Искусственный интеллект
Суперзарядка больших языковых моделей с помощью многотокенной предсказания
By
Aayush Mittal Mittal
Большие языковые модели (LLM) như GPT, LLaMA и другие потрясли мир своей замечательной способностью понимать и генерировать текст, похожий на человеческий. Однако, несмотря на их впечатляющие возможности, стандартный метод обучения этих моделей, известный как “предсказание следующего токена”, имеет некоторые врожденные ограничения.
При предсказании следующего токена модель обучается предсказывать следующее слово в последовательности, учитывая предыдущие слова. Хотя этот подход оказался успешным, он может привести к моделям, которые испытывают трудности с длинными зависимостями и сложными задачами рассуждения. Кроме того, несоответствие между режимом обучения с учителем и автoreгрессивным процессом генерации во время вывода может привести к субоптимальной производительности.
Недавняя статья исследователей Gloeckle et al. (2024) из Meta AI представляет новый парадигм обучения под названием “многотокенная предсказания“, который направлен на решение этих ограничений и суперзарядку больших языковых моделей. В этом блог-посте мы глубоко погрузимся в основные концепции, технические детали и потенциальные последствия этого новаторского исследования.
Предсказание одного токена: традиционный подход
Прежде чем углубиться в детали многотокенной предсказания, важно понять традиционный подход, который был основой обучения больших языковых моделей в течение многих лет – предсказание одного токена, также известное как предсказание следующего токена.
Парадигма предсказания следующего токена
В парадигме предсказания следующего токена языковые модели обучаются предсказывать следующее слово в последовательности, учитывая предыдущий контекст. Более формально, модель задается максимизацией вероятности следующего токена xt+1, учитывая предыдущие токены x1, x2, …, xt. Это обычно делается путем минимизации функции потерь перекрестной энтропии:
L = -Σt log P(xt+1 | x1, x2, …, xt)
Эта простая, но мощная цель обучения была основой многих успешных больших языковых моделей, таких как GPT (Radford et al., 2018), BERT (Devlin et al., 2019) и их варианты.
Обучение с учителем и автoreгрессивная генерация
Предсказание следующего токена полагается на метод обучения, называемый “обучением с учителем“, когда модели предоставляется правильный результат для каждого будущего токена во время обучения. Это позволяет модели учиться на правильном контексте и целевых последовательностях, что облегчает более стабильное и эффективное обучение.
Однако во время вывода или генерации модель работает в автoreгрессивном режиме, предсказывая один токен за раз на основе предыдущих сгенерированных токенов. Это несоответствие между режимом обучения (обучением с учителем) и режимом вывода (авторегрессивной генерацией) может привести к потенциальным несоответствиям и субоптимальной производительности, особенно для более длинных последовательностей или сложных задач рассуждения.
Ограничения предсказания следующего токена
Хотя предсказание следующего токена было довольно успешным, оно также имеет некоторые врожденные ограничения:
- Краткосрочная направленность: Предсказывая только следующий токен, модель может испытывать трудности с захватом длинных зависимостей и общей структуры и связности текста, что потенциально может привести к несоответствиям или не связанным генерациям.
- Локальная фиксация на закономерностях: Модели предсказания следующего токена могут фиксироваться на локальных закономерностях в обучающих данных, что затрудняет обобщение на сценарии вне распределения или задачи, требующие более абстрактного рассуждения.
- Возможности рассуждения: Для задач, которые включают многоступенчатое рассуждение, алгоритмическое мышление или сложные логические операции, предсказание следующего токена может не обеспечить достаточные индуктивные предубеждения или представления для эффективной поддержки таких возможностей.
- Неэффективность выборки: Из-за локальной природы предсказания следующего токена модели могут требовать более крупных обучающих наборов данных для приобретения необходимых знаний и навыков рассуждения, что потенциально может привести к неэффективности выборки.
Эти ограничения мотивировали исследователей изучать альтернативные парадигмы обучения, такие как многотокенная предсказания, которая направлена на решение некоторых из этих недостатков и разблокировку новых возможностей для больших языковых моделей.
Сопоставляя традиционный подход предсказания одного токена с новым методом многотокенной предсказания, читатели могут лучше понять мотивацию и потенциальные преимущества последнего, что создает основу для более глубокого изучения этого новаторского исследования.
Что такое многотокенная предсказания?
Ключевая идея за многотокенной предсказания заключается в обучении языковых моделей предсказывать несколько будущих токенов одновременно, а не только следующий токен. Конкретно, во время обучения модель задается предсказанием следующих n токенов в каждой позиции обучающего корпуса, используя n независимых выходных слоев, работающих поверх общего ствола модели.

Например, с настройкой предсказания 4 токенов модель будет обучаться предсказывать следующие 4 токена одновременно, учитывая предыдущий контекст. Этот подход поощряет модель захватывать более длинные зависимости и развивать лучшее понимание общей структуры и связности текста.
Пример для игрушки
Чтобы лучше понять концепцию многотокенной предсказания, рассмотрим простой пример. Предположим, у нас есть следующее предложение:
“Быстрая коричневая лиса прыгает над ленивой собакой.”
В стандартном подходе предсказания следующего токена модель будет обучаться предсказывать следующее слово, учитывая предыдущий контекст. Например, учитывая контекст “Быстрая коричневая лиса прыгает над”, модель будет задана предсказанием следующего слова, “ленивой”.
С многотокенной предсказания, однако, модель будет обучаться предсказывать несколько будущих токенов одновременно. Например, если мы установим n=4, модель будет обучаться предсказывать следующие 4 слова одновременно. Учитывая тот же контекст “Быстрая коричневая лиса прыгает над”, модель будет задана предсказанием последовательности “ленивой собакой”. (Обратите внимание на пробел после “собакой”, чтобы указать конец предложения).
Обучая модель предсказывать несколько будущих токенов одновременно, она поощряется захватывать длинные зависимости и развивать лучшее понимание общей структуры и связности текста.
Технические детали
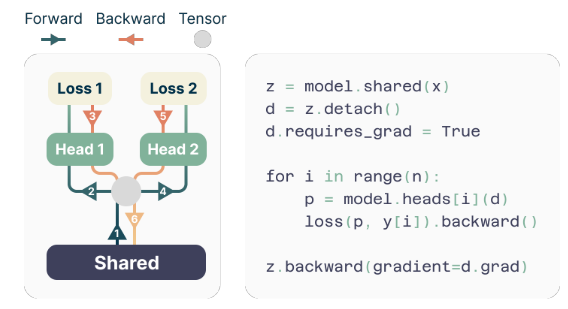
Авторы предлагают простую, но эффективную архитектуру для реализации многотокенной предсказания. Модель состоит из общего ствола трансформера, который производит潜ный представление входного контекста, за которым следуют n независимых слоев трансформера (выходных голов), которые предсказывают соответствующие будущие токены.
Во время обучения прямой и обратный проходы тщательно оркестрируются, чтобы минимизировать использование памяти GPU. Общий ствол вычисляет潜ный представление, а затем каждая выходная голова последовательно выполняет свой прямой и обратный проход, накапливая градиенты на уровне ствола. Этот подход избегает материализации всех векторов логитов и их градиентов одновременно, уменьшая пиковое использование памяти GPU с O(nV + d) до O(V + d), где V является размером словаря, а d является размерностью潜ного представления.
Эффективная реализация
Одной из проблем при обучении многотокенных предсказателей является снижение использования памяти GPU. Поскольку размер словаря (V) обычно намного больше, чем размерность潜ного представления (d), векторы логитов становятся узким местом использования памяти GPU.
Чтобы решить эту проблему, авторы предлагают эффективную реализацию, которая тщательно адаптирует последовательность прямых и обратных операций. Вместо материализации всех логитов и их градиентов одновременно, реализация последовательно вычисляет прямой и обратный проход для каждой независимой выходной головы, накапливая градиенты на уровне ствола.
Этот подход избегает хранения всех векторов логитов и их градиентов в памяти одновременно, уменьшая пиковое использование памяти GPU с O(nV + d) до O(V + d), где n является количеством будущих токенов, которые предсказываются.
Преимущества многотокенной предсказания
Статья представляет несколько убедительных преимуществ использования многотокенной предсказания для обучения больших языковых моделей:
- Улучшенная эффективность выборки: Поощряя модель предсказывать несколько будущих токенов одновременно, многотокенная предсказания стимулирует модель к лучшей эффективности выборки. Авторы демонстрируют значительные улучшения производительности на задачах понимания и генерации кода, с моделями до 13B параметров, решающими около 15% больше проблем в среднем.
- Быстрый вывод: Дополнительные выходные головы, обученные с помощью многотокенной предсказания, могут быть использованы для само-спекулятивного декодирования, варианта спекулятивного декодирования, который позволяет параллельно предсказывать токены. Это приводит к более быстрым временам вывода до 3 раз, даже для крупных моделей.
- Поощрение длинных зависимостей: Многотокенная предсказания поощряет модель захватывать более длинные зависимости и закономерности в данных, что особенно полезно для задач, которые требуют понимания и рассуждения над более крупными контекстами.
- Алгоритмическое рассуждение: Авторы представляют эксперименты на синтетических задачах, которые демонстрируют превосходство моделей многотокенной предсказания в развитии индуктивных голов и алгоритмических возможностей рассуждения, особенно для более мелких размеров моделей.
- Связность и последовательность: Обучая модель предсказывать несколько будущих токенов одновременно, многотокенная предсказания поощряет развитие связных и последовательных представлений. Это особенно полезно для задач, которые требуют генерации более длинного, связного текста, такого как рассказывание историй, творческое письмо или генерация инструктивных руководств.
- Улучшенная обобщаемость: Эксперименты авторов на синтетических задачах предполагают, что модели многотокенной предсказания демонстрируют лучшие возможности обобщения, особенно в сценариях вне распределения. Это потенциально связано с способностью модели захватывать более длинные закономерности и зависимости, что помогает ей экстраполировать более эффективно в незнакомые сценарии.
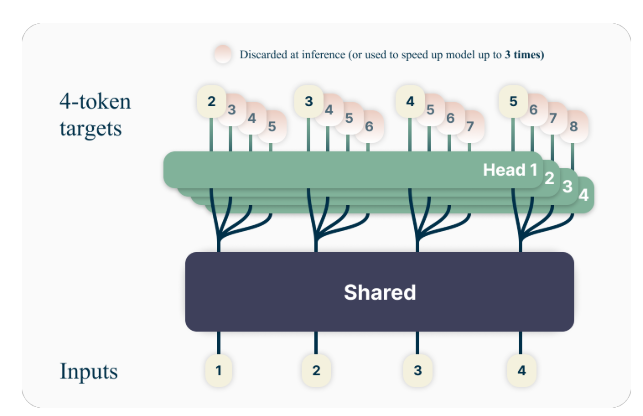
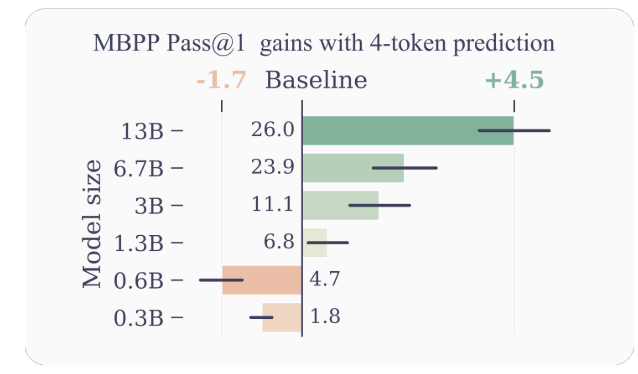
Примеры и интуиции
Чтобы предоставить больше интуиций о том, почему многотокенная предсказания работает так хорошо, рассмотрим несколько примеров:
- Генерация кода: В контексте генерации кода предсказание нескольких токенов одновременно может помочь модели понять и сгенерировать более сложные кодовые структуры. Например, при генерации определения функции предсказание только следующего токена может не обеспечить достаточный контекст для модели, чтобы сгенерировать всю сигнатуру функции правильно. Однако, предсказывая несколько токенов одновременно, модель может лучше захватить зависимости между именем функции, параметрами и типом возвращаемого значения, что приводит к более точной и связной генерации кода.
- Рассуждение в естественном языке: Рассмотрим сценарий, в котором языковая модель задана ответом на вопрос, который требует рассуждения над несколькими шагами или кусками информации. Предсказывая несколько токенов одновременно, модель может лучше захватить зависимости между различными компонентами процесса рассуждения, что приводит к более связным и точным ответам.
- Генерация длинного текста: При генерации длинного текста, такого как истории, статьи или отчеты, поддержание связности и последовательности в течение длительного периода может быть сложной задачей для языковых моделей, обученных с помощью предсказания следующего токена. Многотокенная предсказания поощряет модель развивать представления, которые захватывают общую структуру и поток текста, что потенциально может привести к более связным и последовательным длинным генерациям.
Ограничения и будущие направления
Хотя результаты, представленные в статье, впечатляют, есть несколько ограничений и открытых вопросов, которые требуют дальнейшего изучения:
- Оптимальное количество токенов: Статья исследует различные значения n (количество будущих токенов для предсказания) и находит, что n=4 работает хорошо для многих задач. Однако оптимальное значение n может зависеть от конкретной задачи, набора данных и размера модели. Разработка принципиальных методов для определения оптимального n может привести к дальнейшим улучшениям производительности.
- Размер словаря и токенизация: Авторы отмечают, что оптимальный размер словаря и стратегия токенизации для моделей многотокенной предсказания могут отличаться от тех, которые используются для моделей предсказания следующего токена. Изучение этого аспекта может привести к лучшим компромиссам между сжатой длиной последовательности и вычислительной эффективностью.
- Вспомогательные потери предсказания: Авторы предполагают, что их работа может вызвать интерес к разработке новых вспомогательных потерь предсказания для больших языковых моделей, за пределами стандартного предсказания следующего токена. Изучение альтернативных вспомогательных потерь и их комбинаций с многотокенной предсказания является интересным направлением исследований.
- Теоретическое понимание: Хотя статья предоставляет некоторые интуиции и эмпирические доказательства эффективности многотокенной предсказания, более глубокое теоретическое понимание того, почему и как этот подход работает так хорошо, было бы ценным.
Заключение
Исследовательская статья “Лучшие и быстрые большие языковые модели посредством многотокенной предсказания” Gloeckle et al. (2024) представляет новый парадигм обучения, который имеет потенциал значительно улучшить производительность и возможности больших языковых моделей. Обучая модели предсказывать несколько будущих токенов одновременно, многотокенная предсказания поощряет развитие длинных зависимостей, алгоритмических возможностей рассуждения и лучшей эффективности выборки.
Техническая реализация, предложенная авторами, элегантна и вычислительна эффективна, что делает ее возможной для применения этого подхода к крупномасштабному обучению языковых моделей. Кроме того, возможность использования само-спекулятивного декодирования для более быстрого вывода является значительным практическим преимуществом.
Хотя есть еще открытые вопросы и области для дальнейшего изучения, это исследование представляет собой интересный шаг вперед в области больших языковых моделей. По мере того, как спрос на более мощные и эффективные языковые модели продолжает расти, многотокенная предсказания может стать ключевым компонентом в следующем поколении этих мощных систем ИИ.
Я провел последние пять лет, погружаясь в fasciniruyushiy мир Machine Learning и Deep Learning. Моя страсть и экспертиза привели меня к участию в более чем 50 различных проектах по разработке программного обеспечения, с особым акцентом на AI/ML. Мое непрекращающееся любопытство также привело меня к Natural Language Processing, области, которую я с нетерпением жду, чтобы изучить дальше.

You may like
-


Удаление объектов и людей из видео с помощью ИИ
-


Кодирование настроений страдает, когда роль ИИ расширяется
-


Стена GPU Трещит: Невидимая Революция в Пост-Трансформерских Архитектурах
-


Google NotebookLM представляет функцию глубокого исследования
-


Глава отдела ИИ Meta Ян Лекун планирует выход из стартапа
-


Как Проникнуть с Абсурдными Научными Статьями Мимо AI-Рецензентов











