
Artificial Intelligence
Google LipSync3D предлагает улучшенную синхронизацию движений рта «Deepfaked»

A сотрудничество между исследователями Google AI и Индийским технологическим институтом Харагпур предлагает новую платформу для синтеза говорящих голов из аудиоконтента. Проект направлен на создание оптимизированных и разумно обеспеченных способов создания видеоконтента «говорящей головы» из аудио для целей синхронизации движений губ с дублированным или машинным переводом аудио, а также для использования в аватарах, интерактивных приложениях и других приложениях. среды реального времени.

Источник: https://www.youtube.com/watch?v=L1StbX9OznY
Модели машинного обучения, обученные в этом процессе, называемые LipSync3D, требуют только одно видео с изображением целевого лица в качестве входных данных. Конвейер подготовки данных отделяет извлечение геометрии лица от оценки освещения и других аспектов входного видео, что обеспечивает более экономичное и целенаправленное обучение.
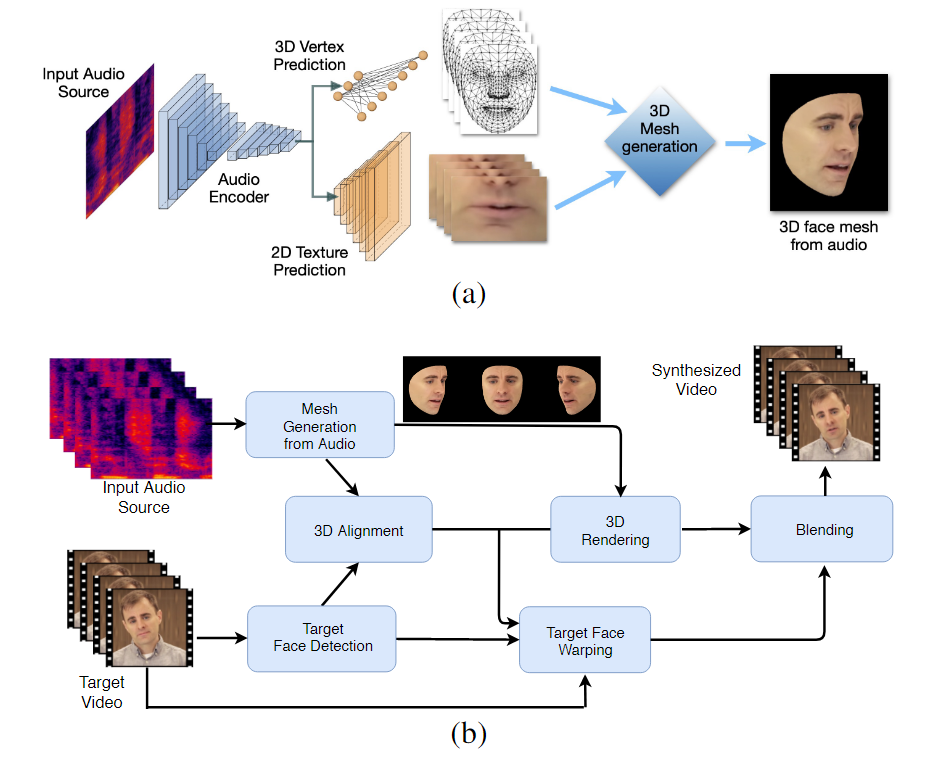
Двухэтапный рабочий процесс LipSync3D. Выше: создание динамически текстурированного 3D-лица из «целевого» звука; ниже вставка сгенерированной сетки в целевое видео.
На самом деле, наиболее заметным вкладом LipSync3D в исследования в этой области может быть его алгоритм нормализации освещения, который разделяет обучение и освещение для вывода.

Отделение данных освещения от общей геометрии помогает LipSync3D создавать более реалистичные выходные данные о движении губ в сложных условиях. Другие подходы последних лет ограничивались «фиксированными» условиями освещения, что не раскрывает их более ограниченные возможности в этом отношении.
Во время предварительной обработки кадров входных данных система должна определить и удалить зеркальные точки, поскольку они характерны для условий освещения, при которых было снято видео, и в противном случае будут мешать процессу повторного освещения.

LipSync3D, как следует из названия, не выполняет простой пиксельный анализ лиц, которые он оценивает, а активно использует идентифицированные лицевые ориентиры для создания подвижных сеток в стиле компьютерной графики вместе с «развернутыми» текстурами, которые обертываются вокруг них в традиционной компьютерной графике. трубопровод.

Нормализация позы в LipSync3D. Слева — входные кадры и обнаруженные признаки; в середине нормализованные вершины сгенерированной оценки сетки; а справа соответствующий текстурный атлас, который обеспечивает основу для предсказания текстуры. Источник: https://arxiv.org/pdf/2106.04185.pdf
Помимо нового метода повторного освещения, исследователи утверждают, что LipSync3D предлагает три основных нововведения по сравнению с предыдущей работой: разделение геометрии, освещения, позы и текстуры на дискретные потоки данных в нормализованном пространстве; легко обучаемая авторегрессионная модель прогнозирования текстуры, которая производит согласованный во времени синтез видео; и повышенный реализм, оцениваемый человеческими рейтингами и объективными показателями.

Разделение различных аспектов видеоизображения лица позволяет лучше контролировать синтез видео.
LipSync3D может получить соответствующее геометрическое движение губ непосредственно из звука, анализируя фонемы и другие аспекты речи и переводя их в известные соответствующие позы мышц вокруг области рта.

В этом процессе используется конвейер совместного прогнозирования, в котором предполагаемая геометрия и текстура имеют выделенные кодировщики в настройке автокодировщика, но совместно используют аудиокодировщик с речью, которая предназначена для наложения на модель:

Синтез лабильного движения LipSync3D также предназначен для стилизованных аватаров CGI, которые, по сути, представляют собой только тот же тип информации о сетке и текстуре, что и изображения реального мира:
Губы стилизованного 3D-аватара двигаются в режиме реального времени с помощью исходного видео спикера. В таком сценарии наилучшие результаты будут получены при индивидуальной предварительной подготовке.
Исследователи также ожидают использования аватаров с немного более реалистичным ощущением:
![]()
Примерное время обучения для видео варьируется от 3-5 часов для 2-5-минутного видео в конвейере, использующем TensorFlow, Python и C++ на GeForce GTX 1080. В учебных сеансах использовался размер пакета из 128 кадров более 500-1000. эпохи, причем каждая эпоха представляет собой полную оценку видео.

На пути к динамической ресинхронизации движения губ
Область повторной синхронизации губ для размещения новой звуковой дорожки в последние несколько лет привлекла большое внимание в исследованиях компьютерного зрения (см. ниже), не в последнюю очередь потому, что это является побочным продуктом спорных DeepFake технология.
В 2017 году Вашингтонский университет представленное исследование способен изучать синхронизацию губ по аудио, используя его, чтобы изменить движения губ тогдашнего президента Обамы. В 2018 году; Институт Макса Планка по информатике возглавил еще одна исследовательская инициатива чтобы включить передачу удостоверения личности>идентификация видео с синхронизацией губ побочный продукт процесса; а в мае 2021 года стартап искусственного интеллекта FlawlessAI представил свою запатентованную технологию синхронизации губ TrueSync, широко получила в прессе как средство улучшения технологий дублирования для крупных выпусков фильмов на разных языках.
И, конечно же, постоянное развитие репозиториев дипфейков с открытым исходным кодом обеспечивает еще одну ветвь активных исследований с участием пользователей в этой области синтеза изображений лица.















