Artificiell intelligens
Utvecklingen av AI-resonemang: Från kedjor till iterativa och hierarkiska strategier
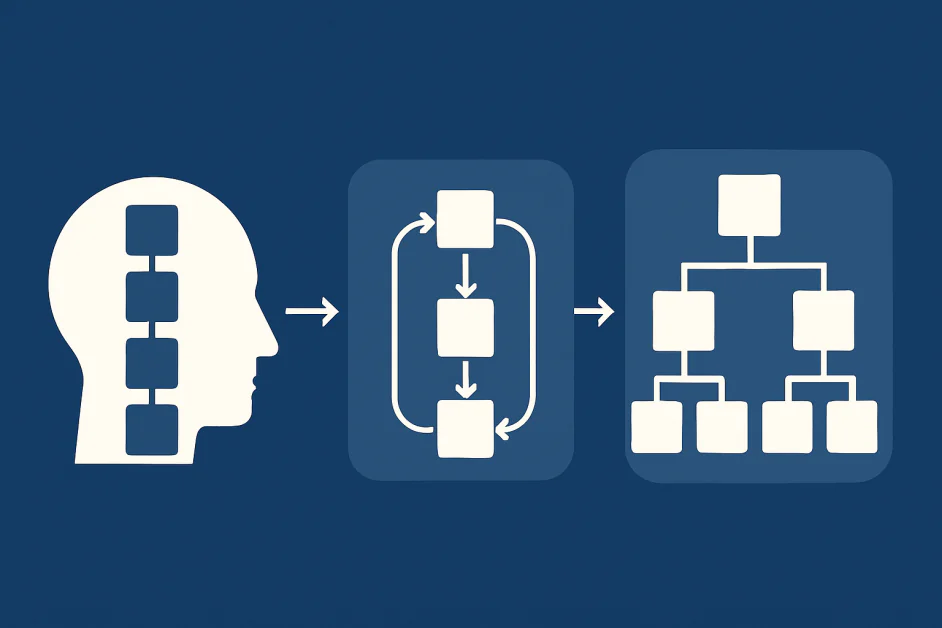
Under de senaste åren har chain-of-thought prompting blivit den centrala metoden för resonemang i stora språkmodeller. Genom att uppmuntra modellerna att “tänka högt”, fann forskarna att steg-för-steg-förklaringar förbättrar noggrannheten inom områden som matematik och logik. Men när uppgifterna blir mer komplexa, blir begränsningarna av CoT tydliga. Beroendet av CoT till noggrant utvalda exempel på resonemang gör det svårt att hantera uppgifter som är antingen för enkla eller svårare än exemplen. Medan CoT introducerade strukturerat tänkande i språkmodeller, kräver fältet nu nya tillvägagångssätt som kan hantera komplexa, multi-stegsproblem med varierande komplexitet. Som ett resultat är forskare nu i färd med att utforska nya strategier som iterativ och hierarkisk resonemang. Dessa metoder syftar till att göra resonemang djupare, mer effektivt och mer robust. Den här artikeln förklarar begränsningarna av CoT, utforskar utvecklingen av CoT och tittar på tillämpningar, utmaningar och framtida riktningar för att skala upp AI-resonemang.
Begränsningarna av Chain-of-Thought
CoT-resonemang hjälpte modellerna att hantera komplexa uppgifter genom att bryta ner dem i mindre steg. Denna förmåga förbättrade inte bara benchmarkresultat i matematiktävlingar, logikpussel och programmeringsuppgifter, utan gav också en viss transparens genom att exponera mellanliggande steg. Trots dessa fördelar är CoT dock inte utan utmaningar. Forskning visar att CoT fungerar bäst på problem som kräver symboliskt resonemang eller exakt beräkning. Men för öppna frågor, sunt förnuft-resonemang eller faktisk återkallning, lägger det ofta till lite eller till och med minskar noggrannheten.
CoT är i sig linjärt till sin natur. Modellen genererar en enda sekvens av steg som leder till ett svar. Detta fungerar bra för korta, väldefinierade problem, men kämpar när uppgifterna kräver djupare utforskning. Dessutom involverar komplext resonemang ofta grenar, backtracking och omprövning av antaganden. En enda linjär kedja kan inte fånga detta. Om modellen gör ett tidigt misstag, kollapsar alla efterföljande steg. Även när resonemanget är korrekt, kan linjära utdata inte anpassa sig till ny information eller ompröva tidigare antaganden. Verkligt resonemang kräver flexibilitet som CoT inte tillhandahåller.
Forskare betonar också skalningsproblem. När modellerna står inför svårare uppgifter, blir kedjorna längre och mer sköra. Att sampla flera kedjor kan hjälpa, men det blir snabbt ineffektivt. Frågan är hur man kan gå från smal, enkelvägs-resonemang till mer robusta strategier.
Iterativt resonemang som nästa steg
En lovande riktning är iteration. Istället för att producera ett slutgiltigt svar i ett enda steg, engagerar sig modellen i cykler av resonemang, utvärdering och förfining. Detta speglar hur människor löser svåra problem genom att först skissa en lösning, kontrollera den, identifiera svagheter och förbättra den steg för steg.
Iterativa metoder tillåter modeller att återhämta sig från misstag och utforska alternativa lösningar. De skapar en återkopplingsloop där modellen kritiserar sitt eget resonemang, eller där flera modeller kritiserar varandra. En kraftfull idé är självkonsekvens. Istället för att lita på en kedja av tankar, sampar modellen många resonemangsbanor och väljer sedan den vanligaste svaret. Detta imiterar en student som försöker lösa ett problem på flera sätt innan han litar på ett svar. Forskning har visat att aggregat av flera resonemangsbanor förbättrar tillförlitligheten. Mer senaste arbete utvidgar denna idé till strukturerade iterationer där utdata kontinuerligt kontrolleras, korrigeras och utvidgas.
Denna förmåga möjliggör också att modeller kan använda externa verktyg. Iteration gör det lättare att integrera sökmotorer, lösningsverktyg eller minnessystem i loopen. Istället för att åta sig ett enda svar, kan modellen fråga externa resurser, ompröva sitt resonemang och revidera sina steg. Iteration förvandlar resonemang till en dynamisk process snarare än en statisk kedja.
Hierarkiska tillvägagångssätt för komplexitet
Iteration ensam räcker inte när uppgifterna växer mycket stora. För problem som kräver långa horisonter eller multi-stegsplanering, blir hierarki avgörande. Människor använder hierarkiskt resonemang hela tiden. Vi bryter ner uppgifter i underproblem, sätter mål och arbetar igenom dem i strukturerade lager. Modeller behöver samma förmåga.
Hierarkiska metoder tillåter en modell att bryta ner en uppgift i mindre steg och lösa dem parallellt eller i sekvens. Forskning om program-of-thought och tree-of-thoughts betonar denna riktning. Istället för en platt kedja, organiseras resonemang som ett träd eller graf där flera banor kan utforskas och beskäras. Detta möjliggör att söka igenom olika strategier och välja den mest lovande. I denna riktning är en ny utveckling Forest-of-Thought-ramverket, som lanserar många resonemang “träd” samtidigt och använder konsensus och felkorrektion över dem. Varje träd kan utforska en annan bana; träd som verkar opassande beskärs, medan självkorrektionsmekanismer låter modellen upptäcka och korrigera fel i någon gren. Genom att kombinera röster från alla träd, fattar modellen ett kollektivt beslut.
Hierarki möjliggör också samordning. Stora uppgifter kan distribueras över agenter som hanterar olika delar av problemet. En agent kan fokusera på planering, en annan på beräkning och en annan på verifikation. Resultaten kan sedan integreras i en sammanhängande lösning. Tidiga experiment i multi-agent resonemang tyder på att en sådan uppdelning av arbete kan överträffa single-chain-metoder.
Verifikation och tillförlitlighet
En annan styrka med iterativa och hierarkiska strategier är att de naturligt tillåter verifikation. Chain-of-thought exponerar resonemangssteg, men det garanterar inte deras korrekthet. Med iterativa loopar kan modeller kontrollera sina egna steg eller ha dem kontrollerade av andra modeller. Med hierarki kan olika nivåer verifieras oberoende.
Detta öppnar dörren till strukturerad utvärdering pipelines. Till exempel kan en modell generera kandidatlösningar på en lägre nivå, medan en högre nivå-kontroller väljer eller förfinar dem. Eller en extern verifierare kan testa utdata mot begränsningar innan de accepteras. Dessa mekanismer gör resonemang mindre skört och mer tillförlitligt.
Verifikation handlar inte bara om noggrannhet. Det förbättrar också tolkbarhet. Genom att organisera resonemang i lager eller iterationer, kan forskare lättare inspektera var fel uppstår. Detta stöder både felsökning och justering, vilket ger utvecklare mer kontroll över hur modeller resonemang.
Tillämpningar
Avancerade resonemangsstrategier används redan i hela fält. Inom vetenskapen stöder de problemlösning i avancerad matematik och till och med hjälper till att utarbeta forskningsförslag. Inom programmering presterar modeller nu bra i tävlingar, felsökning och fullständiga programvaruutvecklingscykler.
Juridiska och affärsområden dra nytta av komplex kontraktsanalys och strategisk planering. Agenta AI-system kombinerar resonemang med verktygsanvändning, hanterar multi-stegsoperationer över API:er, databaser och webben. Inom utbildning kan tutorprogram förklara koncept steg för steg och ge personlig vägledning.
Utmaningar och öppna frågor
Trots de lovande resultaten från iterativa och hierarkiska metoder, finns det fortfarande många utmaningar att hantera. En av dem är effektivitet. Iterativa loopar och träd-sökning kan vara beräkningsmässigt dyra. Att balansera noggrannhet med hastighet är ett öppet problem.
En annan utmaning är kontroll. Att säkerställa att modeller följer användbara strategier snarare än att driva in i oproduktiva loopar är svårt. Forskare utforskar metoder för att vägleda resonemang med heuristiker, planeringsalgoritmer eller inlärda kontroller, men fältet är fortfarande ungt.
Utvärdering är också en öppen fråga. Traditionella noggrannhetsbenchmark-tester fångar bara resultat, inte kvaliteten på resonemangsprocesser. Nya utvärderingsramverk behövs för att mäta robusthet, anpassningsförmåga och transparens i resonemangsstrategier.
Slutligen finns det justeringsproblem. Iterativt och hierarkiskt resonemang kan förstärka både styrkor och svagheter hos modeller. Medan de kan göra resonemang mer tillförlitligt, gör de det också svårare att förutsäga hur modeller kommer att bete sig i öppna scenarier. Omsorgsfull design och tillsyn är nödvändiga för att undvika nya risker.
Sammanfattning
Chain-of-thought öppnade dörren till strukturerat resonemang i AI, men dess linjära begränsningar är tydliga. Framtiden ligger i iterativa och hierarkiska strategier som gör resonemang mer anpassningsbart, verificerbart och skalbart. Genom att använda cykler av förfining och lagd problemlösning, kan AI gå från sköra steg-för-steg-kedjor till robusta, dynamiska resonemangssystem som kan hantera verklig komplexitet.












