Промпт-инжиниринг
ChatGPT & Advanced Prompt Engineering: Driving the AI Evolution

OpenAI была инструментальной в разработке революционных инструментов, таких как OpenAI Gym, предназначенный для обучения алгоритмов укрепления, и моделей GPT-n. В центре внимания также находится DALL-E, модель ИИ, создающая изображения из текстовых входных данных. Одна из таких моделей, которая привлекла значительное внимание, – это ChatGPT от OpenAI, блестящий пример в области больших языковых моделей.
GPT-4: Prompt Engineering
ChatGPT преобразовал ландшафт чат-ботов, предлагая человеческие ответы на входные данные пользователей и расширяя свои применения в различных областях – от разработки и тестирования программного обеспечения до деловой коммуникации, и даже создания поэзии.
В руках бизнеса и отдельных лиц GPT-4, например, может служить неисчерпаемым резервуаром знаний,熟悉ым с предметами, варьирующимися от математики и биологии до юридических исследований. Такие сложные и доступные модели ИИ готовы переопределить будущее работы, обучения и творчества.

Генеративные модели, такие как GPT-4, могут производить новые данные на основе существующих входных данных. Это отличительная особенность позволяет им выполнять различные задачи, включая генерацию текста, изображений, музыки и видео.
В контексте ChatGPT и моделей OpenAI подсказка – это вход, который пользователи предоставляют моделям, обычно в виде текста. Подсказки служат основным средством контроля выходных данных, генерируемых этими моделями, что делает их важными для успешных и актуальных разговоров.
Влияние качества подсказки
Использование хорошо определенных подсказок является ключом к ведению полезных и осмысленных разговоров с системами ИИ. Плохо определенные подсказки могут привести к выходным данным, которые не полезны для пользователя и могут даже привести к вводящей в заблуждение информации.
Чтобы продемонстрировать влияние качества подсказки, давайте сравним две разные подсказки, данные ChatGPT. Первая подсказка, плохо определенная и предполагающая предварительные знания, генерирует потенциально не полезный ответ для пользователя. С другой стороны, вторая подсказка предоставляет больше контекста и примеров, гарантируя более актуальный и понятный ответ.
Подсказка 1: “Расскажите мне о свёрточных нейронных сетях.”
Ответ 1: “Свёрточные нейронные сети (CNN) – это многослойные перцептроны, состоящие из полностью связанных слоев и пулинговых слоев. Они обычно используются в задачах распознавания изображений. Процесс включает применение фильтров к входным изображениям и уменьшение их с помощью пулинговых слоев.”
Подсказка 2: “Я хочу узнать о свёрточных нейронных сетях, но у меня нет предварительных знаний об искусственных нейронных сетях. Можете ли вы предоставить начинающим объяснение и пример того, как CNN используются в распознавании изображений?”
Ответ 2: “Свёрточные нейронные сети (CNN) – это тип нейронной сети, в основном используемой для задач распознавания изображений. В отличие от других нейронных сетей, они используют свёрточные слои и пулинговые слои для обработки изображений. Представьте, что у вас есть изображение кошки. CNN могут определить различные особенности в изображении, такие как усы, уши и хвост, применяя фильтры и уменьшая изображение с помощью пулинговых слоев. Этот процесс делает CNN высокоэффективными для распознавания объектов в изображениях.”
При сравнении двух ответов становится очевидным, что хорошо определенная подсказка приводит к более актуальному и пользовательскому ответу. Проектирование и инженерия подсказок – это растущие дисциплины, целью которых является оптимизация качества выходных данных моделей ИИ, таких как ChatGPT.
В следующих разделах этой статьи мы углубимся в область продвинутых методов, направленных на совершенствование больших языковых моделей (LLM), таких как техники и тактики инженерии подсказок. Это включает в себя few-shot learning, ReAct, chain-of-thought, RAG и многое другое.
Продвинутые инженерные техники
Прежде чем мы продолжим, важно понять ключевую проблему с LLM, известную как “галлюцинация”. В контексте LLM “галлюцинация” означает тенденцию этих моделей генерировать выходные данные, которые могут показаться разумными, но не основаны на фактической реальности или данном контексте.
Эта проблема была ярко выделена в недавнем судебном деле, где защитник использовал ChatGPT для юридических исследований. Инструмент ИИ, споткнувшись из-за своей проблемы галлюцинации, сослался на несуществующие юридические дела. Этот промах имел значительные последствия, вызвав путаницу и подорвав достоверность во время слушаний. Этот инцидент служит ярким напоминанием о срочной необходимости решить проблему “галлюцинации” в системах ИИ.
Наше исследование техник инженерии подсказок направлено на улучшение этих аспектов LLM. Улучшая их эффективность и безопасность, мы открываем путь для инновационных приложений, таких как извлечение информации. Кроме того, это открывает двери для бесшовной интеграции LLM с внешними инструментами и источниками данных, расширяя диапазон их потенциальных применений.
Zero и few-shot обучение: оптимизация с помощью примеров
Генеративные предварительно обученные трансформеры (GPT-3) ознаменовали важный поворотный момент в развитии генеративных моделей ИИ, поскольку они ввели понятие “few-shot обучения“. Этот метод был прорывом благодаря своей способности работать эффективно без необходимости полного дообучения. Фреймворк GPT-3 обсуждается в статье “Языковые модели – это few-shot обучающиеся“, где авторы демонстрируют, как модель excels в различных случаях использования без необходимости настраиваемых наборов данных или кода.
В отличие от дообучения, которое требует постоянных усилий для решения различных задач, модели few-shot демонстрируют более легкую адаптивность к более широкому диапазону применений. Хотя дообучение может обеспечить прочные решения в некоторых случаях, оно может быть дорогим в масштабе, что делает использование моделей few-shot более практичным подходом, особенно при интеграции с инженерией подсказок.
Представьте, что вы пытаетесь перевести английский язык на французский. В few-shot обучении вы предоставите GPT-3 несколько примеров перевода, таких как “sea otter -> loutre de mer”. GPT-3, будучи продвинутой моделью, затем может продолжать предоставлять точные переводы. В zero-shot обучении вы не предоставите никаких примеров, и GPT-3 все равно сможет перевести английский язык на французский эффективно.
Термин “few-shot обучение” возникает из идеи, что модель дана ограниченное количество примеров для “обучения”. важно отметить, что “обучение” в этом контексте не предполагает обновления параметров или весов модели, а скорее влияет на производительность модели.

Few Shot Learning, как показано в статье GPT-3
Zero-shot обучение берет этот концепт на шаг дальше. В zero-shot обучении не предоставляются примеры выполнения задачи в модели. Модель ожидается выполнить задачу хорошо на основе своего первоначального обучения, что делает этот метод идеальным для сценариев открытого вопроса и ответа, таких как ChatGPT.
Во многих случаях модель, профессиональная в zero-shot обучении, может работать хорошо, когда предоставляются few-shot или даже single-shot примеры. Эта способность переключаться между zero, single и few-shot обучением подчеркивает адаптивность крупных моделей, повышая их потенциальные применения в различных областях.
Методы zero-shot обучения становятся все более распространенными. Эти методы характеризуются своей способностью распознавать объекты, не виденные во время обучения. Вот практический пример few-shot подсказки:
"Переведите следующие английские фразы на французский:
'sea otter' переводится как 'loutre de mer'
'sky' переводится как 'ciel'
'Что переводится как 'cloud' на французском языке?'"
Предоставляя модели несколько примеров, а затем задав вопрос, мы можем эффективно направить модель на генерацию желаемого выхода. В этом случае GPT-3, скорее всего, правильно переведет “cloud” на французский как “nuage”.
Мы углубимся в различные нюансы инженерии подсказок и ее важную роль в оптимизации производительности модели во время вывода. Мы также рассмотрим, как ее можно эффективно использовать для создания экономически эффективных и масштабируемых решений в широком диапазоне случаев использования.
Когда мы дальше исследуем сложность техник инженерии подсказок в моделях GPT, важно подчеркнуть нашу последнюю статью ‘Основное руководство по инженерии подсказок в ChatGPT‘. Это руководство предоставляет информацию о стратегиях для эффективного инструктирования моделей ИИ в различных случаях использования.
В наших предыдущих обсуждениях мы углубились в фундаментальные методы подсказок для больших языковых моделей (LLM), таких как zero-shot и few-shot обучение, а также подсказки инструкций. Освоение этих техник имеет решающее значение для навигации по более сложным задачам инженерии подсказок, которые мы будем исследовать здесь.
Few-shot обучение может быть ограничено из-за ограниченного контекстного окна большинства LLM. Кроме того, без соответствующих мер безопасности LLM могут быть введены в заблуждение и предоставлять потенциально вредоносный выход. Кроме того, многие модели испытывают трудности с задачами рассуждения или выполнением многоступенчатых инструкций.
Учитывая эти ограничения, задача заключается в том, чтобы использовать LLM для решения сложных задач. Очевидным решением может быть разработка более продвинутых LLM или усовершенствование существующих, но это может потребовать значительных усилий. Итак, вопрос возникает: как мы можем оптимизировать текущие модели для улучшения решения проблем?
Не менее интересно исследование того, как эта техника взаимодействует с творческими приложениями в Unite AI’s ‘Освоение искусства ИИ: краткое руководство по Midjourney и инженерии подсказок‘, которое описывает, как слияние искусства и ИИ может привести к удивительным произведениям искусства.
Chain-of-thought подсказки
Chain-of-thought подсказки используют внутренние авто-регрессивные свойства крупных языковых моделей (LLM), которые отлично справляются с предсказанием следующего слова в данной последовательности. Подсказывая модель объяснить свой мыслительный процесс, она индуцирует более тщательное, методическое генерирование идей, которое склоняется к соответствию точной информации. Это соответствие возникает из-за модели склонности обрабатывать и предоставлять информацию вдумчивым и упорядоченным образом, подобно тому, как человеческий эксперт ведет слушателя через сложную концепцию. Простое заявление, такое как “пройдите меня через шаг за шагом, как…”, часто достаточно, чтобы спровоцировать этот более подробный и подробный выход.
Zero-shot Chain-of-thought подсказки
Хотя традиционная CoT подсказка требует предварительного обучения с демонстрациями, появляется новая область – zero-shot CoT подсказка. Этот подход, введенный Kojima et al. (2022), инновационно добавляет фразу “Давайте подумаем шаг за шагом” к исходной подсказке.
Давайте создадим продвинутую подсказку, где ChatGPT задача состоит в том, чтобы суммировать ключевые выводы из исследований ИИ и НЛП.
В этом демонстрационном примере мы будем использовать способность модели понимать и суммировать сложную информацию из академических текстов. Используя подход few-shot обучения, давайте научим ChatGPT суммировать ключевые выводы из исследований ИИ и НЛП:
1. Название статьи: "Внимание - это все, что вам нужно"
Ключевой вывод: Ввел модель трансформера, подчеркивая важность механизмов внимания над рекуррентными слоями для задач последовательной трансдукции.
2. Название статьи: "BERT: дообучение глубоких двунаправленных трансформеров для понимания языка"
Ключевой вывод: Ввел BERT, демонстрируя эффективность дообучения глубоких двунаправленных моделей, что привело к достижению лучших результатов в различных задачах НЛП.
Теперь, с контекстом этих примеров, суммируйте ключевые выводы из следующей статьи:
Название статьи: "Инженерия подсказок в крупных языковых моделях: исследование"
Эта подсказка не только сохраняет четкую цепочку мыслей, но также использует подход few-shot обучения для направления модели. Она связана с нашими ключевыми словами, фокусируясь на областях ИИ и НЛП, и конкретно задачей ChatGPT выполнить сложную операцию, связанную с инженерией подсказок: суммирование исследовательских статей.
ReAct подсказка
ReAct, или “Рассуждение и действие”, был введен Google в статье “ReAct: синергия рассуждения и действия в языковых моделях“, и революционизировал то, как языковые модели взаимодействуют с задачей, подсказывая модель динамически генерировать как вербальные рассуждения, так и задачи-специфические действия.
Представьте, что вы человек-шеф на кухне: он не только выполняет ряд действий (резка овощей, кипячение воды, перемешивание ингредиентов), но также занимается вербальным рассуждением или внутренней речью (“теперь, когда овощи нарезаны, я должен положить кастрюлю на плиту”). Этот постоянный мыслительный диалог помогает в стратегировании процесса, адаптации к внезапным изменениям (“у меня нет оливкового масла, я буду использовать масло вместо него”) и запоминании последовательности задач. ReAct имитирует эту человеческую способность, позволяя модели быстро учиться новым задачам и принимать прочные решения, как и человек в новых или неопределенных обстоятельствах.
ReAct может решить проблему галлюцинации, распространенную проблему систем CoT. CoT, хотя и эффективная техника, лишена способности взаимодействовать с внешним миром, что потенциально может привести к галлюцинации фактов и ошибкам. ReAct, однако, компенсирует это, взаимодействуя с внешними источниками информации. Это взаимодействие позволяет системе не только проверить свои рассуждения, но и обновить свои знания на основе последней информации из внешнего мира.
Фундаментальная работа ReAct может быть объяснена через пример из HotpotQA, задачи, требующей высокого порядка рассуждения. Получив вопрос, модель ReAct разбивает вопрос на управляемые части и создает план действий. Модель генерирует рассуждение (мысль) и определяет соответствующее действие. Она может решить посмотреть информацию об Apple Remote на внешнем источнике, таком как Википедия (действие), и обновляет свое понимание на основе полученной информации (наблюдение). Через несколько мыслей-действий-наблюдений ReAct может получить информацию для поддержки своих рассуждений, усовершенствуя, что ей нужно получить дальше.
Примечание:
HotpotQA – это набор данных, полученный из Википедии, состоящий из 113k пар вопрос-ответ, предназначенный для обучения систем ИИ сложному рассуждению, поскольку вопросы требуют рассуждения над несколькими документами для ответа. С другой стороны, CommonsenseQA 2.0, построенный через геймификацию, включает 14 343 вопроса “да/нет” и предназначен для проверки понимания ИИ общих знаний, поскольку вопросы намеренно созданы для того, чтобы ввести в заблуждение модели ИИ.
Процесс может выглядеть примерно так:
- Мысли: “Мне нужно поискать Apple Remote и его совместимые устройства.”
- Действие: Ищет “устройства, совместимые с Apple Remote”, на внешнем источнике.
- Наблюдение: Получает список устройств, совместимых с Apple Remote, из результатов поиска.
- Мысли: “На основе результатов поиска несколько устройств, кроме Apple Remote, могут управлять программой, с которой она была первоначально разработана для взаимодействия.”
Результатом является динамический, рассуждение-основанный процесс, который может развиваться на основе информации, с которой он взаимодействует, что приводит к более точным и надежным ответам.

Сравнительная визуализация четырех методов подсказки – Стандарт, Chain-of-Thought, Act-Only и ReAct, в решении HotpotQA и AlfWorld (https://arxiv.org/pdf/2210.03629.pdf)
Проектирование агентов ReAct – это специализированная задача, учитывая его способность достигать сложных целей. Например, разговорный агент, построенный на базовой модели ReAct, включает в себя разговорную память для обеспечения более богатых взаимодействий. Однако сложность этой задачи упрощается инструментами, такими как Langchain, которые стали стандартом для проектирования этих агентов.
Контекстно-верная подсказка
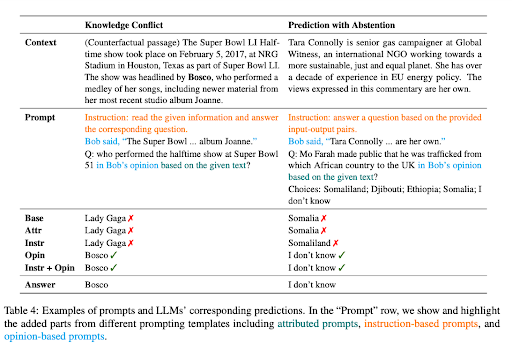
Статья ‘Контекстно-верная подсказка для крупных языковых моделей‘ подчеркивает, что хотя LLM показали значительный успех в задачах НЛП, основанных на знаниях, их чрезмерная зависимость от параметрических знаний может привести их astray в контекстно-чувствительных задачах. Например, когда языковая модель обучена на устаревших фактах, она может производить неправильные ответы, если она игнорирует контекстные подсказки.
Эта проблема очевидна в случаях конфликта знаний, где контекст содержит факты, отличающиеся от предварительных знаний LLM. Рассмотрим случай, когда крупная языковая модель (LLM), обученная на данных до чемпионата мира 2022 года, получает контекст, указывающий на то, что Франция выиграла турнир. Однако LLM, полагаясь на свои предварительные знания, продолжает утверждать, что предыдущий победитель, т.е. команда, выигравшая в 2018 году, все еще является действующим чемпионом. Это демонстрирует классический случай “конфликта знаний”.
По сути, конфликт знаний в LLM возникает, когда новая информация, предоставленная в контексте, противоречит предварительным знаниям, на которых была обучена модель. Склонность модели полагаться на свои предварительные знания, а не на новый контекст, может привести к неправильным выходным данным. С другой стороны, галлюцинация в LLM – это генерация ответов, которые могут показаться правдоподобными, но не основаны на обучающих данных модели или предоставленном контексте.
Другая проблема возникает, когда предоставленный контекст не содержит достаточно информации для точного ответа, ситуация, известная как предсказание с воздержанием. Например, если LLM спрашивают о основателе Microsoft на основе контекста, который не предоставляет эту информацию, он должен идеально воздержаться от угадывания.

Больше примеров конфликта знаний и силы воздержания
Чтобы улучшить контекстную верность LLM в этих сценариях, исследователи предложили ряд стратегий подсказки. Эти стратегии направлены на то, чтобы сделать ответы LLM более соответствующими контексту, а не полагаться на их закодированные знания.
Одной из таких стратегий является формулирование подсказок как вопросов мнений, где контекст интерпретируется как заявление рассказчика, а вопрос относится к этому рассказчику. Этот подход перенаправляет внимание LLM на представленный контекст, а не на ее предварительные знания.
Добавление контрфактических демонстраций к подсказкам также было выявлено как эффективный способ увеличить верность в случаях конфликта знаний. Эти демонстрации представляют сценарии с ложными фактами, которые направляют модель на то, чтобы обратить внимание на контекст для предоставления точных ответов.
Инструкционное дообучение
Инструкционное дообучение – это фаза обучения с учителем, которая использует предоставление модели конкретных инструкций, например, “Объясните различие между восходом и закатом солнца.” Инструкция сопоставляется с соответствующим ответом, например, “Восход солнца относится к моменту, когда солнце появляется над горизонтом утром, в то время как закат солнца отмечает момент, когда солнце исчезает ниже горизонта вечером.” Через этот метод модель фактически учится следовать инструкциям и выполнять их.
Этот подход существенно влияет на процесс подсказки LLM, что приводит к радикальному сдвигу в стиле подсказки. Инструкционно-дообученная LLM позволяет немедленное выполнение задач zero-shot, обеспечивая безшовное выполнение задач. Если LLM еще не дообучена, может быть необходим подход few-shot обучения, включающий несколько примеров в вашу подсказку для направления модели на желаемый ответ.
“Инструкционное дообучение с GPT-4′ обсуждает попытку использовать GPT-4 для генерации данных для дообучения LLM. Они использовали богатый набор данных, состоящий из 52 000 уникальных инструкций для дообучения в английском и китайском языках.
Набор данных играет решающую роль в инструкционном дообучении моделей LLaMA, открытой серии LLM, в результате чего улучшилась нулевая производительность на новых задачах. Заметные проекты, такие как Stanford Alpaca, эффективно использовали самоинструкционное дообучение, эффективный метод выравнивания LLM с человеческими намерениями, используя данные, сгенерированные продвинутыми инструкционно-дообученными моделями-учителями.

Основной целью исследований инструкционного дообучения является повышение способностей нулевого и few-shot обобщения LLM. Дальнейшее увеличение данных и масштабирование модели может предоставить ценные идеи. С текущим размером набора данных GPT-4 в 52K и базовой моделью LLaMA в 7 миллиардов параметров, существует огромный потенциал для сбора большего количества данных GPT-4 и объединения их с другими источниками данных, что приведет к обучению более крупных моделей LLaMA для лучшей производительности.
STaR: самонаучение рассуждения
Потенциал LLM особенно заметен в сложных задачах рассуждения, таких как математика или вопросы общих знаний. Однако процесс индукции языковой модели для генерации рассуждений – серии шаг за шагом обоснований или “цепочки мыслей” – имеет свои собственные проблемы. Это часто требует конструкции крупных наборов данных рассуждений или жертвует точностью из-за зависимости только от few-shot вывода.
“Самообучающийся рассуждатель” (STaR) предлагает инновационное решение этим проблемам. Он использует простой цикл для непрерывного улучшения способности модели рассуждать. Этот итеративный процесс начинается с генерации рассуждений для ответа на несколько вопросов, используя несколько рациональных примеров. Если сгенерированные ответы неверны, модель пытается сгенерировать рассуждение еще раз, на этот раз давая правильный ответ. Модель затем дообучается на всех рассуждениях, которые привели к правильным ответам, и процесс повторяется.

STaR методология, демонстрирующая ее цикл дообучения и образец генерации рассуждений на наборе данных CommonsenseQA (https://arxiv.org/pdf/2203.14465.pdf)
Чтобы проиллюстрировать это практическим примером, рассмотрим вопрос “Что можно использовать для переноски небольшой собаки?” с вариантами ответов, варьирующимися от бассейна до корзины. Модель STaR генерирует рассуждение, определяя, что ответ должен быть чем-то, способным переносить небольшую собаку, и останавливается на выводе, что корзина, предназначенная для переноски вещей, является правильным ответом.
Подход STaR уникален, поскольку он использует предварительно существующую способность модели рассуждать. Он использует процесс самообучения и усовершенствования рассуждений, итеративно самонастраивая способность модели рассуждать. Однако цикл STaR имеет свои ограничения. Модель может не решить новые проблемы в наборе данных, поскольку она не получает прямого сигнала обучения для проблем, которые она не может решить. Чтобы решить эту проблему, STaR вводит рационализацию. Для каждой проблемы, которую модель не может решить, она генерирует новое рассуждение, предоставляя модели правильный ответ, что позволяет ей рассуждать в обратном направлении.
STaR, таким образом, является масштабируемым методом самонаучения, который позволяет моделям учиться генерировать свои собственные рассуждения, одновременно учась решать все более сложные проблемы. Применение STaR показало перспективные результаты в задачах арифметики, математических задач и рассуждений общих знаний. На CommonsenseQA STaR улучшил производительность над базовой моделью few-shot и моделью, дообученной для прямого прогнозирования ответов, и выполнил сравнимо с моделью, которая в 30 раз больше.
Метка контекста подсказки
Концепция ‘Метка контекста подсказки‘ вращается вокруг предоставления модели ИИ дополнительного слоя контекста, помечая определенные сведения внутри входных данных. Эти метки по сути служат ориентирами для ИИ, направляя его на то, как интерпретировать контекст точно и генерировать ответ, который является актуальным и точным.
Представьте, что вы ведете разговор с другом о определенной теме, скажем, “шахматы”. Вы делаете заявление, а затем помечаете его ссылкой, такой как “(источник: Википедия)”. Теперь ваш друг, который в данном случае является моделью ИИ, знает точно, откуда взята ваша информация. Этот подход направлен на то, чтобы сделать ответы ИИ более надежными, снижая риск галлюцинаций или генерации ложных фактов.
Уникальным аспектом метки контекста подсказки является ее потенциал для улучшения “контекстного интеллекта” моделей ИИ. Например, статья демонстрирует это, используя разнообразный набор вопросов, извлеченных из различных источников, таких как суммированные статьи Википедии на различные темы и разделы из недавно опубликованной книги. Вопросы помечены, предоставляя модели ИИ дополнительный контекст о источнике информации.
Этот дополнительный слой контекста может оказаться невероятно полезным, когда речь идет о генерации ответов, которые не только точны, но и соответствуют предоставленному контексту, что делает выходные данные ИИ более надежными и заслуживающими доверия.
Заключение: взгляд на перспективные техники и будущие направления
ChatGPT от OpenAI демонстрирует неисследованный потенциал крупных языковых моделей (LLM) в решении сложных задач с замечательной эффективностью. Продвинутые техники, такие как few-shot обучение, ReAct подсказка, chain-of-thought и STaR, позволяют нам использовать этот потенциал в широком диапазоне применений. Когда мы глубже погружаемся в нюансы этих методологий, мы обнаруживаем, как они формируют ландшафт ИИ, предлагая более богатые и безопасные взаимодействия между людьми и машинами.
Несмотря на проблемы, такие как конфликт знаний, чрезмерная зависимость от параметрических знаний и потенциал галлюцинации, эти модели ИИ, с правильной инженерией подсказок, доказали себя революционными инструментами. Инструкционное дообучение, контекстно-верная подсказка и интеграция с внешними источниками данных еще больше усиливают их способность рассуждать, учиться и адаптироваться.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}