Искусственный интеллект
Полное руководство по Gemma 2: новая открытая модель большого языка Google

Джемма 2 Разработанный на основе своего предшественника, он предлагает повышенную производительность и эффективность, а также ряд инновационных функций, которые делают его особенно привлекательным как для исследований, так и для практического применения. Gemma 2 отличается от других своей способностью обеспечивать производительность, сопоставимую с гораздо более крупными фирменными моделями, но в корпусе, разработанном для более широкой доступности и использования на более скромном оборудовании.
Углубляясь в технические характеристики и архитектуру Gemma 2, я все больше удивлялся изобретательности ее конструкции. Модель включает в себя несколько передовых методов, в том числе новые механизмы внимания и инновационные подходы к тренировке стабильности, которые способствуют ее замечательным возможностям.

LLM Google с открытым исходным кодом Джемма
В этом подробном руководстве мы подробно рассмотрим Gemma 2, её архитектуру, ключевые функции и практические применения. Независимо от того, являетесь ли вы опытным специалистом в области искусственного интеллекта или новичком-энтузиастом, эта статья предоставит вам ценную информацию о том, как работает Gemma 2 и как вы можете использовать её возможности в своих проектах.
Что такое Джемма 2?
Gemma 2 — новейшая модель Google с открытым исходным кодом для больших языков, разработанная с учётом лёгкости и производительности. Она основана на тех же исследованиях и технологиях, которые использовались при создании моделей Google Gemini, предлагая высочайшую производительность в более доступной упаковке. Gemma 2 доступна в двух вариантах:
Джемма 2 9Б: Модель с 9 миллиардами параметров.
Джемма 2 27Б: Более крупная модель с 27 миллиардами параметров.
Каждый размер доступен в двух вариантах:
Базовые модели: предварительно обучено на обширном массиве текстовых данных.
Модели с настройкой инструкций (IT): Тонкая настройка для повышения производительности при выполнении конкретных задач.
Доступ к моделям в Google AI Studio: Google AI Studio – Джемма 2
Прочтите статью здесь: Технический отчет Джеммы 2
Ключевые особенности и улучшения
Gemma 2 представляет несколько существенных улучшений по сравнению со своей предшественницей:
1. Увеличение объемов обучающих данных
Модели были обучены на значительно большем количестве данных:
Джемма 2 27Б: Обучено на 13 триллионах токенов.
Джемма 2 9Б: Обучено на 8 триллионах токенов.
Этот расширенный набор данных, состоящий в основном из веб-данных (в основном на английском языке), кода и математики, способствует повышению производительности и универсальности моделей.
2. Скользящее окно Внимание!
Gemma 2 реализует новый подход к механизмам внимания:
Каждый второй уровень использует скользящее окно внимания с локальным контекстом из 4096 токенов.
Чередование слоев использует полное квадратичное глобальное внимание во всем контексте токена 8192.
Этот гибридный подход направлен на то, чтобы сбалансировать эффективность с возможностью захвата долгосрочных зависимостей во входных данных.
3. Мягкое ограничение
Чтобы улучшить стабильность и производительность тренировок, Gemma 2 представляет механизм мягкого ограничения:
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Applied to attention logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Applied to final layer logits
final_logits = soft_cap(final_logits, cap=30.0)
Этот метод предотвращает чрезмерное увеличение логитов без жесткого усечения, сохраняя больше информации и одновременно стабилизируя процесс обучения.
- Джемма 2 9Б: Модель с 9 миллиардами параметров.
- Джемма 2 27Б: Более крупная модель с 27 миллиардами параметров.
Каждый размер доступен в двух вариантах:
- Базовые модели: предварительно обучены на обширном массиве текстовых данных.
- Модели с настройкой инструкций (ИТ): точно настроены для повышения производительности при выполнении конкретных задач.
4. Дистилляция знаний
Для модели 9B Gemma 2 использует методы дистилляции знаний:
- Предварительное обучение: модель 9B учится у более крупной модели учителя во время первоначального обучения.
- Пост-обучение: модели 9B и 27B используют дистилляцию в соответствии с политикой для повышения производительности.
Этот процесс помогает меньшей модели более эффективно использовать возможности более крупных моделей.
5. Объединение моделей
Gemma 2 использует новую технику объединения моделей под названием Warp, которая объединяет несколько моделей в три этапа:
- Экспоненциальное скользящее среднее (EMA) во время тонкой настройки обучения с подкреплением
- Сферическая линейная интерполяция (SLERP) после тонкой настройки нескольких политик
- Линейная интерполяция на пути к инициализации (LITI) как последний шаг
Этот подход направлен на создание более надежной и работоспособной окончательной модели.
Тесты производительности
Gemma 2 демонстрирует впечатляющую производительность в различных тестах:
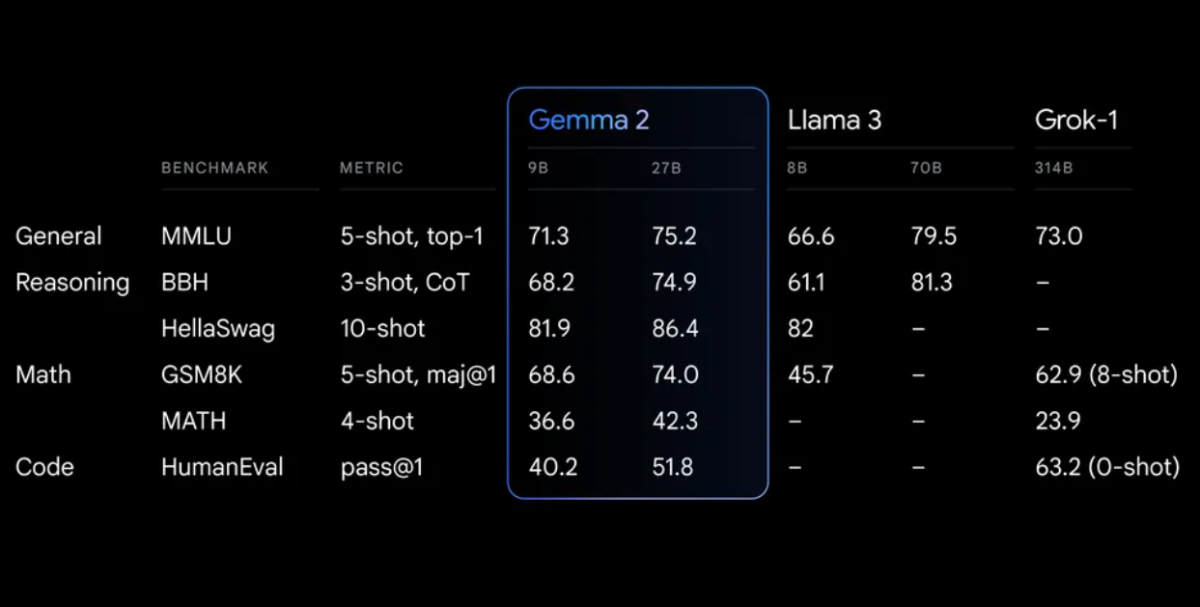
Gemma 2 с переработанной архитектурой, разработанной для обеспечения исключительной производительности и эффективности вывода.
Начало работы с Джеммой 2
Чтобы начать использовать Gemma 2 в своих проектах, у вас есть несколько вариантов:
1. Google AI-студия
Для быстрого экспериментирования без требований к оборудованию вы можете получить доступ к Gemma 2 через Google AI-студия.
2. Трансформеры с объятиями
Gemma 2 интегрирована с популярной Обнимая лицо Библиотека «Трансформеры». Вот как её использовать:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the model and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Prepare input prompt = "Explain the concept of quantum entanglement in simple terms." inputs = tokenizer(prompt, return_tensors="pt") # Generate text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. ТензорФлоу/Керас
Для пользователей TensorFlow Gemma 2 доступна через Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Load the model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate text
prompt = "Explain the concept of quantum entanglement in simple terms."
output = model.generate(prompt, max_length=200)
print(output)
Расширенное использование: создание локальной системы RAG с помощью Gemma 2
Одно из эффективных применений Gemma 2 — создание системы расширенной генерации данных (RAG). Давайте создадим простую, полностью локальную систему RAG, используя Gemma 2 и вложения Nomic.
Шаг 1: Настройка среды
Сначала убедитесь, что у вас установлены необходимые библиотеки:
pip install langchain ollama nomic chromadb
Шаг 2. Индексирование документов
Создайте индексатор для обработки ваших документов:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Usage
indexer = Indexer("path/to/your/documents")
vector_store = indexer.index()
Шаг 3. Настройка системы RAG
Теперь давайте создадим систему RAG с помощью Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Usage
rag_system = RAGSystem(vector_store)
response = rag_system.query("What is the capital of France?")
print(response["result"])
Эта система RAG использует Gemma 2–Ollama для языковой модели и вложения Nomic для поиска документов. Это позволяет вам задавать вопросы на основе проиндексированных документов, предоставляя ответы с контекстом из соответствующих источников.
Точная настройка Джеммы 2
Для определенных задач или областей вам может потребоваться тонкая настройка Gemma 2. Вот простой пример использования библиотеки Hugging Face Transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load model and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prepare dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
Не забудьте настроить параметры обучения в соответствии с вашими конкретными требованиями и вычислительными ресурсами.
Этические соображения и ограничения
Хотя Gemma 2 предлагает впечатляющие возможности, важно помнить о ее ограничениях и этических соображениях:
- Смещение: Как и все языковые модели, Gemma 2 может отражать предвзятости, присутствующие в ее обучающих данных. Всегда критически оценивайте его результаты.
- Фактическая точность: Несмотря на свои высокие возможности, «Джемма 2» иногда может генерировать неверную или противоречивую информацию. Проверьте важные факты из надежных источников.
- Длина контекста: Gemma 2 имеет длину контекста 8192 токена. Для более длинных документов или разговоров вам может потребоваться реализовать стратегии для эффективного управления контекстом.
- Вычислительные ресурсы: Для эффективного вывода и точной настройки могут потребоваться значительные вычислительные ресурсы, особенно для модели 27B.
- Ответственное использование: Соблюдайте принципы ответственного использования искусственного интеллекта Google и убедитесь, что использование Gemma 2 соответствует этическим принципам искусственного интеллекта.
Заключение
Расширенные функции Gemma 2, такие как скользящее окно внимания, мягкое ограничение и новые методы слияния моделей, делают его мощным инструментом для широкого спектра задач обработки естественного языка.
Используя Gemma 2 в своих проектах, будь то с помощью простого вывода, сложных систем RAG или точно настроенных моделей для конкретных областей, вы можете задействовать мощь SOTA AI, сохраняя при этом контроль над своими данными и процессами.












