
Artificial Intelligence
«Детективный» ИИ может идентифицировать неизвестных людей из нескольких источников

Исследователи из Оксфордского университета разработали систему с поддержкой искусственного интеллекта, которая может всесторонне идентифицировать людей на видео, проводя детективные многопрофильные расследования относительно того, кем они могут быть, исходя из контекста и из различных общедоступных вторичных источников, включая сопоставление аудиоисточников с визуальным материалом из интернета.
Хотя исследования сосредоточены на идентификации общественных деятелей, таких как люди, появляющиеся в телевизионных программах и фильмах, принцип определения личности из контекста теоретически применим к любому, чье лицо, голос или имя появляются в онлайн-источниках.
В самом деле, бумаги собственное определение славы не ограничивается работниками шоу-бизнеса, и исследователи заявляют: «Мы обозначаем людей, у которых много изображений в Интернете, как знаменитый».
Прямо к видео
Исследователи из Оксфордской группы визуальной геометрии при Департаменте инженерных наук описывают исследовательский подход в человеческом стиле, который вдохновил их на эту работу:
«Представьте, что вы смотрите видео и встречаете нового человека. Чтобы с уверенностью идентифицировать их, вы сначала искали подсказки их имени либо в видео, например, в тексте на экране, в упоминании их имени в речи, либо в списке актеров из интернет-архива. Затем вы можете найти некоторые доказательства, подтверждающие правильность этого имени, выполнив поиск этого человека в Интернете».
Методология, предложенная в документе, полностью автоматизирована и устраняет все дополнительные ручные маркировки (за исключением тех, которые были выполнены поставщиками онлайн-источников). Также было доказано, что система хорошо работает с тремя несвязанными наборами данных без какой-либо необходимости адаптации предметной области.
Обсуждая применение работы, исследователи отмечают экспоненциальный рост немаркированных, непрозрачных видеоданных и потребность в новых системах, которые могут извлекать из них идентификационную информацию без дорогостоящих аннотаций под руководством человека:
«[] Огромный масштаб данных в сочетании с отсутствием соответствующих метаданных делает индексацию, анализ и навигацию по этому контенту все более сложной задачей. Полагаться на дополнительные ручные аннотации больше невозможно, и без эффективного способа навигации по этим видео этот банк знаний в значительной степени недоступен».
Механизм индексации такого рода открывает возможность для гиперссылок результатов поиска, которые приходят непосредственно к той точке видео, где появляется объект поиска, как показано в экспериментальном веб-поиске, предоставленном проектом.
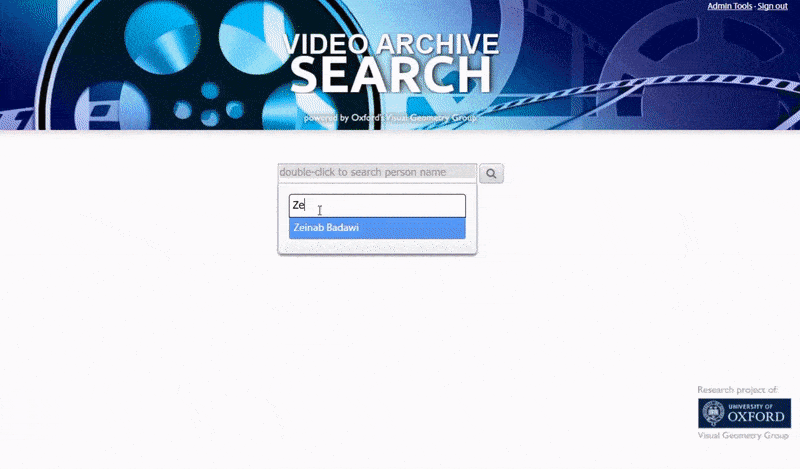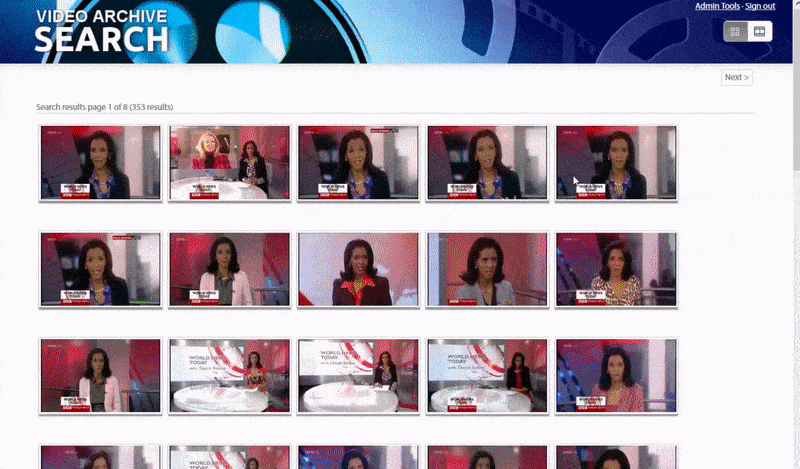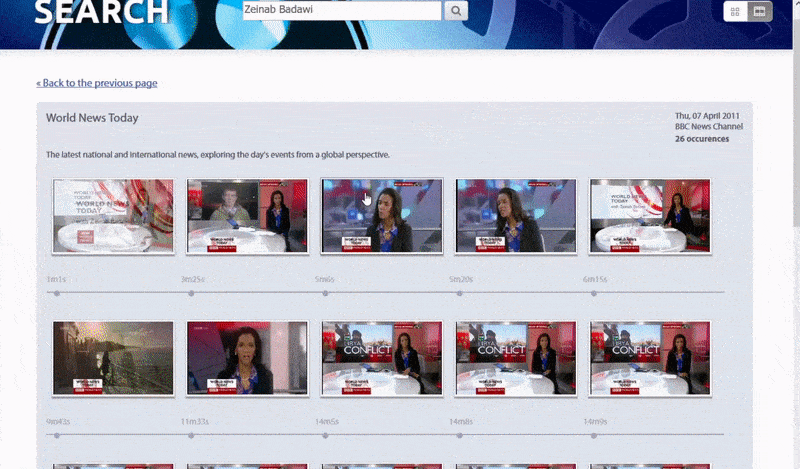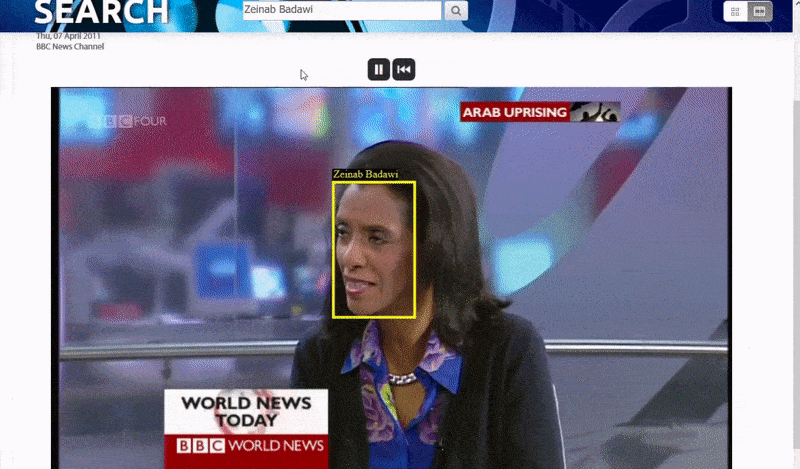
Оксфордская система позволяет искать экземпляры идентифицированного лица. Результат поиска переносит зрителя прямо в ту точку видео, где появляется идентифицированный человек, и затем видео можно воспроизвести с этой точки.. Источник: https://www.robots.ox.ac.uk/~vgg/research/person_id_in_video/
Один из способов, которым система идентифицирует «неизвестных» людей, — это контекст их связи с другими. Следовательно, поисковая система хорошо приспособлена для поиска нескольких личностей, появляющихся в одном и том же видео:
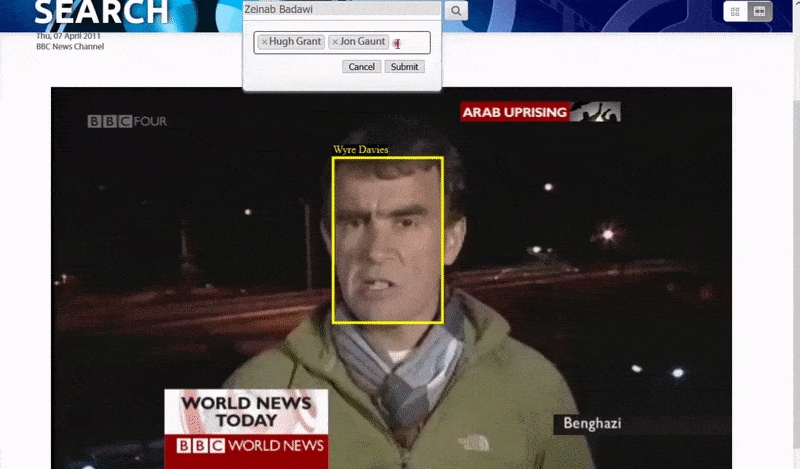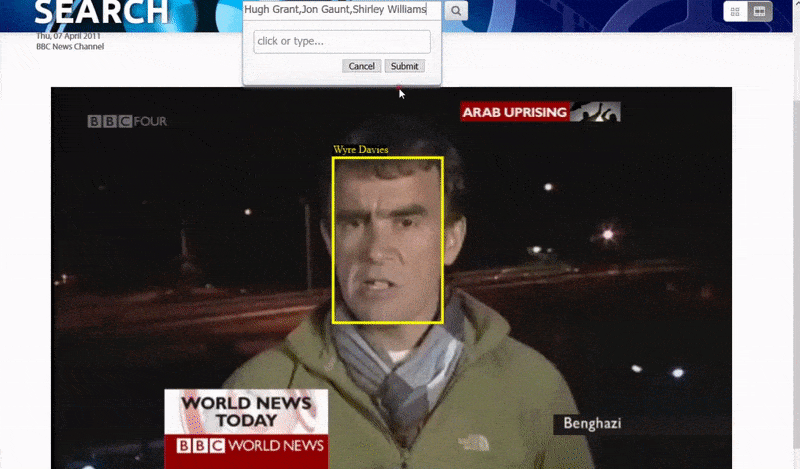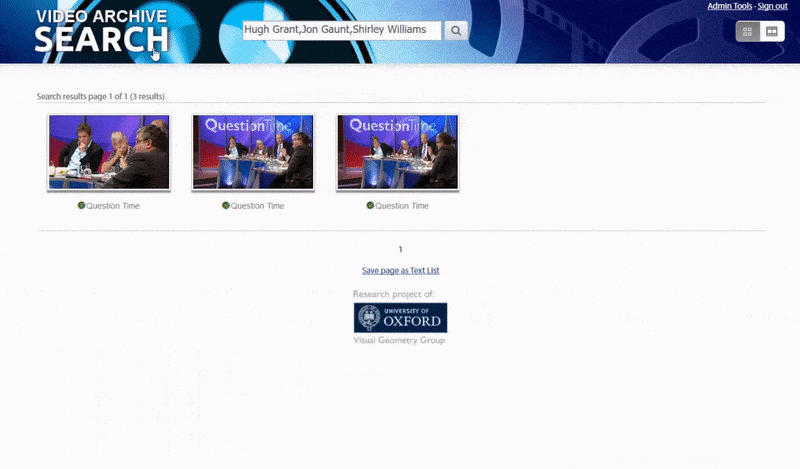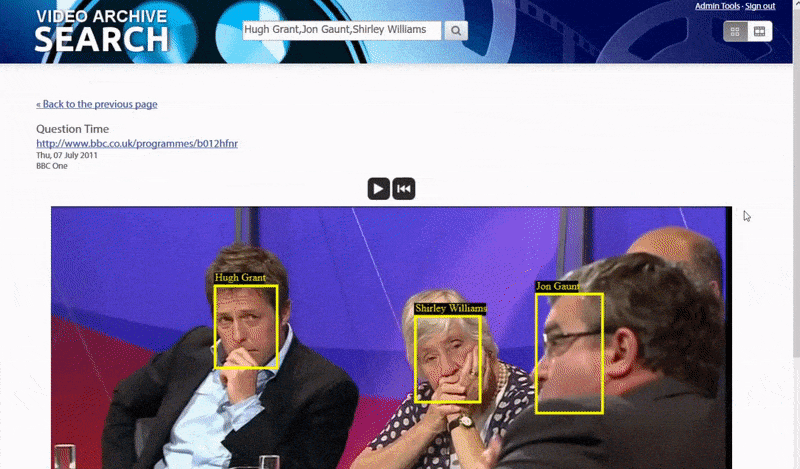
Большая и маленькая рыба
Первоначально система работает с «низко висящими плодами» — людьми, чьи лица настолько хорошо проиндексированы в общедоступных сетевых ресурсах, что их идентификация относительно тривиальна, путем сопоставления метаданных или текста OCR в видео с общедоступными ресурсами данных, такими как IMDB. списки. Интерпретируемый ИИ текст в подписях к видео, титрах и других формах растеризованного текста в видео также используется для идентификации.
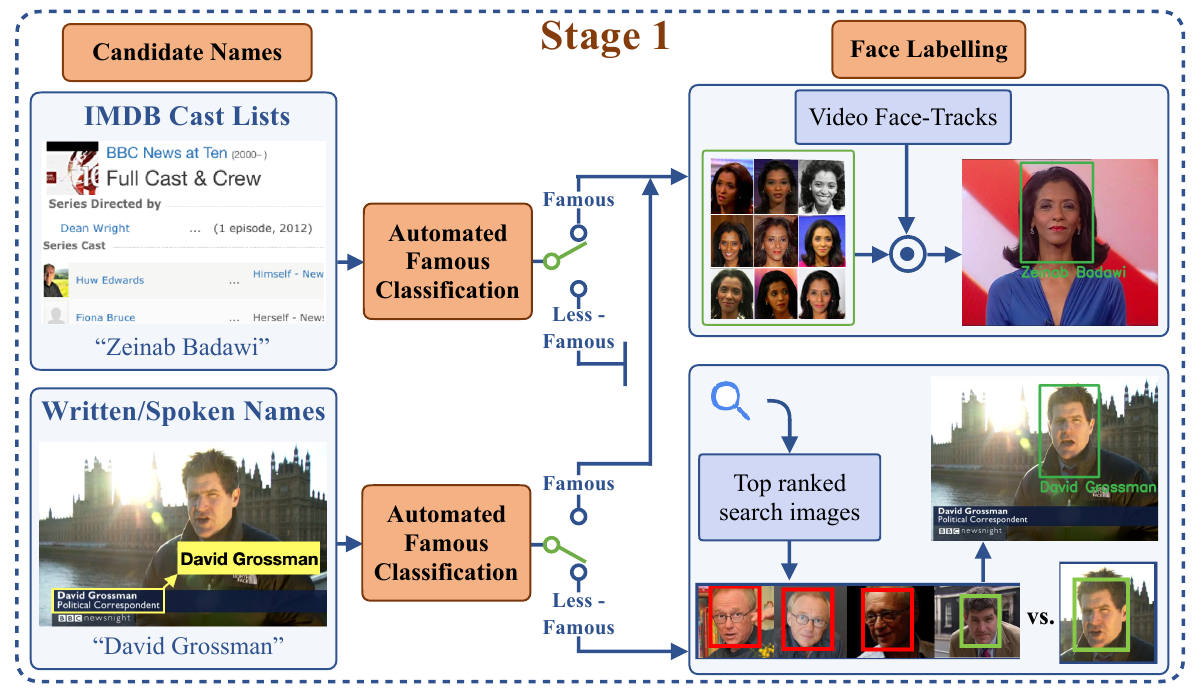
Имена-кандидаты для поиска могут быть обнаружены системой автоматически на основе оптического распознавания символов (OCR) растрового текста или фактического текста в других источниках, таких как списки актеров. Таким образом, люди могут быть проиндексированы автоматически без каких-либо предварительных запросов к их именам отдельными конечными пользователями и без предварительного участия в социальных сетях с поддержкой ИИ. Источник: https://www.robots.ox.ac.uk/~vgg/publications/2021/Brown21/brown21.pdf
Там, где подавляющее количество изображений и видео, выходящих в сеть, подтверждают личность человека, расследование подтверждает личность. Но там, где человек более неизвестен, используются другие методы, в том числе звук, взятый из видеодорожек, который можно использовать в качестве подтверждающего подтверждения личности. Хотя это и не рассматривается в работе, логически нет ничего, что могло бы остановить структуру такого рода, в которой также используются чистые аудиоисточники, а также аудиокомпоненты в видео.
Паноптикум самораспространяющейся идентичности
Помимо создания имен-кандидатов из растеризованного или чистого текста, в Оксфордском проекте используются технологии распознавания речи для распознавания имен, которые просто говорят в аудиоконтенте. Таким образом, личность может быть инициализирована одним или двумя людьми, просто упоминающими третье лицо, которого нет.
Гарантия, которую вводит Оксфордский проект, заключается в том, что кандидат должен появиться в базе данных IMDB, но устранение этого произвольного условия значительно расширяет потенциальные возможности системы, поскольку она полностью зависит от ресурсов, доступных для извлечения из Интернета.

Следовательно, с помощью комбинации источников, включая имена, полученные из растрового текста, реального текста, речевых упоминаний и очень ограниченного визуального материала, становится возможным идентифицировать людей с низким присутствием в визуальной сети.
Технически также становится возможным создать профиль человека, с которым еще не было связано изображение или видеозапись, но к которому изображение или видео в конечном итоге могут быть прикреплены, когда другие факторы соотносятся с недавно загруженным источником видео.
Тестовые наборы данных
Исследователи использовали три набора данных для оценки эффективности системы: МедиаЭвал, в котором представлены изображения из социальных сетей Creative Commons и ресурсы сообщества (включая Wikipedia и Flickr), снятые в период с 2010 по 2015 год; Оксфордская группа в 2017 году Набор данных Шерлока, в котором представлены аннотированные видеоданные из популярной современной адаптации BBC классического персонажа Конан Дойля; и новый набор видеоданных BBC, созданный специально для проекта, в котором используются различные аннотированные новостные кадры BBC.

Система успешно работает в широком диапазоне наборов данных, включая случаи, когда лицо закрыто отражениями или темнотой.
В процессе также используется рейтинг поиска изображений в реальном времени.
Результаты системы показали высокую точность для всех трех моделей. В случае с набором данных Шерлока исследователи были удивлены, обнаружив, что новая система улучшилась на 3-6% по сравнению с предыдущим методом, в котором использовались машины опорных векторов (SVM) в многопутевом классификаторе, даже несмотря на то, что классификатор ближайшего соседа, использованный в новая работа — менее мощный инструмент.
Значение
Большинство этических или практических ограничений в Оксфордском проекте налагаются исследователями на себя, например, определение «известности» требованием, чтобы обнаруженные личности присутствовали в IMDB, и путем тестирования системы исключительно на основе установленных академических наборов данных, которые соблюдать лицензирование Creative Commons.
Тем не менее, основная архитектура проекта представляет собой общий метод, позволяющий не только идентифицировать «неизвестных» лиц, мало или совсем не присутствующих в Интернете (поскольку простое упоминание имени может породить идентификационный токен, который может быть разработан со временем по мере необходимости). необходимо), но на самом деле создать матрицу людей, которая движима не чем иным, как рекурсивным и механистическим любопытством, а не спросом или явным присутствием помеченных данных (таких как загрузки фотографий в социальных сетях, которые содержат метаданные PII).
В проекте не используются данные геолокации или другие формы широкодоступных метаданных, которые можно найти в подтверждающих документах, таких как информация о географическом местоположении, встроенная по умолчанию в загрузки в социальные сети (если они не удаляются по желанию пользователя). Тем не менее, нет очевидных препятствий для использования таких дополнительных измерений данных для усиления подтверждающего процесса.
В то время как Оксфордский проект отсекает выбросы (личности, которые почти не присутствуют, помимо того, что не указаны в IMDB) способом, который является обычным в проектах машинного обучения, такая минимальная информация, возможно, может более эффективно идентифицировать неизвестного человека, чем это произошло бы, если бы о них было доступно большее количество репрезентативной информации. Если выбросы — это именно то, что вам нужно (т. е. люди, мало пользующиеся сетью), разреженные данные могут быть весьма показательными.
Доступность
Исследователи из Оксфорда инкапсулировали функциональность проекта в поисковую систему, подобную Google, которую можно загрузить и установить на локальный компьютер через Docker (хотя инструкции по установке в документе от мая 2021 года в настоящее время содержат устаревшую информацию о требовании Docker Tools, которое может помешать процессу).

По-видимому, нет прямой онлайн-версии, которая охватывает реализацию проекта во всех трех наборах данных, хотя результаты для набора данных новостей BBC можно свободно запросить на сайте. http://zeus.robots.ox.ac.uk/bbc_search/.















