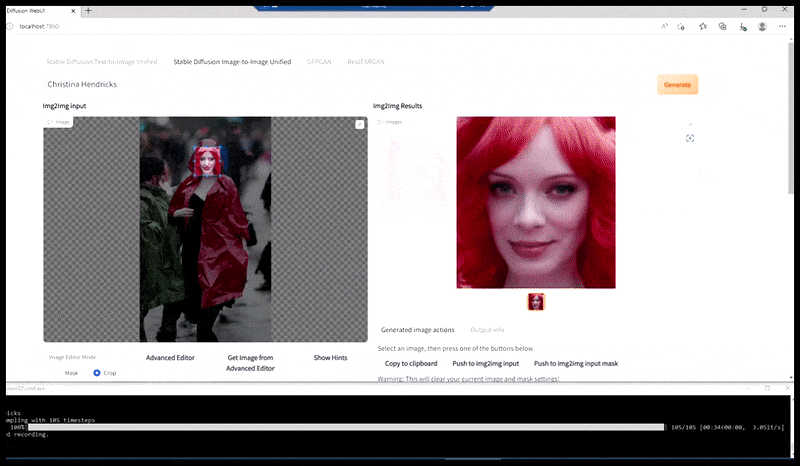
Den renderade bilden skickas vidare till Img2Img i Stable Diffusion, där ett "fokusområde" väljs, och en ny rendering i maximal storlek görs endast av det området, vilket gör att Stable Diffusion kan koncentrera alla tillgängliga resurser på att återskapa ansiktet.
Sammansättning av ansiktet med "hög uppmärksamhet" till den ursprungliga renderingen. Förutom ansikten kommer denna process bara att fungera med enheter som har ett potentiellt känt, sammanhängande och integrerat utseende, till exempel en del av originalfotot som har ett distinkt föremål, som en klocka eller en bil. Att skala upp en del av – till exempel – en vägg kommer att leda till en mycket konstigt utseende återmonterad vägg, eftersom kakelputserna inte hade något vidare sammanhang för denna "sticksågsbit" som de gjorde.
Vissa kändisar i databasen kommer "förfrysta" i tid, antingen för att de dog tidigt (som Marilyn Monroe), eller för att de bara blev flyktiga mainstream-framträdande platser och producerade en stor mängd bilder under en begränsad tidsperiod. Polling Stable Diffusion ger utan tvekan ett slags "aktuellt" popularitetsindex för moderna och äldre stjärnor. För vissa äldre och nuvarande kändisar finns det inte tillräckligt med bilder i källdata för att få en mycket bra likhet, medan den bestående populariteten för särskilda sedan länge döda eller på annat sätt bleknade stjärnor säkerställer att deras rimliga likhet kan erhållas från systemet.

Stabila diffusionsrenderingar avslöjar snabbt vilka kända ansikten som är väl representerade i träningsdatan. Trots sin enorma popularitet som äldre tonåring i skrivande stund var Millie Bobby Brown yngre och mindre känd när LAIONs källdata skrapades från webben, vilket gjorde en högkvalitativ likhet med Stable Diffusion problematisk för tillfället.
Där data finns tillgänglig kan kakelbaserade upplösningslösningar i Stable Diffusion gå längre än att vända sig till ansiktet: de skulle potentiellt kunna möjliggöra ännu mer exakta och detaljerade ansikten genom att bryta ner ansiktsdragen och vända på hela kraften hos den lokala GPU:n resurser på framträdande egenskaper individuellt, före återmontering – en process som för närvarande återigen är manuell.

Detta är inte begränsat till ansikten, utan det är begränsat till delar av objekt som är minst lika förutsägbart placerade i värdobjektets bredare sammanhang, och som överensstämmer med inbäddningar på hög nivå som man rimligen kan förvänta sig att hitta i en hyperskala dataset.
Den verkliga gränsen är mängden tillgängliga referensdata i datamängden, eftersom djupt itererade detaljer så småningom kommer att bli totalt "hallucinerade" (dvs. fiktiva) och mindre autentiska.
Sådana granulära förstoringar på hög nivå fungerar i fallet med Jennifer Connelly, eftersom hon är välrepresenterad över en rad åldrar i LAION-estetik (den primära delmängden av LAION 5B som Stable Diffusion använder), och i allmänhet över LAION; i många andra fall skulle noggrannheten lida av brist på data, vilket kräver antingen finjustering (ytterligare utbildning, se 'Anpassning' nedan) eller textinversion (se nedan).
Kakel är ett kraftfullt och relativt billigt sätt för stabil spridning att kunna producera högupplöst utdata, men algoritmisk platta uppskalning av detta slag, om den saknar någon form av bredare uppmärksamhetsmekanism på högre nivå, kan misslyckas med det förväntade. för standarder för en rad innehållstyper.
2: Ta itu med problem med mänskliga lemmar
Stabil diffusion lever inte upp till sitt namn när den skildrar komplexiteten hos mänskliga extremiteter. Händer kan föröka sig slumpmässigt, fingrar smälter samman, tredje ben verkar objudna och befintliga lemmar försvinner spårlöst. Till sitt försvar delar Stable Diffusion problemet med sina stallkamrater, och absolut med DALL-E 2.

Ej redigerade resultat från DALL-E 2 och Stable Diffusion (1.4) i slutet av augusti 2022, båda visar problem med lemmar. Uppmaningen är "En kvinna som omfamnar en man"
Stable Diffusion-fans som hoppas att den kommande 1.5-kontrollpunkten (en mer intensivt tränad version av modellen, med förbättrade parametrar) skulle lösa lemförvirringen kommer sannolikt att bli besvikna. Den nya modellen, som kommer att släppas i ungefär två veckor, premiärvisas för närvarande på den kommersiella stability.ai-portalen drömstudio, som använder 1.5 som standard, och där användare kan jämföra den nya utdatan med renderingar från sina lokala eller andra 1.4-system:

Källa: Local 1.4 prepack och https://beta.dreamstudio.ai/

Källa: Local 1.4 prepack och https://beta.dreamstudio.ai/

Källa: Local 1.4 prepack och https://beta.dreamstudio.ai/
Som ofta är fallet kan datakvalitet mycket väl vara den främsta bidragande orsaken.
De öppna källkodsdatabaserna som driver bildsyntessystem som Stable Diffusion och DALL-E 2 kan tillhandahålla många etiketter för både enskilda människor och inter-mänsklig handling. Dessa etiketter tränas in symbiotiskt med deras associerade bilder, eller segment av bilder.

Stabil Diffusion-användare kan utforska koncepten som tränats in i modellen genom att fråga LAION-estetikdataset, en delmängd av den större LAION 5B-datauppsättningen, som driver systemet. Bilderna ordnas inte efter deras alfabetiska etiketter, utan efter deras "estetiska partitur". Källa: https://rom1504.github.io/clip-retrieval/
A bra hierarki av individuella etiketter och klasser som bidrar till skildringen av en mänsklig arm skulle vara något liknande kropp>arm>hand>fingrar>[undersiffror + tumme]> [siffersegment]>Fingernaglar.

Granulär semantisk segmentering av delarna av en hand. Även denna ovanligt detaljerade dekonstruktion lämnar varje "finger" som en enda enhet, utan att ta hänsyn till de tre sektionerna av ett finger och de två sektionerna av en tumme. Källa: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
I verkligheten är det osannolikt att källbilderna kommer att vara så konsekvent kommenterade över hela datasetet, och oövervakade märkningsalgoritmer kommer förmodligen att stanna vid högre nivå av – till exempel – 'hand', och lämna de inre pixlarna (som tekniskt sett innehåller 'finger'-information) som en omärkt massa pixlar från vilka egenskaper kommer att härledas godtyckligt, och som kan manifesteras i senare renderingar som ett skakande element.

Hur det ska vara (uppe till höger, om inte upper-cut), och hur det tenderar att vara (nedre höger), på grund av begränsade resurser för märkning eller arkitektoniskt utnyttjande av sådana etiketter om de finns i datasetet.
Således, om en latent diffusionsmodell når så långt som att återge en arm, kommer den nästan säkert att åtminstone försöka återge en hand i slutet av den armen, eftersom arm>hand är den minimala erforderliga hierarkin, ganska högt upp i vad arkitekturen vet om "mänsklig anatomi".
Därefter kan "fingrar" vara den minsta grupperingen, även om det finns ytterligare 14 underdelar av finger/tumme att tänka på när man avbildar människohänder.
Om denna teori håller, finns det inget verkligt botemedel, på grund av den sektorsomfattande bristen på budget för manuell anteckning och bristen på tillräckligt effektiva algoritmer som kan automatisera märkning samtidigt som de ger låga felfrekvenser. I själva verket kan modellen för närvarande förlita sig på mänsklig anatomisk konsistens till papper över bristerna i datamängden den tränades på.
En möjlig anledning till det kan inte lita på detta, nyligen föreslagen vid Stable Diffusion Discord, är att modellen kan bli förvirrad över det korrekta antalet fingrar en (realistisk) mänsklig hand ska ha eftersom den LAION-härledda databasen som driver den innehåller seriefigurer som kan ha färre fingrar (vilket är i sig självt) en arbetsbesparande genväg).

Två av de potentiella bovarna i "saknat finger"-syndrom i stabil diffusion och liknande modeller. Nedan, exempel på tecknade händer från LAION-estetikdataset som driver Stable Diffusion. Källa: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Om detta är sant är den enda uppenbara lösningen att omskola modellen, exklusive icke-realistiskt mänskligt baserat innehåll, och se till att äkta fall av utelämnande (dvs. amputerade) på lämpligt sätt betecknas som undantag. Enbart från en datakuratorpunkt skulle detta vara en stor utmaning, särskilt för resurssnåla samhällsinsatser.
Det andra tillvägagångssättet skulle vara att tillämpa filter som utesluter sådant innehåll (dvs. 'hand med tre/fem fingrar') från att manifesteras vid renderingstid, ungefär på samma sätt som OpenAI i viss utsträckning har, filtrerades GPT-3 och DALL-E2, så att deras produktion kunde regleras utan att behöva omskola källmodellerna.

För Stable Diffusion kan den semantiska distinktionen mellan siffror och till och med lemmar bli fruktansvärt suddig, vilket för tankarna till 1980-talets "kroppsskräck"-sträng av skräckfilmer från sådana som David Cronenberg. Källa: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Men återigen skulle detta kräva etiketter som kanske inte finns på alla berörda bilder, vilket lämnar oss med samma logistiska och budgetmässiga utmaning.
Det kan hävdas att det finns två återstående vägar framåt: att kasta mer data på problemet och att tillämpa tolkningssystem från tredje part som kan ingripa när fysiska goofs av den typ som beskrivs här presenteras för slutanvändaren (åtminstone, det senare skulle ge OpenAI en metod att ge återbetalningar för "kroppsskräck"-renderingar, om företaget var motiverat att göra det).
3: Anpassning
En av de mest spännande möjligheterna för Stable Diffusions framtid är möjligheten att användare eller organisationer utvecklar reviderade system; modifieringar som gör att innehåll utanför den förtränade LAION-sfären kan integreras i systemet – helst utan den oöverskådliga kostnaden för att träna hela modellen om igen, eller risken medföra när man tränar i en stor volym nya bilder till en befintlig, mogen och kapabel modell.
Analogt: om två mindre begåvade elever går med i en avancerad klass på trettio elever, kommer de antingen att assimilera och komma ikapp, eller misslyckas som extrema; i båda fallen kommer klassens genomsnittliga prestanda förmodligen inte att påverkas. Om 15 mindre begåvade elever går med kommer dock betygskurvan för hela klassen att bli lidande.
Likaså kan det synergistiska och ganska känsliga nätverket av relationer som byggs upp under långvarig och dyr modellträning äventyras, i vissa fall effektivt förstöras, av alltför mycket ny data, vilket sänker utdatakvaliteten för modellen över hela linjen.
Grunden för att göra detta är i första hand där ditt intresse ligger i att fullständigt kapa modellens konceptuella förståelse av relationer och saker, och tillägna sig den för exklusiv produktion av innehåll som liknar det tilläggsmaterial som du lagt till.
Alltså träning 500,000 XNUMX Simpsons ramar in i en befintlig stabil diffusionskontrollpunkt kommer sannolikt, så småningom, att göra dig bättre Simpsons simulator än den ursprungliga konstruktionen kunde ha erbjudit, förutsatt att tillräckligt med breda semantiska relationer överlever processen (dvs. Homer Simpson äter en korv, som kan kräva material om korv som inte fanns i ditt tilläggsmaterial, men som redan fanns i checkpointen), och förutsatt att du inte plötsligt vill byta från Simpsons innehåll att skapa fantastiskt landskap av Greg Rutkowski – eftersom din eftertränade modell har fått sin uppmärksamhet massivt avledd, och kommer inte att vara lika bra på att göra sånt som den brukade vara.
Ett anmärkningsvärt exempel på detta är waifu-diffusion, vilket har lyckats eftertränade 56,000 XNUMX animebilder till en färdig och tränad kontrollpunkt för stabil diffusion. Det är dock en tuff utsikt för en hobbyist, eftersom modellen kräver ett iögonfallande minimum på 30 GB VRAM, långt utöver vad som sannolikt kommer att finnas tillgängligt på konsumentnivån i NVIDIAs kommande 40XX-seriesläpp.

Utbildning av anpassat innehåll till stabil spridning via waifu-diffusion: modellen tog två veckors efterträning för att producera denna nivå av illustration. De sex bilderna till vänster visar modellens framsteg, allteftersom utbildningen fortskred, för att göra ämnessammanhängande utdata baserat på den nya träningsdatan. Källa: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
En hel del ansträngning skulle kunna läggas på sådana "gafflar" av stabila diffusionskontrollpunkter, bara för att hindras av tekniska skulder. Utvecklare på den officiella Discord har redan indikerat att senare versioner av checkpoint inte nödvändigtvis kommer att vara bakåtkompatibla, även med prompt logik som kan ha fungerat med en tidigare version, eftersom deras primära intresse är att få den bästa möjliga modellen, snarare än att stödja äldre applikationer och processer.
Därför har ett företag eller en individ som bestämmer sig för att förgrena sig en checkpoint till en kommersiell produkt i praktiken ingen väg tillbaka; deras version av modellen är vid den tidpunkten en "hård gaffel" och kommer inte att kunna dra in uppströmsfördelar från senare utgåvor från stability.ai – vilket är ett stort engagemang.
Det nuvarande och större hoppet om anpassning av stabil diffusion är Textinversion, där användaren tränar in en liten handfull KLÄMMA-justerade bilder.

Ett samarbete mellan Tel Aviv University och NVIDIA, textinversion möjliggör träning av diskreta och nya enheter utan att förstöra källmodellens möjligheter. Källa: https://textual-inversion.github.io/
Den primära uppenbara begränsningen av textinversion är att ett mycket litet antal bilder rekommenderas – så få som fem. Detta producerar effektivt en begränsad enhet som kan vara mer användbar för stilöverföringsuppgifter snarare än infogning av fotorealistiska objekt.
Ändå pågår för närvarande experiment inom de olika stabila diffusionsdiscorderna som använder mycket högre antal träningsbilder, och det återstår att se hur produktiv metoden kan visa sig. Återigen kräver tekniken en hel del VRAM, tid och tålamod.
På grund av dessa begränsande faktorer kan vi behöva vänta ett tag för att se några av de mer sofistikerade textinversionsexperimenten från Stable Diffusion-entusiaster – och om detta tillvägagångssätt kan "sätta dig i bilden" på ett sätt som ser bättre ut än en Klipp-och-klistra i Photoshop, samtidigt som den häpnadsväckande funktionaliteten hos de officiella kontrollpunkterna behålls.
Första gången publicerad 6 september 2022.











