Искусственный интеллект
AudioSep : Отделяйте Все, Что Вы Описываете
LASS или Language-queried Audio Source Separation – это новая парадигма для CASA или Computational Auditory Scene Analysis, целью которой является разделение целевого звука из данной смеси аудио с помощью естественного языкового запроса, который обеспечивает естественный, но масштабируемый интерфейс для цифровых аудио задач и приложений. Хотя рамки LASS значительно продвинулись в последние годы в плане достижения желаемой производительности на конкретных аудио источниках, таких как музыкальные инструменты, они не могут разделить целевой аудио в открытом домене.
AudioSep, является фундаментальной моделью, целью которой является решение текущих ограничений рамок LASS, обеспечивая разделение целевого аудио с помощью естественного языкового запроса. Разработчики рамки AudioSep обширно обучили модель на широком разнообразии крупномасштабных многомодальных наборов данных и оценили производительность рамки на широком массиве аудио задач, включая разделение музыкальных инструментов, разделение аудио событий и улучшение речи среди многих других. Первоначальная производительность AudioSep удовлетворяет эталонам, поскольку демонстрирует впечатляющие возможности обучения с нуля и обеспечивает сильную производительность разделения аудио.
В этой статье мы более глубоко рассмотрим работу рамки AudioSep, поскольку мы будем оценивать архитектуру модели, наборы данных, используемые для обучения и оценки, и основные концепции, участвующие в работе модели AudioSep. Итак, начнем с базового введения в рамку CASA.
CASA, USS, QSS, LASS Фреймворки : Основой для AudioSep
CASA или Computational Auditory Scene Analysis фреймворк – это фреймворк, используемый разработчиками для проектирования систем машинного прослушивания, которые имеют возможность воспринимать сложные звуковые среды подобно тому, как люди воспринимают звук с помощью своих слуховых систем. Звуковое разделение, с особым акцентом на разделение целевого звука, является фундаментальной областью исследований в рамках фреймворка CASA, и оно направлено на решение проблемы “коктейльной вечеринки” или разделения реальных аудио записей от отдельных аудио источников или файлов. Важность звукового разделения можно отнести в основном к его широкому применению, включая музыкальное разделение источников, аудио разделение источников, улучшение речи, определение целевого звука и многое другое.
Большая часть работы по звуковому разделению, выполненная в прошлом, вращается в основном вокруг разделения одного или нескольких аудио источников, таких как музыкальное разделение или разделение речи. Новая модель, называемая USS или Universal Sound Separation, направлена на разделение произвольных звуков в реальных аудио записях. Однако это сложная и ограничительная задача разделить каждый звуковой источник из аудио смеси, прежде всего из-за широкого разнообразия различных звуковых источников, существующих в мире, что является основной причиной, по которой метод USS не является осуществимым для реальных приложений, работающих в реальном времени.
Осуществимой альтернативой методу USS является QSS или Query-based Sound Separation метод, который направлен на разделение отдельного или целевого звукового источника из аудио смеси на основе определенного набора запросов. Благодаря этому, фреймворк QSS позволяет разработчикам и пользователям извлекать желаемые источники аудио из смеси на основе их требований, что делает метод QSS более практическим решением для цифровых реальных приложений, таких как мультимедийное редактирование контента или аудио редактирование.
Кроме того, разработчики недавно предложили расширение фреймворка QSS, фреймворк LASS или Language-queried Audio Source Separation, который направлен на разделение произвольных источников звука из аудио смеси, используя естественные языковые описания целевого аудио источника. Поскольку фреймворк LASS позволяет пользователям извлекать целевые аудио источники, используя набор естественных языковых инструкций, он может стать мощным инструментом с широким применением в цифровых аудио приложениях. По сравнению с традиционными аудио-запросными или зрительно-запросными методами, использование естественных языковых инструкций для аудио разделения предлагает большую степень преимущества, поскольку добавляет гибкость и делает получение информации запроса намного проще и удобнее. Кроме того, по сравнению с метка-запросными фреймворками аудио разделения, которые используют предварительно определенный набор инструкций или запросов, фреймворк LASS не ограничивает количество входных запросов и имеет гибкость, чтобы быть обобщенным в открытом домене без проблем.
Изначально, фреймворк LASS полагается на обучение с учителем, при котором модель обучается на наборе помеченных аудио-текстовых пар данных. Однако основной проблемой этого подхода является ограниченная доступность аннотированных и помеченных аудио-текстовых данных. Чтобы уменьшить зависимость фреймворка LASS от аннотированных аудио-текстовых помеченных данных, модели обучаются с помощью многомодального надзорного обучения. Основная цель использования многомодального надзорного подхода заключается в использовании многомодальных контрастных предварительно обученных моделей, таких как модель CLIP или Contrastive Language Image Pre Training, в качестве запроса кодировщика для фреймворка. Поскольку фреймворк CLIP имеет возможность выравнивать текстовые вложения с другими модальностями, такими как аудио или зрение, он позволяет разработчикам обучать модели LASS, используя данные, богатые модальностями, и позволяет вмешиваться в текстовые данные в настройке с нуля. Текущие фреймворки LASS, однако, используют небольшие масштабные наборы данных для обучения, и применения фреймворка LASS в сотнях потенциальных доменов еще предстоит исследовать.
Чтобы решить текущие ограничения, с которыми сталкиваются фреймворки LASS, разработчики представили AudioSep, фундаментальную модель, целью которой является разделение звука из аудио смеси, используя естественные языковые описания. Текущий фокус для AudioSep заключается в разработке предварительно обученной модели разделения звука, которая использует существующие крупномасштабные многомодальные наборы данных, чтобы обеспечить обобщение моделей LASS в открытом домене. Чтобы суммировать, модель AudioSep – это: ” Фундаментальная модель для универсального разделения звука в открытом домене, используя естественные языковые запросы или описания, обученная на крупномасштабных аудио- и многомодальных наборах данных “.
AudioSep : Ключевые Компоненты и Архитектура
Архитектура фреймворка AudioSep состоит из двух ключевых компонентов: текстового кодировщика и модели разделения.
Текстовый Кодировщик
Фреймворк AudioSep использует текстовый кодировщик модели CLIP или Contrastive Language Image Pre Training или модели CLAP или Contrastive Language Audio Pre Training, чтобы извлечь текстовые вложения внутри естественного языкового запроса. Входной текстовый запрос состоит из последовательности ” N ” токенов, который затем обрабатывается текстовым кодировщиком, чтобы извлечь текстовые вложения для данного входного языкового запроса. Текстовый кодировщик использует стек трансформерных блоков, чтобы закодировать входные текстовые токены, и выходные представления агрегируются после того, как они проходят через трансформерные слои, что приводит к разработке D-мерного векторного представления с фиксированной длиной, где D соответствует размерности моделей CLAP или CLIP, а текстовый кодировщик заморожен во время обучения.
Модель CLIP предварительно обучена на крупномасштабном наборе данных изображений и текста, используя контрастное обучение, что является основной причиной, по которой текстовый кодировщик модели учится выравнивать текстовые описания в семантическом пространстве, которое также разделяется визуальными представлениями. Преимущество, которое AudioSep получает от использования текстового кодировщика CLIP, заключается в том, что он может теперь масштабироваться или обучать модель LASS из неаннотированных аудио-визуальных данных, используя визуальные вложения в качестве альтернативы, что позволяет обучать модели LASS без требования аннотированных или помеченных аудио-текстовых данных.
Модель CLAP работает аналогично модели CLIP и использует контрастную цель обучения, поскольку она использует текстовый и аудио кодировщик, чтобы соединить аудио и язык, что позволяет текстовым и аудио описаниям находиться в аудио-текстовом латентном пространстве.
Модель Разделения
Фреймворк AudioSep использует модель ResUNet в области частот, которая подается в смесь аудио клипов в качестве разделения основы для фреймворка. Фреймворк работает, применяя STFT или Short-Time Fourier Transform к волновой форме, чтобы извлечь комплексный спектрограмму, магнитудную спектрограмму и фазу X. Модель затем следует одной и той же настройке и строит кодировщик-декодировщик сеть, чтобы обработать магнитудную спектрограмму.
Сеть ResUNet кодировщик-декодировщик состоит из 6 резидуальных блоков, 6 декодировщиков и 4 бутылочных блоков. Спектрограмма в каждом кодировщике блоке использует 4 резидуальных свертки блоков, чтобы уменьшить себя до бутылочного признака, в то время как декодировщик блоки используют 4 резидуальных деконволюционных блоков, чтобы получить разделенные компоненты, увеличивая признаки. Следуя этому, каждый из кодировщиков блоков и его соответствующий декодировщик блок устанавливают пропускную связь, которая работает на одном и том же увеличении или уменьшении скорости. Резидуальный блок фреймворка состоит из 2 Leaky-ReLU активационных слоев, 2 слоев нормализации пакетов и 2 свертки слоев, и, кроме того, фреймворк вводит дополнительную резидуальную сокращение, которая соединяет вход и выход каждого отдельного резидуального блока. Модель ResUNet принимает комплексный спектрограмму X в качестве входных данных и производит магнитудную маску M в качестве выходных данных, с фазным остатком, обусловленным текстовыми вложениями, что контролирует величину масштабирования и вращения угла спектрограммы. Разделенная комплексная спектрограмма может быть затем извлечена, умножая предсказанную магнитудную маску и фазный остаток с STFT (Short-Time Fourier Transform) смеси.

В своей фреймворке AudioSep использует FiLm или Feature-wise Linearly модулированный слой, чтобы соединить модель разделения и текстовый кодировщик после развертывания свертки блоков в ResUNet.
Обучение и Потери
Во время обучения модели AudioSep, разработчики используют метод усиления громкости, и обучают фреймворк AudioSep от конца до начала, используя функцию потерь L1 между фактическими и предсказанными волновыми формами.
Наборы Данных и Эталонные Тесты
Как упоминалось в предыдущих разделах, AudioSep – это фундаментальная модель, целью которой является решение текущей зависимости моделей LASS от аннотированных аудио-текстовых пар данных. Модель AudioSep обучена на широком разнообразии наборов данных, чтобы обеспечить ее многомодальными обучающими возможностями, и ниже приведено подробное описание набора данных и эталонных тестов, используемых разработчиками для обучения фреймворка AudioSep.
AudioSet
AudioSet – это слабо помеченный крупномасштабный аудио набор данных, состоящий из более 2 миллионов 10-секундных аудио фрагментов, извлеченных直接 из YouTube. Каждый аудио фрагмент в наборе данных AudioSet категоризируется по отсутствию или присутствию звуковых классов без конкретных временных деталей звуковых событий. Набор данных AudioSet имеет более 500 различных аудио классов, включая природные звуки, человеческие звуки, транспортные звуки и многое другое.
VGGSound
Набор данных VGGSound – это крупномасштабный визуально-аудио набор данных, который, как и AudioSet, был получен напрямую из YouTube, и он содержит более 200 000 видео клипов, каждый из которых имеет длину 10 секунд. Набор данных VGGSound категоризируется в более 300 звуковых классов, включая человеческие звуки, природные звуки, птичьи звуки и многое другое. Использование набора данных VGGSound обеспечивает, что объект, ответственный за производство целевого звука, также описываем в соответствующем визуальном клипе.
AudioCaps
AudioCaps – это самый большой аудио подписанный набор данных, доступный публично, и он состоит из более 50 000 10-секундных аудио клипов, извлеченных из набора данных AudioSet. Данные в AudioCaps разделены на три категории: обучающие данные, тестовые данные и валидационные данные, и аудио клипы аннотированы человеческими естественными языковыми описаниями, используя платформу Amazon Mechanical Turk. Стоит отметить, что каждый аудио клип в обучающем наборе данных имеет одну подпись, в то время как данные в тестовом и валидационном наборах имеют по 5 фактических подписей.
ClothoV2
ClothoV2 – это аудио подписанный набор данных, который состоит из клипов, полученных из платформы FreeSound, и, как и AudioCaps, каждый аудио клип аннотирован человеческими естественными языковыми описаниями, используя платформу Amazon Mechanical Turk.
WavCaps
Как и AudioSet, WavCaps – это слабо помеченный крупномасштабный аудио набор данных, состоящий из более 400 000 аудио клипов с подписями, и общее время воспроизведения, приближающееся к 7568 часам обучающих данных. Аудио клипы в наборе данных WavCaps получены из широкого разнообразия аудио источников, включая BBC Sound Effects, AudioSet, FreeSound, SoundBible и многое другое.

Детали Обучения
Во время фазы обучения, модель AudioSep случайным образом выбирает два аудио сегмента из двух разных аудио клипов из обучающего набора данных, и затем смешивает их вместе, чтобы создать обучающую смесь, где длина каждого аудио сегмента составляет около 5 секунд. Модель затем извлекает комплексный спектрограмму из волновой формы сигнала, используя Hann окно размером 1024 с шагом 320.
Модель затем использует текстовый кодировщик моделей CLIP/CLAP, чтобы извлечь текстовые вложения, с текстовым надзором в качестве стандартной конфигурации для AudioSep. Для модели разделения фреймворк AudioSep использует слой ResUNet, состоящий из 30 слоев, 6 кодировщиков и 6 декодировщиков, напоминающий архитектуру, используемую в универсальном разделении звука. Кроме того, каждый кодировщик блок имеет два свертки слоя с размером ядра 3×3, с количеством выходных функций кодировщиков блоков, равным 32, 64, 128, 256, 512 и 1024 соответственно. Декодировщик блоки делят симметрию с кодировщиками блоками, и разработчики применяют оптимизатор Adam, чтобы обучить модель AudioSep с размером пакета 96.
Результаты Оценки
На Видимых Наборах Данных
Следующая фигура сравнивает производительность фреймворка AudioSep на видимых наборах данных во время фазы обучения, включая обучающие наборы данных. Ниже приведенная фигура представляет результаты оценки фреймворка AudioSep при сравнении с базовыми системами, включая модели улучшения речи, LASS и CLIP. Модель AudioSep с текстовым кодировщиком CLIP представлена как AudioSep-CLIP, в то время как модель AudioSep с текстовым кодировщиком CLAP представлена как AudioSep-CLAP.

Как можно увидеть на фигуре, фреймворк AudioSep работает хорошо, когда использует аудио подписи или текстовые метки в качестве входных запросов, и результаты указывают на превосходную производительность фреймворка AudioSep при сравнении с предыдущими эталонными моделями LASS и аудио-запросными моделями разделения звука.
На Невидимых Наборах Данных
Чтобы оценить производительность AudioSep в настройке с нуля, разработчики продолжили оценку производительности на невидимых наборах данных, и фреймворк AudioSep обеспечивает впечатляющую производительность разделения в настройке с нуля, и результаты представлены на фигуре ниже.

Кроме того, изображение ниже показывает результаты оценки модели AudioSep против Voicebank-Demand улучшения речи.

Оценка фреймворка AudioSep указывает на сильную и желаемую производительность на невидимых наборах данных в настройке с нуля, и таким образом открывает путь для выполнения операций со звуком на новых распределениях данных.
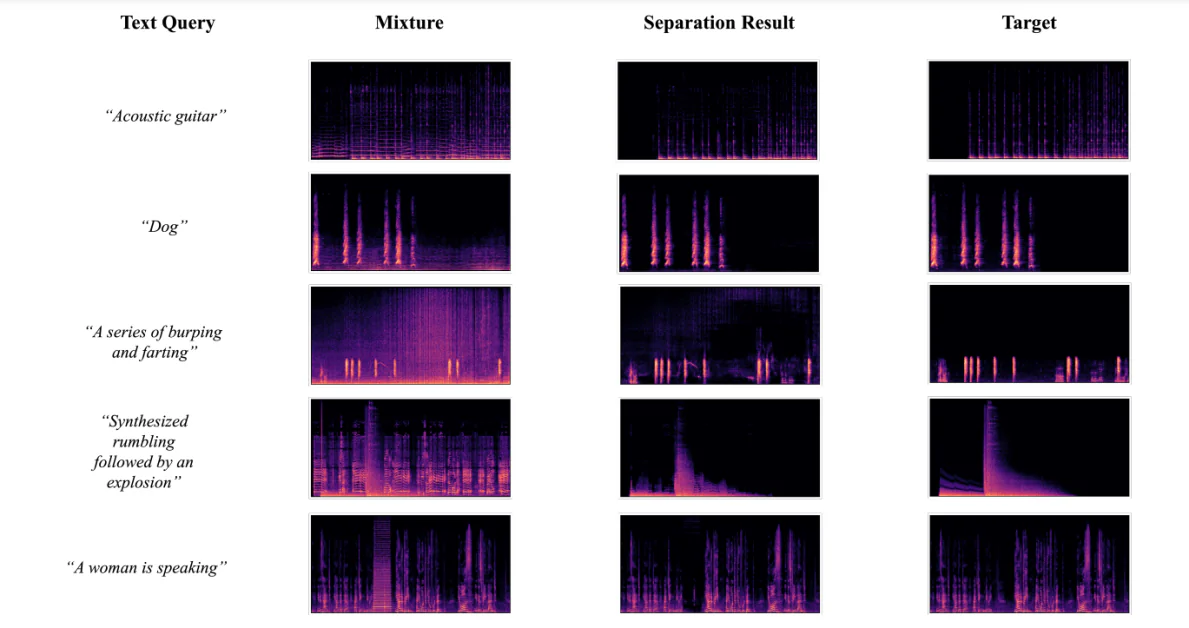
Визуализация Результатов Разделения
Ниже приведенная фигура показывает результаты, полученные, когда разработчики использовали фреймворк AudioSep-CLAP, чтобы выполнить визуализацию спектрограмм для фактических целевых аудио источников, аудио смесей и разделенных аудио источников, используя текстовые запросы различных аудио или звуков. Результаты позволили разработчикам наблюдать, что закономерность разделенной спектрограммы источника близка к источнику фактического, что еще больше подтверждает объективные результаты, полученные во время экспериментов.
Сравнение Текстовых Запросов
Разработчики оценили производительность AudioSep-CLAP и AudioSep-CLIP на AudioCaps Mini, и разработчики используют метки событий AudioSet, подписи AudioCaps и переаннотированные естественные языковые описания, чтобы изучить эффекты различных запросов, и ниже приведен пример AudioCaps Mini в действии.

Вывод
AudioSep – это фундаментальная модель, разработанная с целью быть открытым доменом универсальным разделением звука, которое использует естественные языковые описания для разделения аудио. Как было наблюдено во время оценки, фреймворк AudioSep способен выполнять обучение с нуля и без надзора, используя аудио подписи или текстовые метки в качестве запросов. Результаты и оценка производительности AudioSep указывают на сильную производительность, которая превосходит текущее состояние моделей разделения звука, таких как LASS, и она может быть способна решить текущие ограничения популярных моделей разделения звука.












