
Artificial Intelligence
Решение проблемы артефактов JPEG в наборах данных компьютерного зрения
Новое исследование Университета Мэриленда и Facebook AI обнаружило «значительное снижение производительности» для систем глубокого обучения, которые используют сильно сжатые изображения JPEG в своих наборах данных, и предлагает несколько новых методов для смягчения последствий этого.
Ассоциация отчету, Под названием Анализ и устранение дефектов сжатия JPEG в глубоком обучении, утверждает, что является «значительно более полным», чем предыдущие исследования влияния артефактов при обучении наборов данных компьютерного зрения. В документе обнаруживается, что «[тяжелое] или умеренное сжатие JPEG приводит к значительному снижению производительности по стандартным метрикам» и что нейронные сети, возможно, не так устойчивы к таким возмущениям, как предыдущая работа. свидетельствуют.

Фотография собаки из набора данных MobileNetV2018 2 года. При качестве 10 (слева) система классификации не может определить правильную породу «вельш-корги пемброк», вместо этого угадывая «норвич-терьер» (система уже знает, что это фотография собаки, но не порода); второй слева: стандартная версия изображения в формате JPEG с исправленными артефактами снова не может определить правильную породу; второй справа, целевое исправление артефактов восстанавливает правильную классификацию; и правильно, оригинальное фото, правильно классифицированное. Источник: https://arxiv.org/pdf/2011.08932.pdf
Артефакты сжатия как «данные»
Экстремальное сжатие JPEG, вероятно, создаст видимые или полувидимые границы вокруг изображения. 8×8 блока из которого JPEG собирается в пиксельную сетку. Как только появятся эти блокирующие или «звенящие» артефакты, они, скорее всего, будут неправильно интерпретированы системами машинного обучения как элементы реального мира объекта изображения, если за это не будет сделана некоторая компенсация.

Выше система машинного обучения компьютерного зрения извлекает «чистое» градиентное изображение из изображения хорошего качества. Ниже «блокирующие» артефакты в низкокачественном сохранении изображения скрывают особенности объекта и могут в конечном итоге «заразить» функции, полученные из набора изображений, особенно в случаях, когда в наборе данных встречаются изображения высокого и низкого качества. , например, в коллекциях, извлеченных из Интернета, к которым применялась только общая очистка данных. Источник: http://www.cs.utep.edu/ofuentes/papers/quijasfuentes2014.pdf.
Как видно на первом изображении выше, такие артефакты могут влиять на задачи классификации изображений, что также влияет на алгоритмы распознавания текста, которые могут не правильно идентифицировать затронутые артефактами символы.
В случае систем обучения синтезу изображений (таких как программное обеспечение дипфейка или системы генерации изображений на основе GAN) «мошеннический» блок низкокачественных, сильно сжатых изображений в наборе данных может либо снизить среднее качество воспроизведения, либо еще быть включены и по существу переопределены большим количеством признаков более высокого качества, извлеченных из лучших изображений в наборе. В любом случае желательны более качественные данные или, по крайней мере, непротиворечивые данные.
JPEG – обычно «достаточно хорош»
Сжатие JPEG — это кодек с необратимыми потерями, который можно применять к различным форматам изображений, хотя в основном он применяется к файлу изображения JFIF. обертка. Несмотря на это, формат JPEG (.jpg) был назван в честь связанного с ним метода сжатия, а не оболочки JFIF для данных изображения.
В последние годы появились целые архитектуры машинного обучения, которые включают устранение артефактов в стиле JPEG как часть процедур масштабирования/восстановления, управляемых ИИ, а удаление артефактов сжатия на основе ИИ теперь включено в ряд коммерческих продуктов, таких как Topaz image/ видео suite, и нейронные особенности последних версий Adobe Photoshop.
С 1986 Схема JPEG, широко используемая в настоящее время, была в значительной степени заблокирована в начале 1990-х годов, невозможно добавить к изображению метаданные, которые указывали бы, на каком уровне качества (1-100) было сохранено изображение JPEG — по крайней мере, не без изменения более чем тридцать лет устаревших потребительских, профессиональных и академических программных систем, которые не ожидали, что такие метаданные будут доступны.
Следовательно, нередко программы обучения машинному обучению адаптируются к оцененному или известному качеству данных изображений JPEG, как это сделали исследователи для новой статьи (см. ниже). В отсутствие записи метаданных «качество» в настоящее время необходимо либо знать подробности того, как изображение было сжато (то есть сжато из источника без потерь), либо оценивать качество с помощью алгоритмов восприятия или ручной классификации.
Экономический компромисс
JPEG — не единственный метод сжатия с потерями, который может повлиять на качество наборов данных машинного обучения; настройки сжатия в файлах PDF также могут таким образом отбрасывать информацию и устанавливать очень низкие уровни качества, чтобы сэкономить место на диске для целей локального или сетевого архивирования.
В этом можно убедиться, взяв образцы различных PDF-файлов на сайте archive.org, некоторые из которых были сжаты настолько сильно, что представляют собой серьезную проблему для систем распознавания изображений или текста. Во многих случаях, таких как книги, защищенные авторским правом, такое сильное сжатие, по-видимому, применялось как форма дешевого DRM, во многом таким же образом, как правообладатели могут решить снизить разрешение загруженных пользователями видео на YouTube, на которые они владеют IP. оставить «блочные» видео в качестве рекламных токенов, чтобы вдохновить на покупки в полном разрешении, а не удалять их.
Во многих других случаях разрешение или качество изображения низкие просто потому, что данные очень старые и происходят из эпохи, когда локальное и сетевое хранилище было более дорогим, а ограниченная скорость сети отдавала предпочтение высокооптимизированным и портативным изображениям, а не высококачественному воспроизведению. .
Утверждалось, что JPEG, хотя и не лучшее решение сейчас, был «закреплен» как неотъемлемая устаревшая инфраструктура, которая по существу переплетена с основами Интернета.
Бремя наследия
Хотя более поздние инновации, такие как JPEG 2000, PNG и (совсем недавно) формат .webp, обеспечивают превосходное качество, повторная выборка старых, очень популярных наборов данных машинного обучения, возможно, «сбросит» преемственность и историю ежегодных проблем компьютерного зрения. в академическом сообществе - препятствие, которое будет применяться также в случае повторного сохранения изображений набора данных PNG с настройками более высокого качества. Это можно рассматривать как своего рода технический долг.
В то время как почтенные серверные библиотеки обработки изображений, такие как ImageMagick, поддерживают лучшие форматы, включая .webp, требования к преобразованию изображений часто возникают в устаревших системах, которые не настроены ни для чего другого, кроме JPG или PNG (которые обеспечивают сжатие без потерь, но за счет задержка и место на диске). Даже WordPress, CMS, на котором почти 40% всех веб-сайтов, добавлена только поддержка .webp три месяца назад.
PNG был поздним (возможно, слишком поздним) входом в сектор форматов изображений, возникшим как решение с открытым исходным кодом во второй половине 1990-х годов в ответ на декларация 1995 года Unisys и CompuServe, что отныне будут выплачиваться лицензионные отчисления за формат сжатия LZW, используемый в файлах GIF, которые в то время обычно использовались для логотипов и элементов плоского цвета, даже если формат воскресение в начале 2010-х была сосредоточена на его способности предоставлять динамичный анимированный контент с низкой пропускной способностью (по иронии судьбы, анимированные PNG никогда не пользовались популярностью или широкой поддержкой, и даже были запрещено в Twitter В 2019).
Несмотря на свои недостатки, сжатие JPEG является быстрым, компактным и глубоко внедренным в системы всех типов, и поэтому вряд ли полностью исчезнет со сцены машинного обучения в ближайшем будущем.
Максимальное использование разрядки AI/JPEG
В какой-то степени сообщество машинного обучения приспособилось к недостаткам сжатия JPEG: в 2011 году Европейское общество радиологии (ESR) опубликовало Исследование на «Возможности использования необратимого сжатия изображений в радиологических изображениях», предоставляя рекомендации по «приемлемым» потерям; когда почтенный МНИСТ набор данных для распознавания текста (данные изображения которого изначально поставлялись в новом двоичном формате) был перенесен в «обычный» формат изображения, JPEG, а не PNG, был выбран; и более раннее (2020 г.) сотрудничество авторов новой статьи предложило 'новая архитектура' для калибровки систем машинного обучения с учетом недостатков различного качества изображения JPEG без необходимости обучения моделей для каждой настройки качества JPEG — функция, используемая в новой работе.
Действительно, исследование полезности данных JPEG с разным качеством является относительно процветающей областью машинного обучения. Один (несвязанный) проект 2016 года Центра исследований в области автоматизации Университета Мэриленда, на самом деле центры в домене DCT (где артефакты JPEG возникают при низких настройках качества) как путь к глубокому извлечению признаков; другой проект 2019 года концентрируется на чтение данных JPEG на уровне байтов без трудоемкой необходимости фактически распаковывать изображения (т.е. открывать их в какой-то момент автоматизированного рабочего процесса); и Исследование из Франции в 2019 году активно использует сжатие JPEG для процедур распознавания объектов.
Тестирование и выводы
Возвращаясь к последнему исследованию, проведенному UoM и Facebook, исследователи попытались проверить удобочитаемость и полезность JPEG на изображениях, сжатых в диапазоне 10–90 (ниже этого значения изображение невозможно искажается, а выше — равно сжатию без потерь). Изображения, использованные в тестах, были предварительно сжаты для каждого значения в пределах целевого диапазона качества, что повлекло за собой не менее восьми сеансов обучения.
Модели обучались стохастическому градиентному спуску четырьмя методами: базовая линия, где не было добавлено никаких дополнительных средств защиты; контролируемая доводка, где обучающий набор имеет преимущество предварительно обученных весов и помеченных данных (хотя исследователи признают, что это трудно воспроизвести в приложениях потребительского уровня); коррекция артефактов, где перед обучением на сжатых изображениях выполняется аугментация/улучшение; и направленная на задачу коррекция артефактов, где корректная сеть артефактов точно настроена на возвращаемые ошибки.
Обучение проводилось на самых разных подходящих наборах данных, включая несколько вариантов ResNet, ФастRCNN, Мобильная сеть V2, МаскаRCNN и Керас НачалоV3.
Результаты потери выборки после коррекции артефактов, ориентированных на задачу, визуализируются ниже (ниже = лучше).
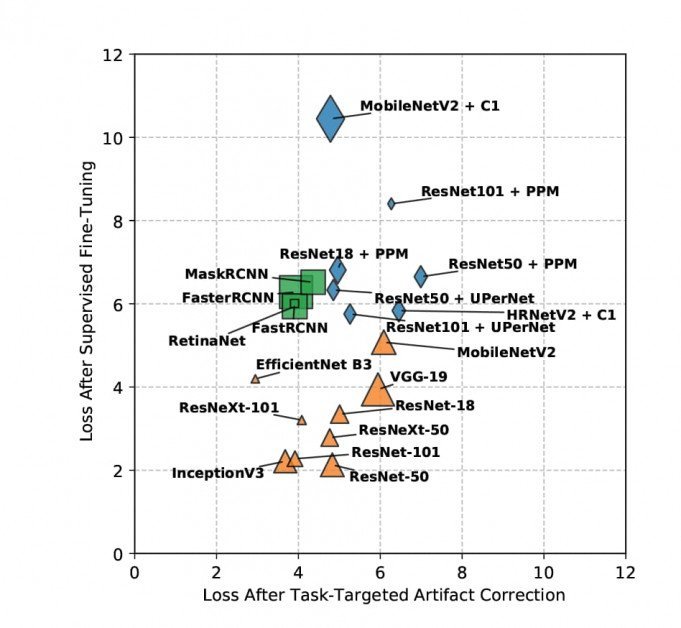
Невозможно углубиться в детали результатов, полученных в ходе исследования, потому что выводы исследователей разделены между целью оценки артефактов JPEG и новыми методами для облегчения этого; обучение было повторено за качество над таким количеством наборов данных; и задачи включали несколько целей, таких как обнаружение объектов, сегментация и классификация. По сути, новый отчет позиционируется как всеобъемлющий справочник, посвященный множеству вопросов.
Тем не менее, в документе делается общий вывод о том, что «сжатие JPEG влечет за собой резкое снижение по всем направлениям для тяжелых и умеренных настроек сжатия». Он также утверждает, что его новые немаркированные стратегии смягчения последствий достигают лучших результатов по сравнению с другими аналогичными подходами; что для сложных задач контролируемый исследователями метод также превосходит своих аналогов, несмотря на то, что у него нет доступа к ярлыкам наземной истины; и что эти новые методологии позволяют повторно использовать модели, поскольку полученные веса можно передавать между задачами.
Что касается задач классификации, в документе прямо говорится, что «JPEG ухудшает качество градиента, а также вызывает ошибки локализации».
Авторы надеются расширить будущие исследования, чтобы охватить другие методы сжатия, такие как в значительной степени игнорируемый JPEG 2000, а также WebP, (включая измененные, и даже если изначально они имели HEIF и БПГ. Они также предполагают, что их методология может быть применена к аналогичным исследованиям алгоритмов сжатия видео.
Поскольку метод коррекции артефактов, нацеленный на задачу, оказался настолько успешным в исследовании, авторы также сообщают о своем намерении выпустить веса, обученные в ходе проекта, ожидая, что «[многие] приложения выиграют от использования наших весов TTAC без изменений».
nb Исходное изображение для статьи взято с сайта thispersondoesnotexist.com.













