Inteligência artificial
Zero123++: Um Modelo de Difusão de Imagem Única para Consistente Multi-Vista

Nos últimos anos, testemunhamos um rápido avanço no desempenho, eficiência e capacidades gerativas de novos modelos de IA gerativos que aproveitam conjuntos de dados extensos e práticas de geração de difusão 2D. Hoje, os modelos de IA gerativos são extremamente capazes de gerar diferentes formas de conteúdo de mídia 2D e, em certa medida, 3D, incluindo texto, imagens, vídeos, GIFs e muito mais.
Neste artigo, vamos falar sobre o framework Zero123++, um modelo de IA gerativo de difusão condicionado por imagem com o objetivo de gerar imagens multi-vista consistentes a partir de uma entrada de vista única. Para maximizar a vantagem ganha com modelos gerativos pré-treinados anteriores, o framework Zero123++ implementa várias técnicas de treinamento e condicionamento para minimizar o esforço necessário para ajustar finamente os modelos de difusão de imagem prontos para uso. Vamos mergulhar mais profundamente na arquitetura, funcionamento e resultados do framework Zero123++ e analisar suas capacidades de gerar imagens multi-vista consistentes de alta qualidade a partir de uma imagem única. Vamos começar.
Zero123 e Zero123++: Uma Introdução
O framework Zero123++ é um modelo de IA gerativo de difusão condicionado por imagem que visa gerar imagens multi-vista consistentes a partir de uma entrada de vista única. O framework Zero123++ é uma continuação do framework Zero123 ou Zero-1-to-3, que aproveita a técnica de síntese de imagem de vista nova zero-shot para pioneirar conversões de imagem única para 3D de código aberto. Embora o framework Zero123++ entregue um desempenho promissor, as imagens geradas pelo framework têm inconsistências geométricas visíveis, e é a principal razão pela qual a lacuna entre cenas 3D e imagens multi-vista ainda existe.
O framework Zero-1-to-3 serve como base para vários outros frameworks, incluindo SyncDreamer, One-2-3-45, Consistent123 e mais, que adicionam camadas extras ao framework Zero123 para obter resultados mais consistentes ao gerar imagens 3D. Outros frameworks, como ProlificDreamer, DreamFusion, DreamGaussian e mais, seguem uma abordagem baseada em otimização para obter imagens 3D, distilando uma imagem 3D de vários modelos inconsistentes. Embora essas técnicas sejam eficazes e gerem imagens 3D satisfatórias, os resultados poderiam ser melhorados com a implementação de um modelo de difusão de base capaz de gerar imagens multi-vista consistentemente. Portanto, o framework Zero123++ aproveita o Zero-1-to-3 e ajusta finamente um novo modelo de difusão de base multi-vista a partir do Stable Diffusion.
No framework Zero-1-to-3, cada vista nova é gerada independentemente, e essa abordagem leva a inconsistências entre as vistas geradas, pois os modelos de difusão têm uma natureza de amostragem. Para lidar com esse problema, o framework Zero123++ adota uma abordagem de layout de mosaico, com o objeto sendo cercado por seis vistas em uma única imagem, e garante o modelamento correto para a distribuição conjunta de imagens multi-vista de um objeto.
Outro desafio importante enfrentado pelos desenvolvedores que trabalham no framework Zero-1-to-3 é que ele subutiliza as capacidades oferecidas pelo Stable Diffusion, o que leva à ineficiência e a custos adicionais. Há duas razões principais pelas quais o framework Zero-1-to-3 não pode maximizar as capacidades oferecidas pelo Stable Diffusion
- Quando treinado com condições de imagem, o framework Zero-1-to-3 não incorpora mecanismos de condicionamento local ou global oferecidos pelo Stable Diffusion de forma eficaz.
- Durante o treinamento, o framework Zero-1-to-3 usa resolução reduzida, uma abordagem na qual a resolução de saída é reduzida abaixo da resolução de treinamento, o que pode reduzir a qualidade da geração de imagens para os modelos de difusão do Stable Diffusion.
Para lidar com esses problemas, o framework Zero123++ implementa uma variedade de técnicas de condicionamento que maximizam a utilização de recursos oferecidos pelo Stable Diffusion e mantêm a qualidade da geração de imagens para os modelos de difusão do Stable Diffusion.
Melhorando o Condicionamento e a Consistência
Em uma tentativa de melhorar o condicionamento de imagem e a consistência de imagem multi-vista, o framework Zero123++ implementou diferentes técnicas, com o objetivo principal de reutilizar técnicas anteriores provenientes do modelo de difusão pré-treinado do Stable Diffusion.
Geração de Multi-Vista
A qualidade indispensável de gerar imagens multi-vista consistentes reside no modelamento correto da distribuição conjunta de múltiplas imagens. No framework Zero-1-to-3, a correlação entre imagens multi-vista é ignorada, pois, para cada imagem, o framework modela a distribuição marginal condicional independentemente e separadamente. No entanto, no framework Zero123++, os desenvolvedores optaram por uma abordagem de layout de mosaico que coloca 6 imagens em uma única moldura/imagem para geração de multi-vista consistente, e o processo é demonstrado na seguinte imagem.
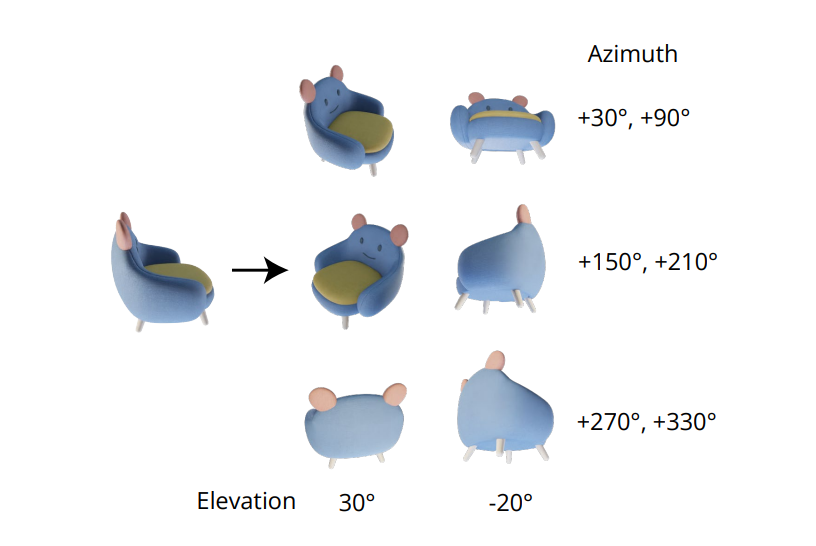

Além disso, foi notado que as orientações do objeto tendem a ser desambiguadas quando o modelo é treinado em poses de câmera, e para evitar essa desambiguação, o framework Zero-1-to-3 treina em poses de câmera com ângulos de elevação e azimute relativo à entrada. Para implementar essa abordagem, é necessário saber o ângulo de elevação da vista da entrada, que é então usado para determinar a pose relativa entre as vistas de entrada novas.
Agendamento de Ruído
O agendamento linear escalonado, o agendamento de ruído original para o Stable Diffusion, se concentra principalmente em detalhes locais, mas, como pode ser visto na seguinte imagem, ele tem muito poucos passos com baixa relação sinal-ruído.


Esses passos de baixa relação sinal-ruído ocorrem no início da etapa de desruído, uma etapa crucial para determinar a estrutura de baixa frequência global. Reduzir o número de passos durante a etapa de desruído, seja durante a interferência ou o treinamento, geralmente resulta em uma maior variação estrutural. Embora essa configuração seja ideal para geração de imagem única, ela limita a capacidade do framework de garantir a consistência global entre diferentes vistas.
Atenção de Referência Escalada para Condições Locais
A entrada de vista única ou as imagens de condicionamento no framework Zero-1-to-3 são concatenadas com as entradas ruidosas na dimensão de recurso para serem ruidosas para o condicionamento de imagem.
Essa concatenação leva a uma correspondência espacial de pixel incorreta entre a imagem de destino e a entrada. Para fornecer entrada de condicionamento local apropriada, o framework Zero123++ usa uma abordagem de atenção de referência escalada, na qual um modelo de desruído UNet é executado em uma imagem de referência extra, seguido do acréscimo de matrizes de valor e chaves de autoatenção da imagem de referência para as camadas de atenção quando a entrada do modelo é desruída, e isso é demonstrado na seguinte figura.

A abordagem de atenção de referência é capaz de guiar o modelo de difusão para gerar imagens que compartilham textura semelhante com a imagem de referência e conteúdo semântico sem qualquer ajuste fino. Com ajuste fino, a abordagem de atenção de referência entrega resultados superiores com o latente escalado.

Condição Global: FlexDiffuse
Na abordagem original do Stable Diffusion, as embeddings de texto são a única fonte de embeddings globais, e a abordagem emprega o framework CLIP como codificador de texto para realizar exames cruzados entre as embeddings de texto e os latentes do modelo. Resultantemente, os desenvolvedores são livres para usar o alinhamento entre os espaços de texto e as imagens CLIP resultantes para usá-lo para condicionamento de imagem global.
O framework Zero123++ propõe usar uma variante treinável do mecanismo de orientação linear para incorporar o condicionamento de imagem global no framework com um ajuste fino mínimo necessário, e os resultados são demonstrados na seguinte imagem. Como pode ser visto, sem a presença de um condicionamento de imagem global, a qualidade do conteúdo gerado pelo framework é satisfatória para regiões visíveis que correspondem à imagem de entrada. No entanto, a qualidade da imagem gerada pelo framework para regiões não vistas sofre uma deterioração significativa, principalmente devido à incapacidade do modelo de inferir a semântica global do objeto.

Arquitetura do Modelo
O framework Zero123++ é treinado com o modelo 2v-do Stable Diffusion como base, usando as diferentes abordagens e técnicas mencionadas no artigo. O framework Zero123++ é pré-treinado no conjunto de dados Objaverse, que é renderizado com iluminação HDRI aleatória. O framework também adota a abordagem de cronograma de treinamento faseado usada no framework de Variações de Imagem do Stable Diffusion, em uma tentativa de minimizar ainda mais a quantidade de ajuste fino necessário e preservar o máximo possível do Stable Diffusion anterior.
O funcionamento ou arquitetura do framework Zero123++ pode ser dividido em etapas ou fases sequenciais. A primeira fase testemunha o framework ajustando finamente as matrizes KV das camadas de atenção cruzada e as camadas de autoatenção do Stable Diffusion com AdamW como otimizador, 1000 passos de aquecimento e o cronograma de taxa de aprendizado cosseno maximizando em 7×10-5. Na segunda fase, o framework emprega uma taxa de aprendizado constante altamente conservadora com 2000 conjuntos de aquecimento e emprega a abordagem Min-SNR para maximizar a eficiência durante o treinamento.
Zero123++: Resultados e Comparação de Desempenho
Desempenho Qualitativo
Para avaliar o desempenho do framework Zero123++ com base na qualidade gerada, ele é comparado com o SyncDreamer e o Zero-1-to-3-XL, dois dos melhores frameworks de estado da arte para geração de conteúdo. Os frameworks são comparados contra quatro imagens de entrada com diferentes escopos. A primeira imagem é um gato de brinquedo elétrico, tirada diretamente do conjunto de dados Objaverse, e possui uma grande incerteza na extremidade traseira do objeto. A segunda é a imagem de um extintor de incêndio, e a terceira é a imagem de um cachorro sentado em um foguete, gerada pelo modelo SDXL. A imagem final é uma ilustração de anime. Os passos de elevação necessários para os frameworks são alcançados usando o método de estimação de elevação do framework One-2-3-4-5, e a remoção de fundo é alcançada usando o framework SAM. Como pode ser visto, o framework Zero123++ gera imagens multi-vista de alta qualidade consistentemente e é capaz de generalizar para ilustrações 2D fora do domínio e imagens geradas por IA igualmente bem.


Análise Quantitativa
Para comparar quantitativamente o framework Zero123++ com os frameworks Zero-1-to-3 e Zero-1-to-3-XL de estado da arte, os desenvolvedores avaliam a pontuação de Similaridade de Patch de Imagem Perceptual Aprendida (LPIPS) desses modelos nos dados de divisão de validação, um subconjunto do conjunto de dados Objaverse. Para avaliar o desempenho do modelo na geração de imagem multi-vista, os desenvolvedores organizam as imagens de referência de verdade e 6 imagens geradas, respectivamente, e calculam a pontuação LPIPS. Os resultados são demonstrados abaixo e, como pode ser claramente visto, o framework Zero123++ alcança o melhor desempenho no conjunto de divisão de validação.

Avaliação de Texto para Multi-Vista
Para avaliar a capacidade do framework Zero123++ de gerar conteúdo de texto para multi-vista, os desenvolvedores primeiro usam o framework SDXL com prompts de texto para gerar uma imagem e, em seguida, empregam o framework Zero123++ na imagem gerada. Os resultados são demonstrados na seguinte imagem e, como pode ser visto, quando comparado com o framework Zero-1-to-3, que não pode garantir a geração de multi-vista consistente, o framework Zero123++ retorna imagens multi-vista consistentes, realistas e altamente detalhadas, implementando a abordagem ou pipeline de texto-para-imagem-para-multi-vista.

Zero123++ Depth ControlNet
Além do framework Zero123++ base, os desenvolvedores também lançaram o Depth ControlNet Zero123++, uma versão controlada por profundidade do framework original, construída usando a arquitetura ControlNet. As imagens lineares normalizadas são renderizadas em relação às imagens RGB subsequentes e um framework ControlNet é treinado para controlar a geometria do framework Zero123++ usando percepção de profundidade.


Conclusão
Neste artigo, falamos sobre o Zero123++, um modelo de IA gerativo de difusão condicionado por imagem com o objetivo de gerar imagens multi-vista consistentes a partir de uma entrada de vista única. Para maximizar a vantagem ganha com modelos gerativos pré-treinados anteriores, o framework Zero123++ implementa várias técnicas de treinamento e condicionamento para minimizar o esforço necessário para ajustar finamente os modelos de difusão de imagem prontos para uso. Também discutimos as diferentes abordagens e melhorias implementadas pelo framework Zero123++ que o ajudam a alcançar resultados comparáveis e, em alguns casos, superiores aos alcançados pelos frameworks de estado da arte atuais.
No entanto, apesar de sua eficiência e capacidade de gerar imagens multi-vista consistentes de alta qualidade, o framework Zero123++ ainda tem espaço para melhoria, com áreas de pesquisa potenciais, como um modelo de refinador de dois estágios que pode resolver a incapacidade do Zero123++ de atender aos requisitos globais de consistência. Além disso, escalas adicionais podem ser implementadas para melhorar ainda mais a capacidade do Zero123++ de gerar imagens de qualidade ainda mais alta.
- Modelo de Refinador de Dois Estágios que pode resolver a incapacidade do Zero123++ de atender aos requisitos globais de consistência.
- Escalas Adicionais para melhorar ainda mais a capacidade do Zero123++ de gerar imagens de qualidade ainda mais alta.












