
Umetna inteligenca
Trije izzivi za stabilno difuzijo

O sprostitev stabilnosti.ai's Stable Diffusion latentna difuzija model sinteze slike pred nekaj tedni je morda eno najpomembnejših tehnoloških razkritij od DeCSS leta 1999; to je zagotovo največji dogodek na področju posnetkov, ustvarjenih z umetno inteligenco, od leta 2017 koda deepfakes je bil kopiran na GitHub in razdeljen na to, kar bo postalo DeepFaceLab in Zamenjava obraza, kot tudi programsko opremo deepfake za pretakanje v realnem času DeepFaceLive.
Ob možganski kapi, razočaranje uporabnika več vsebinske omejitve v API-ju za sintezo slike DALL-E 2 so bili pometeni na stran, saj se je izkazalo, da je mogoče filter NSFW Stable Diffusion onemogočiti s spremembo edina vrstica kode. Stable Diffusion Reddits, osredotočen na pornografijo, so se pojavili skoraj takoj in so bili prav tako hitro zmanjšani, medtem ko sta se tabor razvijalcev in uporabnikov razdelila na Discordu na uradno in NSFW skupnost, Twitter pa se je začel polniti s fantastičnimi stvaritvami Stable Diffusion.
Trenutno se zdi, da vsak dan prinaša nekaj osupljivih inovacij razvijalcev, ki so sprejeli sistem, z vtičniki in dodatki tretjih oseb, ki so na hitro napisani za Krita, photoshop, Cinema4D, Blenderin številne druge aplikacijske platforme.

Medtem, promptcraft – zdaj profesionalna umetnost »šepetanja z umetno inteligenco«, ki bo morda na koncu postala najkrajša karierna možnost od »Filofax binderja« – že postaja komercializirano, medtem ko zgodnja monetizacija Stable Diffusion poteka na Raven Patreona, z gotovostjo, da prihajajo bolj izpopolnjene ponudbe za tiste, ki ne želijo krmariti Temelji na Condi namestitve izvorne kode ali proskriptivnih filtrov NSFW spletnih izvedb.
Hitrost razvoja in svobodnega čuta za raziskovanje uporabnikov potekata s tako vrtoglavo hitrostjo, da je težko videti zelo daleč naprej. V bistvu še ne vemo natančno, s čim imamo opravka, niti katere vse so omejitve ali možnosti.
Kljub temu si poglejmo tri izmed najbolj zanimivih in najzahtevnejših ovir za hitro oblikovano in hitro rastočo skupnost Stable Diffusion, s katerimi se mora soočiti in, upajmo, premagati.
1: Optimizacija cevovodov na podlagi ploščic
Ker so predstavljeni z omejenimi viri strojne opreme in strogimi omejitvami ločljivosti slik za usposabljanje, se zdi verjetno, da bodo razvijalci našli rešitve za izboljšanje kakovosti in ločljivosti izhoda stabilne difuzije. Veliko teh projektov naj bi vključevalo izkoriščanje omejitev sistema, kot je njegova izvorna ločljivost le 512 × 512 slikovnih pik.
Kot se vedno zgodi pri pobudah za računalniški vid in sintezo slik, je bila Stable Diffusion naučena na slikah kvadratnega razmerja, v tem primeru ponovno vzorčenih na 512 × 512, tako da je bilo mogoče izvorne slike urediti in prilagoditi omejitvam GPU-jev, ki usposobil model.
Zato Stable Diffusion 'misli' (če sploh misli) v 512×512 izrazih in vsekakor v kvadratih. Številni uporabniki, ki trenutno preizkušajo meje sistema, poročajo, da stabilna difuzija daje najbolj zanesljive rezultate z najmanj napakami pri tem precej omejenem razmerju stranic (glejte 'obravnavanje skrajnosti' spodaj).
Čeprav različne izvedbe omogočajo nadgradnjo prek RealESRGAN (in lahko popravi slabo upodobljene obraze prek GFPGAN) več uporabnikov trenutno razvija metode za razdelitev slik na dele velikosti 512 x 512 slikovnih pik in sestavljanje slik v večja sestavljena dela.

Ta upodobitev 1024 × 576, ločljivost, ki je običajno nemogoča v enem samem upodobitvi Stable Diffusion, je bila ustvarjena s kopiranjem in lepljenjem datoteke Python attention.py iz DoggettX fork Stable Diffusion (različica, ki izvaja povečanje velikosti na podlagi ploščic) v drugo fork. Vir: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Čeprav nekatere tovrstne pobude uporabljajo izvirno kodo ali druge knjižnice, je vrata txt2imghd GOBIG (način v ProgRockDiffusion, ki je lačen VRAM-a) naj bi kmalu zagotovil to funkcionalnost glavni veji. Medtem ko je txt2imghd namenska vrata GOBIG-a, druga prizadevanja razvijalcev skupnosti vključujejo različne implementacije GOBIG-a.

Priročna abstraktna slika v izvirnem upodabljanju 512 x 512 slikovnih pik (levo in drugi z leve); nadgradil ESGRAN, ki je zdaj bolj ali manj izviren v vseh distribucijah Stable Diffusion; in jim je bila posvečena 'posebna pozornost' z implementacijo GOBIG-a, ki proizvaja podrobnosti, ki se vsaj v mejah slikovnega odseka zdijo izboljšane. Svir: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Vrsta abstraktnega primera, predstavljenega zgoraj, ima številna 'majhna kraljestva' podrobnosti, ki ustrezajo temu solipsističnemu pristopu k povečanju ločljivosti, vendar lahko zahtevajo zahtevnejše rešitve, ki temeljijo na kodi, da bi ustvarili neponavljajoče se, kohezivno višanje ločljivosti, ki ne poglej kot da je sestavljen iz mnogih delov. Nenazadnje tudi v primeru človeških obrazov, kjer smo neobičajno naravnani na aberacije ali 'treskajoče' artefakte. Zato bodo obrazi sčasoma morda potrebovali namensko rešitev.
Stabilna difuzija trenutno nima mehanizma za osredotočanje pozornosti na obraz med upodabljanjem na enak način, kot ljudje dajejo prednost obraznim informacijam. Čeprav nekateri razvijalci v skupnostih Discord razmišljajo o metodah za implementacijo te vrste "izboljšane pozornosti", je trenutno veliko lažje ročno (in sčasoma samodejno) izboljšati obraz po izvedbi začetnega upodabljanja.
Človeški obraz ima notranjo in popolno semantično logiko, ki je ne bo mogoče najti v 'ploščici' v spodnjem kotu (na primer) stavbe, zato je trenutno mogoče zelo učinkovito 'povečati' in ponovno upodobiti 'sketchy' obraz v izhodu Stable Diffusion.

Levo, prvi poskus Stable Diffusion s pozivom 'Barvna fotografija v polni dolžini Christine Hendricks, ki vstopa v prostor z veliko ljudi, oblečena v dežni plašč; Canon50, očesni stik, visoke podrobnosti, visoke podrobnosti obraza'. Desno, izboljšan obraz, pridobljen tako, da se zamegljeni in nedorečeni obraz iz prvega upodabljanja vrne v celotno pozornost Stable Diffusion z uporabo Img2Img (glejte animirane slike spodaj).
Ker ni namenske rešitve Textual Inversion (glejte spodaj), bo to delovalo samo za slike slavnih, kjer je zadevna oseba že dobro zastopana v podatkovnih podnaborih LAION, ki so usposobili Stable Diffusion. Zato bo deloval na podobnih Tomu Cruisu, Bradu Pittu, Jennifer Lawrence in omejenem naboru pristnih medijskih svetil, ki so prisotni v velikem številu slik v izvornih podatkih.
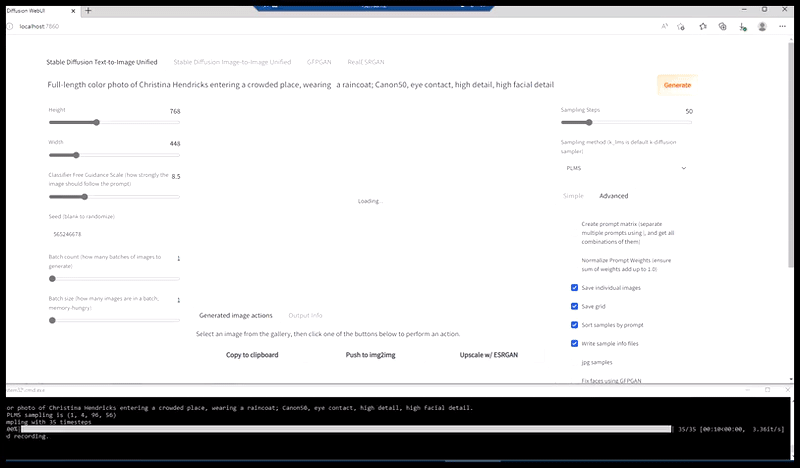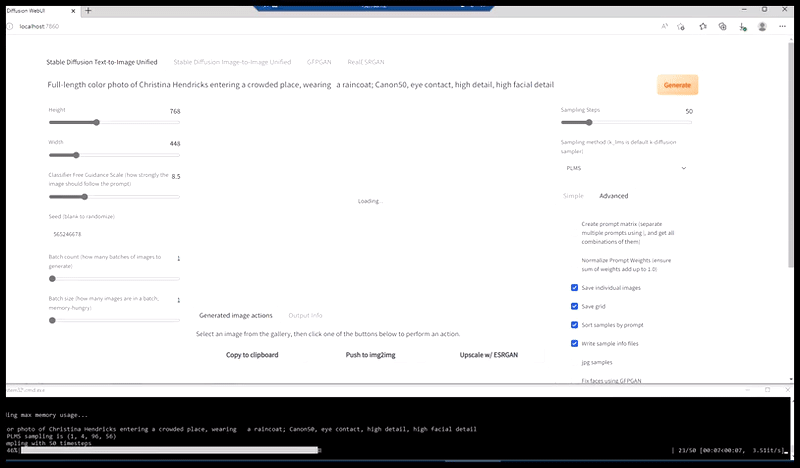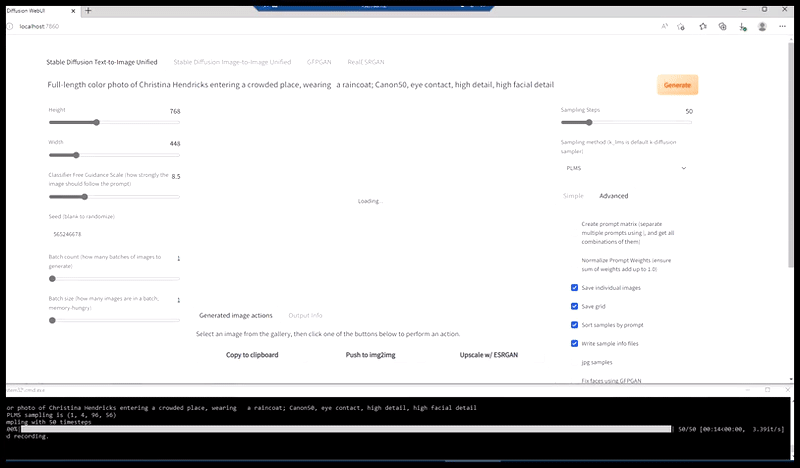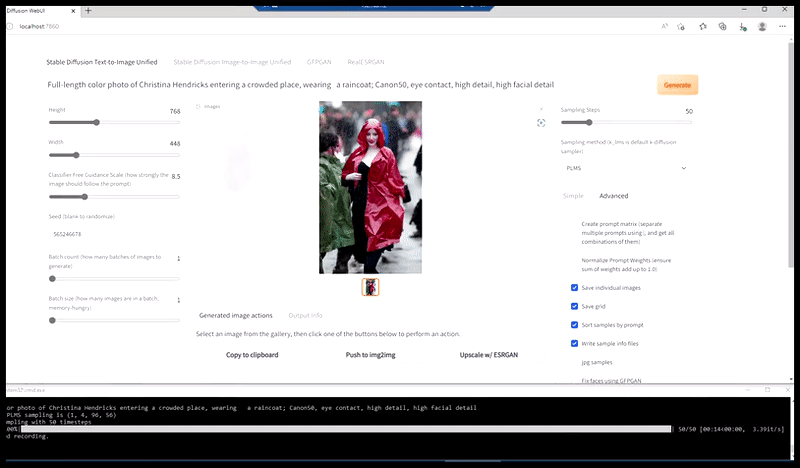
Ustvarjanje verjetne novinarske slike s pozivom 'Barvna fotografija v polni dolžini Christine Hendricks, ki vstopa v prostor, kjer je veliko ljudi, oblečena v dežni plašč; Canon50, očesni stik, visoke podrobnosti, visoke podrobnosti obraza'.
Za znane osebnosti z dolgo in trajno kariero bo Stabilna difuzija običajno ustvarila podobo osebe v nedavni (tj. starejši) starosti, zato bo treba dodati takojšnje dodatke, kot je npr. 'mlad' or 'v letu [YEAR]' za ustvarjanje podob mlajšega videza.

Igralka Jennifer Connelly je z vidno, veliko fotografirano in dosledno kariero, ki traja skoraj 40 let, ena izmed peščice slavnih osebnosti v LAION-u, zaradi katerih Stable Diffusion predstavlja različne starosti. Vir: predpakirana stabilna difuzija, lokalno, kontrolna točka v1.4; namigi, povezani s starostjo.
To je predvsem posledica širjenja digitalne (namesto drage, na emulziji temelječe) tiskovne fotografije od sredine 2000-ih naprej in poznejšega povečanja obsega izhodnih slik zaradi povečanih širokopasovnih hitrosti.
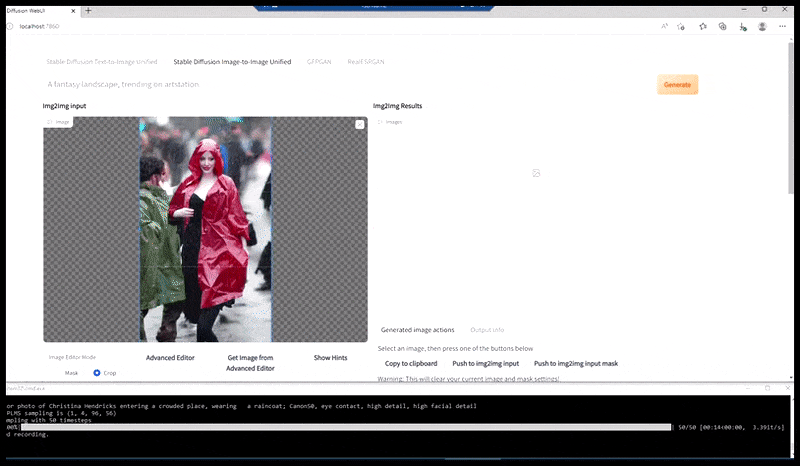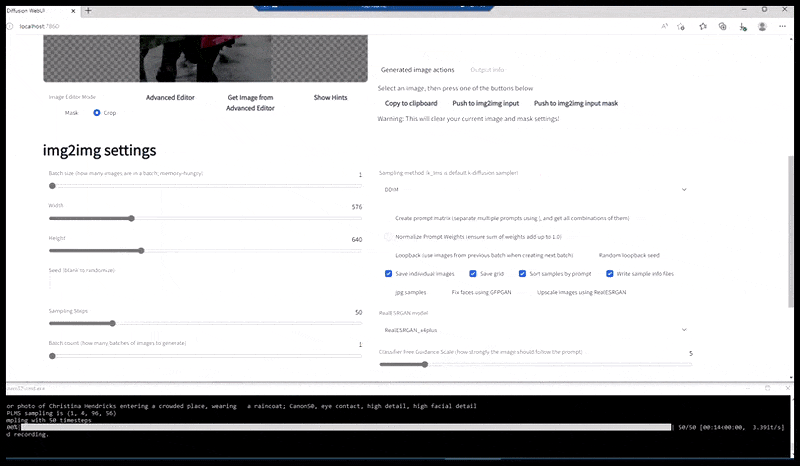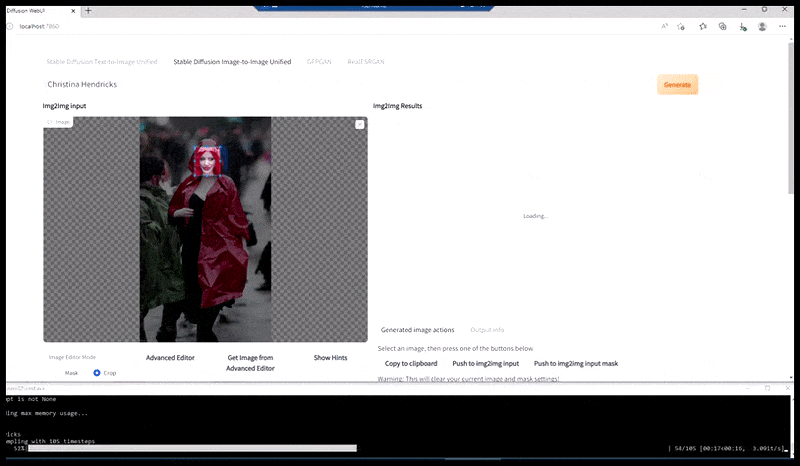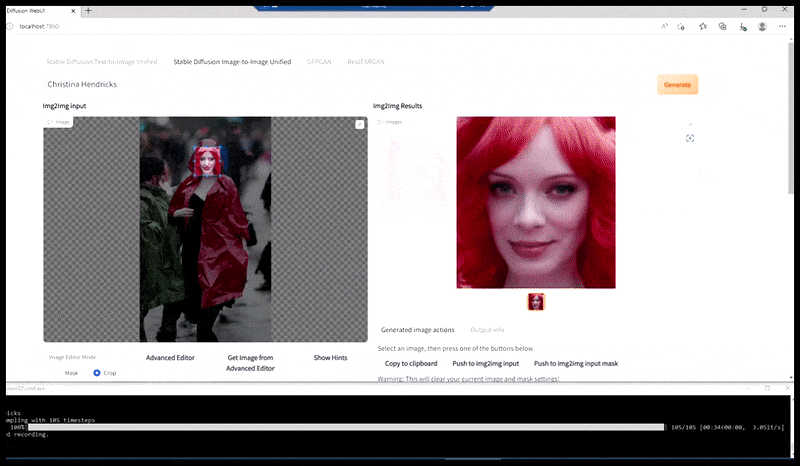
Upodobljena slika se prenese v Img2Img v Stable Diffusion, kjer je izbrano 'območje ostrenja' in nova upodobitev največje velikosti se naredi samo za to področje, kar Stable Diffusion omogoča, da vse razpoložljive vire osredotoči na ponovno ustvarjanje obraza.
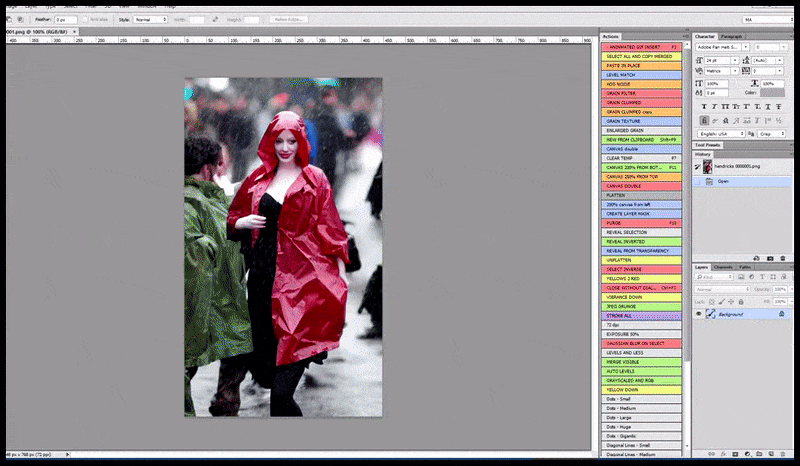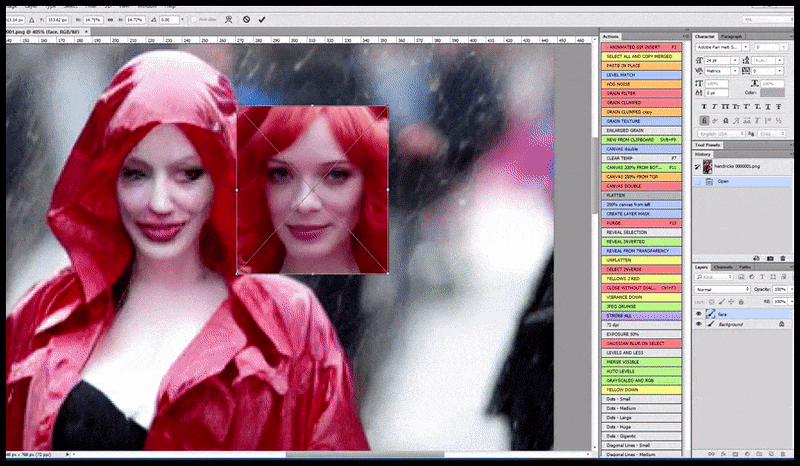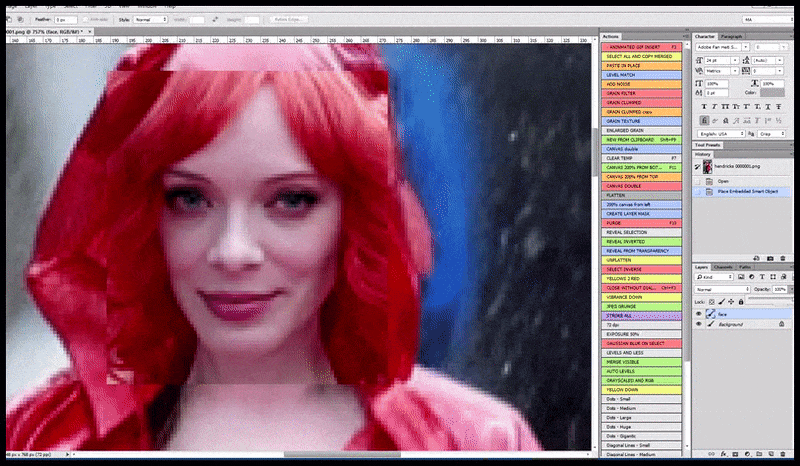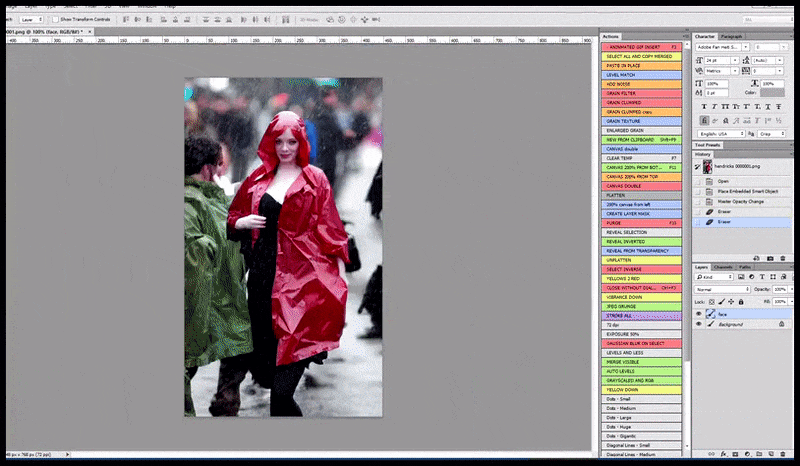
Sestavljanje obraza »visoke pozornosti« nazaj v izvirno upodobitev. Poleg obrazov bo ta postopek deloval samo z entitetami, ki imajo potencialno znan, koheziven in celovit videz, kot je del izvirne fotografije, ki ima poseben predmet, kot je ura ali avto. Povečanje velikosti odseka – na primer – stene bo vodilo do zelo nenavadnega videza ponovno sestavljene stene, ker upodobitve ploščic niso imele širšega konteksta za ta 'kos sestavljanke', ko so upodabljale.
Nekatere znane osebnosti v zbirki podatkov pridejo 'vnaprej zamrznjene' v času, bodisi zato, ker so zgodaj umrle (kot je Marilyn Monroe), bodisi zato, ker so postale le bežna glavna prepoznavnost in ustvarile veliko količino slik v omejenem časovnem obdobju. Polling Stable Diffusion verjetno zagotavlja nekakšen 'trenutni' indeks priljubljenosti za sodobne in starejše zvezde. Za nekatere starejše in sedanje znane osebnosti v izvornih podatkih ni dovolj slik, da bi dobili zelo dobro podobnost, medtem ko trajna priljubljenost določenih že davno umrlih ali drugače obledelih zvezd zagotavlja, da je njihovo razumno podobnost mogoče pridobiti iz sistema.

Upodobitve Stable Diffusion hitro razkrijejo, kateri znani obrazi so dobro predstavljeni v podatkih za usposabljanje. Kljub njeni ogromni priljubljenosti kot starejša najstnica v času pisanja je bila Millie Bobby Brown mlajša in manj znana, ko so bili izvorni nabori podatkov LAION postrgani iz spleta, zaradi česar je visokokakovostna podobnost s stabilno difuzijo trenutno problematična.
Kjer so podatki na voljo, bi lahko rešitve s povečano ločljivostjo na podlagi ploščic v Stable Diffusion segle dlje od usmerjanja na obraz: potencialno bi lahko omogočile še natančnejše in podrobnejše obraze z razbitjem obraznih potez in obračanjem celotne moči lokalne GPE vire o pomembnih značilnostih posamično, pred ponovnim sestavljanjem – proces, ki je trenutno spet ročni.

To ni omejeno na obraze, ampak je omejeno na dele objektov, ki so vsaj tako predvidljivo umeščeni v širši kontekst gostiteljskega objekta in ki ustrezajo vdelavam na visoki ravni, za katere bi lahko razumno pričakovali, da jih bodo našli v hiperskali. nabor podatkov.
Prava omejitev je količina razpoložljivih referenčnih podatkov v naboru podatkov, ker bodo sčasoma globoko ponavljane podrobnosti postale popolnoma 'halucinirane' (tj. izmišljene) in manj verodostojne.
Takšne zrnate povečave na visoki ravni delujejo v primeru Jennifer Connelly, ker je dobro zastopana v različnih starostih v LAION-estetika (primarna podmnožica LAION 5B ki jih uporablja Stable Diffusion) in na splošno v LAION; v mnogih drugih primerih bi bila natančnost prizadeta zaradi pomanjkanja podatkov, kar bi zahtevalo fino nastavitev (dodatno usposabljanje, glejte 'Prilagajanje' spodaj) ali besedilno inverzijo (glejte spodaj).
Ploščice so zmogljiv in razmeroma poceni način za omogočanje stabilne difuzije za ustvarjanje izhoda visoke ločljivosti, toda algoritemsko večanje po ploščicah te vrste, če nima nekakšnega širšega mehanizma pozornosti na višji ravni, morda ne bo doseglo pričakovanega – za standarde v različnih vrstah vsebine.
2: Reševanje težav s človeškimi udi
Stabilna difuzija ne upraviči svojega imena, ko prikazuje kompleksnost človeških okončin. Roke se lahko naključno množijo, prsti se združijo, tretje noge so nepovabljene in obstoječi udi izginejo brez sledi. V svojo obrambo si Stable Diffusion deli težavo s svojimi stabilnimi kolegi in vsekakor z DALL-E 2.

Neurejeni rezultati iz DALL-E 2 in Stable Diffusion (1.4) konec avgusta 2022, ki kažejo težave z udi. Poziv je "Ženska v objemu moškega"
Oboževalci Stable Diffusion, ki upajo, da bo prihajajoča kontrolna točka 1.5 (bolj intenzivno trenirana različica modela z izboljšanimi parametri) rešila zmedo okončin, bodo verjetno razočarani. Novi model, ki bo izšel v približno dva tedna časa, je trenutno premierno predstavljen na portalu komercialne stabilnosti.ai sanjski studio, ki privzeto uporablja 1.5 in kjer lahko uporabniki primerjajo nov rezultat z upodobitvami iz svojih lokalnih ali drugih sistemov 1.4:

Vir: lokalni predpak 1.4 in https://beta.dreamstudio.ai/

Vir: lokalni predpak 1.4 in https://beta.dreamstudio.ai/

Vir: lokalni predpak 1.4 in https://beta.dreamstudio.ai/
Kot se pogosto zgodi, je lahko glavni vzrok za to kakovost podatkov.
Odprtokodne baze podatkov, ki spodbujajo sisteme za sintezo slik, kot sta Stable Diffusion in DALL-E 2, lahko zagotovijo številne oznake za posamezne ljudi in medčloveška dejanja. Te oznake se simbiotično usposobijo za svoje povezane slike ali segmente slik.

Uporabniki Stable Diffusion lahko raziskujejo koncepte, usposobljene v modelu, tako da poizvedujejo po naboru podatkov LAION-aesthetics, podnaboru večjega nabora podatkov LAION 5B, ki poganja sistem. Slike niso razvrščene po abecednem vrstnem redu, temveč po 'estetski oceni'. Vir: https://rom1504.github.io/clip-retrieval/
A dobra hierarhija posameznih oznak in razredov, ki prispevajo k upodobitvi človeške roke, bi bilo nekaj podobnega telo>roka>roka>prsti>[podštevki + palec]> [številčni segmenti]>Nohti.

Zrnata pomenska segmentacija delov roke. Celo ta nenavadno podrobna dekonstrukcija pusti vsak 'prst' kot eno samo entiteto, ne da bi upoštevala tri dele prsta in dva dela palca. Vir: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
V resnici je malo verjetno, da bodo izvorne slike tako dosledno označene v celotnem naboru podatkov in nenadzorovani algoritmi za označevanje se bodo verjetno ustavili pri več na ravni – na primer – 'roke' in pustite notranje slikovne pike (ki tehnično vsebujejo informacije o 'prstu') kot neoznačeno maso slikovnih pik, iz katere bodo poljubno izpeljane funkcije in ki se lahko v poznejših upodobitvah pokažejo kot moteč element.

Kako bi moralo biti (zgoraj desno, če ne zgoraj) in kako je (spodaj desno), zaradi omejenih virov za označevanje ali arhitekturnega izkoriščanja takih oznak, če obstajajo v naboru podatkov.
Torej, če model latentne difuzije pride tako daleč, da upodablja roko, bo skoraj zagotovo poskusil upodabljati roko na koncu te roke, ker roka> roka je minimalna zahtevana hierarhija, dokaj visoko v tem, kar arhitektura ve o 'človeški anatomiji'.
Po tem so lahko 'prsti' najmanjša skupina, čeprav obstaja še 14 dodatnih poddelov prstov/palcev, ki jih je treba upoštevati pri upodabljanju človeških rok.
Če ta teorija drži, ni prave rešitve zaradi pomanjkanja proračuna za ročno označevanje v celotnem sektorju in pomanjkanja ustrezno učinkovitih algoritmov, ki bi lahko avtomatizirali označevanje in hkrati povzročili nizke stopnje napak. Pravzaprav se model trenutno morda zanaša na človeško anatomsko doslednost, da bi prikril pomanjkljivosti nabora podatkov, na katerem je bil usposobljen.
Eden od možnih razlogov, zakaj ne morem zanašati se na to, pred kratkim predlagano pri Stable Diffusion Discord, je, da bi se model lahko zmedel glede pravilnega števila prstov, ki bi jih morala imeti (realistična) človeška roka, ker podatkovna zbirka, ki izhaja iz LAION-a, ki jo poganja, prikazuje risane like, ki imajo morda manj prstov (kar je samo po sebi bližnjica, ki prihrani delo).

Dva potencialna krivca za sindrom "manjkajočega prsta" v stabilni difuziji in podobnih modelih. Spodaj so primeri risanih rok iz nabora podatkov LAION-aesthetics, ki poganja Stable Diffusion. Vir: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Če je to res, potem je edina očitna rešitev ponovno usposabljanje modela, izključitev nerealistične vsebine, ki temelji na ljudeh, in zagotovitev, da so resnični primeri opustitve (tj. amputacije) ustrezno označeni kot izjeme. Samo z vidika kuriranja podatkov bi bil to precejšen izziv, zlasti za prizadevanja skupnosti s pomanjkanjem virov.
Drugi pristop bi bil uporaba filtrov, ki preprečijo, da bi se taka vsebina (tj. 'roka s tremi/petimi prsti') prikazala v času upodabljanja, na približno enak način, kot je OpenAI do določene mere filtrirali GPT-3 in DALL-E2, tako da je mogoče njihov izhod regulirati, ne da bi bilo treba ponovno usposobiti izvorne modele.

Pri Stable Diffusion lahko semantično razlikovanje med prsti in celo okončinami postane grozljivo zamegljeno, kar prikliče v spomin niz grozljivk o telesnih grozljivkah iz osemdesetih let, kot je David Cronenberg. Vir: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Vendar pa bi to znova zahtevalo oznake, ki morda ne obstajajo na vseh prizadetih slikah, zaradi česar imamo isti logistični in proračunski izziv.
Lahko bi trdili, da obstajata še dve poti naprej: vnašanje več podatkov v problem in uporaba sistemov za razlago tretjih oseb, ki lahko posredujejo, ko so fizične neumnosti, kot je opisana tukaj, predstavljene končnemu uporabniku (vsaj slednji bi OpenAI dal metodo za zagotavljanje povračil za upodobitve 'telesnih grozljivk', če bi bilo podjetje za to motivirano).
3: Prilagajanje
Ena najbolj vznemirljivih možnosti za prihodnost Stable Diffusion je možnost, da bodo uporabniki ali organizacije razvili revidirane sisteme; spremembe, ki omogočajo integracijo vsebine zunaj vnaprej pripravljene sfere LAION v sistem – v idealnem primeru brez neobvladljivih stroškov ponovnega usposabljanja celotnega modela ali tveganja, ki ga povzroča usposabljanje velike količine novih slik za obstoječe, zrele in sposobne model.
Po analogiji: če se dva manj nadarjena učenca pridružita naprednemu razredu tridesetih učencev, se bosta bodisi asimilirala in dohitela ali pa bosta padla kot izstopajoča; v obeh primerih to verjetno ne bo vplivalo na povprečno zmogljivost razreda. Če pa se pridruži 15 manj nadarjenih učencev, bo krivulja ocen za celoten razred verjetno prizadeta.
Podobno je lahko sinergistično in dokaj občutljivo omrežje odnosov, ki je zgrajeno s trajnim in dragim usposabljanjem modela, ogroženo, v nekaterih primerih dejansko uničeno, s prekomerno količino novih podatkov, kar zniža kakovost izhoda za model na vseh področjih.
Primer za to je predvsem tam, kjer je vaš interes v popolni ugrabitvi modelovega konceptualnega razumevanja odnosov in stvari ter njegovem prilastitvi za izključno produkcijo vsebine, ki je podobna dodatnemu materialu, ki ste ga dodali.
Tako usposabljanje 500,000 Simpsons okvirjev v obstoječo kontrolno točko stabilne difuzije vam bo sčasoma verjetno prineslo boljše Simpsons simulator, kot bi ga lahko ponudila izvirna zgradba, ob predpostavki, da dovolj široka semantična razmerja preživijo proces (tj. Homer Simpson jé hotdog, ki lahko zahteva gradivo o hrenovkah, ki ga ni bilo v vašem dodatnem gradivu, vendar je že obstajalo v kontrolni točki), in ob predpostavki, da ne želite nenadoma preklopiti iz Simpsons vsebine za ustvarjanje čudovita pokrajina Grega Rutkowskega – ker je bila pozornost vašemu modelu po usposabljanju močno preusmerjena in ne bo več tako dober pri opravljanju takšnih stvari, kot je bil.
Eden opaznih primerov tega je waifu-difuzija, ki je uspešno naknadno usposobljenih 56,000 anime slik v dokončano in usposobljeno kontrolno točko Stable Diffusion. Za ljubitelje pa je to težka možnost, saj model zahteva osupljivih najmanj 30 GB VRAM-a, kar je daleč več od tega, kar bo verjetno na voljo na ravni potrošnikov v prihajajočih izdajah NVIDIA serije 40XX.

Usposabljanje vsebine po meri v stabilno razširjanje prek waifu-difuzije: model je potreboval dva tedna naknadnega usposabljanja, da je ustvaril to raven ilustracije. Šest slik na levi prikazuje napredek modela, ko je usposabljanje potekalo, pri izdelavi predmetno koherentnega rezultata na podlagi novih podatkov o usposabljanju. Vir: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Za takšne "razcepe" kontrolnih točk stabilne difuzije bi lahko vložili veliko truda, vendar bi jih oviral tehnični dolg. Razvijalci na uradnem Discordu so že nakazali, da poznejše izdaje kontrolnih točk ne bodo nujno združljive s prejšnjimi različicami, tudi s hitro logiko, ki je morda delovala s prejšnjo različico, saj je njihov primarni interes pridobiti najboljši možni model, ne pa podpirati starejših aplikacij in procesov.
Zato podjetje ali posameznik, ki se odloči razvejati kontrolno točko v komercialni izdelek, dejansko nima poti nazaj; njihova različica modela je na tej točki 'hard fork' in ne bo mogla izkoristiti prednosti poznejših izdaj iz stability.ai – kar je precejšnja obveza.
Trenutno in večje upanje za prilagajanje stabilne difuzije je Besedilna inverzija, kjer uporabnik trenira v majhni peščici CLIP- poravnane slike.

Sodelovanje med Univerzo Tel Aviv in NVIDIA, besedilna inverzija omogoča usposabljanje diskretnih in novih entitet, ne da bi uničili zmogljivosti izvornega modela. Vir: https://textual-inversion.github.io/
Glavna navidezna omejitev inverzije besedila je, da se priporoča zelo majhno število slik – le pet. To dejansko ustvari omejeno entiteto, ki je lahko bolj uporabna za naloge prenosa sloga kot za vstavljanje fotorealističnih predmetov.
Kljub temu trenutno potekajo poskusi znotraj različnih stabilnih difuzijskih neskladij, ki uporabljajo veliko večje število vadbenih slik, in treba je še videti, kako produktivna se bo metoda izkazala. Spet tehnika zahteva veliko VRAM-a, časa in potrpljenja.
Zaradi teh omejujočih dejavnikov bomo morda morali nekaj časa počakati, da bomo videli nekaj bolj izpopolnjenih poskusov besedilne inverzije od navdušencev Stable Diffusion – in ali vas ta pristop lahko "postavi v sliko" na način, ki izgleda bolje kot Photoshop izreži in prilepi, hkrati pa ohrani osupljivo funkcionalnost uradnih kontrolnih točk.
Prvič objavljeno 6. septembra 2022.















