Hälso- och sjukvård
Populära COVIDx-databasen kritiseras av brittiska forskare
Ett forskningskonsortium från Storbritannien har riktat kritik mot den vetenskapliga tillförlitlighet som investeras i öppen källkodsdata som används för datorseende-baserad analys av COVID-19-patienters bröstkorgsröntgenbilder, med fokus på den populära öppna källkodsdatamängden COVIDx.
Forskarna, som har testat COVIDx i olika AI-träningsmodeller, hävdar att den “inte är representativ för det verkliga kliniska problemet”, att resultaten som erhålls genom att använda den är “överdrivna”, och att modellerna “inte generaliserar bra” till verkliga data.
Författarna noterar också inkonsekvensen i den bidragande datan som utgör COVIDx, där ursprungsbilder kommer i en mängd olika upplösningar som automatiskt omformateras av den djupa inlärningsarbetsflödet till de konsekventa storlekar som krävs för träning, och observerar att denna process kan introducera bedrägliga artefakter relaterade till bildomstorleksalgoritmen, snarare än den kliniska aspekten av datan.
Den artikeln heter De fallgropar som används för att utveckla djupinlärningslösningar för COVID-19-detektering i bröstkorgsröntgenbilder, och är ett samarbete mellan Center for Computational Imaging & Simulation in Biomedicine (CISTIB) vid University of Leeds, tillsammans med forskare från fem andra organisationer i samma stad, inklusive Leeds Teaching Hospitals NHS Trust.
Forskningsdetaljerna, bland annat negativa metoder, “missbruk av etiketter” i COVIDx-databasen, samt en “hög risk för bias och sammanblandning”. Forskarnas egna experiment med att sätta datamängden genom dess paces över tre livskraftiga djupinlärningsmodeller fick dem att dra slutsatsen att ‘den exceptionella prestationen som rapporteras brett över problemområdet är överdriven, att modellprestationsresultat är missrepresenterade, och att modellerna inte generaliserar bra till kliniskt realistiska data.’
Fem kontrasterande datamängder i en
Rapporten* noterar att de flesta nuvarande AI-baserade metoder i detta område är beroende av en “heterogen” samling av data från olika öppna källkodsarkiv, och observerar att fem datamängder med olika egenskaper har samlats in i COVIDx-databasen trots (enligt forskarnas bedömning) otillräcklig paritet i datorkvalitet och typ.
COVIDx-databasen släpptes i maj 2020 som ett konsortieansträngning lett av avdelningen för systemdesign vid University of Waterloo i Kanada, med datan tillgänglig som en del av COVID-Net Open Source Initiative.
De fem samlingarna som utgör COVIDx är: COVID-19 Image Data Collection (en öppen källkods uppsättning från Montreal-forskare); COVID-19 Chest X-ray Dataset initiativ; Actualmed COVID-19 Chest X-ray datamängd; COVID-19 Radiography Database; och RSNA Pneumonia Detection Challenge datamängd, en av de många pre-COVID-samlingar som har pressats in i tjänst för pandemikrisen.
(RICORD – se nedan – har sedan lagts till COVIDx, men eftersom det lades till efter modellerna i studien, uteslöts det från testdatat, och i vilket fall som helst kommer det att ha tenderat att variera COVIDx ännu mer, vilket är det centrala klagomålet från författarna till studien.)
Forskarna hävdar att COVIDx är ‘den största och mest använda’ datamängden av sitt slag inom den vetenskapliga gemenskapen relaterad till COVID-forskning, och att data som importeras till COVIDx från de konstituerande externa datamängderna inte tillräckligt överensstämmer med den tripartita schemat för COVIDx-databasen (dvs. ‘normal’, ‘pneumoni’ och ‘COVID-19’).
Nästan…?
Vid undersökning av ursprunget och lämpligheten för de bidragande datamängderna för COVIDx vid tidpunkten för studien, fann forskarna ‘missbruk’ av RSNA-data, där data av en typ har, enligt forskarna, herdat in i en annan kategori:
‘RSNA-repositoriet, som använder offentligt tillgängliga bröstkorgsröntgenbilder från NIH Chestx-ray8 [**], var utformat för en segmenteringsuppgift och innehåller därför tre klasser av bilder, ‘Lung Opacity’, ‘No Lung Opacity/Not Normal’ och ‘Normal’, med begränsningsrutor tillgängliga för ‘Lung Opacity’-fall.
‘I dess sammanställning till COVIDx ingår alla bröstkorgsröntgenbilder från ‘Lung Opacity’-klassen i pneumoniklassen.’
Effektivt, hävdar artikeln, utvidgar COVIDx-metodiken definitionen av ‘pneumoni’ till att omfatta ‘alla pneumonilika lungopaciteter’. Följaktligen hotas den lika-för-likavärdet av jämförbara datatyper. Forskarna hävdar:
‘ […] pneumoniklassen inom COVIDx-databasen innehåller bröstkorgsröntgenbilder med en samling av många andra patologier, inklusive pleuravätska, infiltration, konsolidering, emfysem och massor. Konsolidering är en radiologisk egenskap av möjlig pneumoni, inte en klinisk diagnos. Att använda konsolidering som ersättning för pneumoni utan att dokumentera detta är potentiellt vilseledande.’

Alternativa patologier (förutom COVID-19) associerade med COVIDx. Källa: https://arxiv.org/ftp/arxiv/papers/2109/2109.08020.pdf
Rapporten finner att endast 6,13% av de 4 305 pneumonifallen som hämtats från RSNA var korrekt etiketterade, vilket representerar endast 265 äkta pneumonifall.
Dessutom representerade många av de icke-pneumonifall som ingick i COVIDx komorbiditeter – komplikationer av andra sjukdomar eller sekundära medicinska problem i tillstånd som inte nödvändigtvis är relaterade till pneumoni.
Inte ‘Normal’
Rapporten föreslår vidare att inflytandet från RSNA-utmaningsdatamängden i COVIDx har snedvridit den empiriska stabiliteten i datan. Forskarna observerar att COVIDx prioriterar ‘normal’-klassen i RSNA-data, effektivt uteslutande alla ‘no lung opacity/not normal’-klasser i den bredare datamängden. Artikeln säger:
‘Medan detta är i överensstämmelse med vad som förväntas inom ‘normal’-etiketten, utvidgar pneumoniklassen och använder endast ‘normala’ bröstkorgsröntgenbilder, snarare än pneumoni-negativa fall, vilket avsevärt förenklar klassificeringsuppgiften.
‘Det slutliga resultatet av detta är en datamängd som reflekterar en uppgift som är avlägsen från det verkliga kliniska problemet.’
Potentiella bias från oförenliga datastandarder
Artikeln påvisar ett antal andra typer av bias i COVIDx, och noterar att vissa av de bidragande datamängderna blandar pediatriska bröstkorgsröntgenbilder med vuxna patienters röntgenbilder, och observerar dessutom att denna data är den enda ‘signifikanta’ källan till pediatriska bilder i COVIDx.
Även bilder från RSNA-databasen har en upplösning på 1024×1024, medan en annan bidragande datamängd endast tillhandahåller bilder med en upplösning på 299×299. Eftersom maskinlärningsmodeller kommer att omforma bilderna för att anpassa sig till den tillgängliga träningsytan (latent yta), innebär detta att 299×299-bilderna kommer att skalas upp i en träningsarbetsflöde (potentiellt leder till artefakter relaterade till en skalningsalgoritm snarare än patologi), och de större bilderna skalas ned. Återigen, detta motverkar de homogena datastandarder som krävs för AI-baserad datorseendeanalys.
Dessutom innehåller ActMed-data som ingår i COVIDx ‘skivformade markörer’ i COVID-19-bröstkorgsröntgenbilder, en återkommande funktion som är inkonsekvent med den bredare datamängden, och som skulle behöva hanteras som en ‘återkommande outlier’.
Detta är den typ av problem som vanligtvis hanteras genom att rensa eller utesluta datan, eftersom återkomsten av markörerna är tillräcklig för att registrera som en ‘funktion’ i träningsprocessen, men inte tillräckligt frekvent för att generalisera användbart i den bredare datamängden. Utan en mekanism för att rabattera inflytandet från de artificiella markörerna, kunde de potentiellt betraktas av maskinlärnings-systemets metod som patologiska fenomen.
Träning och testning
Forskarna testade COVIDx mot två jämförbara datamängder över tre modeller. De extra två datamängderna var RICORD, som innehåller 1096 COVID-19-bröstkorgsröntgenbilder över 361 patienter, hämtade från fyra länder; och CheXpert, en offentlig datamängd
De tre modellerna som användes var COVID-Net, CoroNet och DarkCovidNet. Alla tre modellerna använder Convolutional Neural Networks (CNN), även om CoroNet består av en tvåstegs bildklassificeringsprocess, med autoencoders som skickar utdata till en CNN-klassificerare.
Testningen visade en ‘brant nedgång’ i alla modellers prestanda på icke-COVIDx-dataset jämfört med den 86% noggrannhet som resulterade när COVIDx-data användes. Men om datan är felaktigt etiketterad eller felaktigt grupperad, är dessa effektivt falska resultat. Forskarna noterade kraftigt minskade noggrannhetsresultat på de jämförbara externa datamängderna, som artikeln föreslår som mer realistiska och korrekt klassificerade data.
Dessutom observerar artikeln:
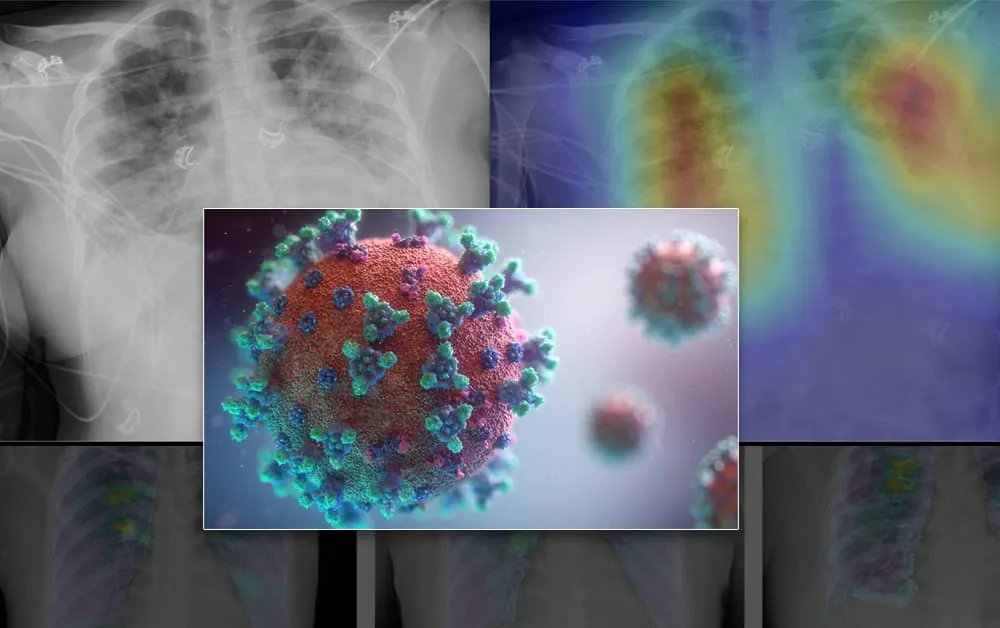
‘En klinisk granskning av 500 grad-CAM-salienskarta som genererats av förutsägelse på COVIDx-testdata visade en trend av signifikans i kliniskt irrelevanta funktioner. Detta inkluderade vanligtvis fokus på benstrukturer och mjukvävnader snarare än diffus bilateral opacifiering av lungfälten som är typiska för COVID-19-infektion.’

Detta är en röntgenbild av ett bekräftat COVID-19-fall, tilldelad en förutsägelse-sannolikhet på 0,938 från COVIDx tränad på DarkCovidNet.
Slutsatser
Forskarna kritiserar bristen på demografisk eller klinisk data relaterad till röntgenbilderna i COVIDx, och hävdar att utan dessa är det omöjligt att ta hänsyn till ‘sammanblandningsfaktorer’ som ålder.
De observerar också att problemen som påträffats i COVIDx-databasen kan vara tillämpliga på andra datamängder som samlades in på liknande sätt (dvs genom att blanda pre-COVID-radiologiska bildbanker med nyligen COVID-röntgenbilder utan tillräcklig dataarkitektur, varianskompensation och tydlig omfattning av begränsningarna för denna metod).
I sammanfattning av bristerna i COVIDx, betonar forskarna den ensidiga inklusionen av ‘tydliga’ pediatriska röntgenbilder, samt deras uppfattning om missbruk av etiketter och hög risk för bias och sammanblandning i COVIDx, och hävdar att ‘den exceptionella prestationen [av COVIDx] som rapporteras brett över problemområdet är överdriven, att modellprestationsresultat är missrepresenterade, och att modellerna inte generaliserar bra till kliniskt realistiska data.’
Rapporten slutsats:
‘En brist på tillgängliga sjukhusdata kombinerat med otillräcklig modellutvärdering över problemområdet har tillåtit användningen av öppen källkodsdata att vilseleda forskarsamhället. Fortsatt publicering av överdrivna modellprestandamått riskerar att skada tillförlitligheten i AI-forskning inom medicinsk diagnostik, särskilt där sjukdomen är av stort allmänintresse. Forskningskvaliteten inom detta område måste förbättras för att förhindra att detta händer, och detta måste börja med datan.’
*Även om forskarna i studien hävdar att de har gjort datan, filerna och koden för den nya artikeln tillgänglig online, kräver åtkomst inloggning, och vid tidpunkten för skrivningen fanns det ingen allmän åtkomst till filerna.
** ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases – https://arxiv.org/pdf/1705.02315.pdf












