Inteligência artificial
A Revolução MoE: Como Roteamento Avançado e Especialização Estão Transformando os Modelos de Linguagem Grande
Em apenas alguns anos, os grandes modelos de linguagem (LLMs) expandiram de milhões para centenas de bilhões de parâmetros, demonstrando o progresso notável em nossa capacidade de engenharia e escala de sistemas de IA massivos. Esses sistemas massivos entregaram capacidades impressionantes, como escrever texto fluente, gerar código, raciocinar por meio de problemas complexos e engajar-se em diálogos humanos. No entanto, essa escalada rápida vem com um custo significativo. Treinar e executar tais modelos enormes consome quantidades extraordinárias de poder de processamento, energia e capital. A estratégia de “maior é melhor” que uma vez impulsionou o progresso começou a mostrar seus limites. Em resposta a essas crescentes restrições, uma arquitetura de IA conhecida como Mixture of Experts (MoE) está avançando para oferecer um caminho mais inteligente e eficiente para escalar os grandes modelos de linguagem. Em vez de depender de uma rede massiva e sempre ativa, a MoE divide o modelo em uma coleção de sub-redes especializadas ou “especialistas”, cada uma treinada para lidar com tipos específicos de dados ou tarefas. Por meio de roteamento inteligente, o modelo ativa apenas os especialistas mais relevantes para cada entrada, reduzindo a sobrecarga computacional enquanto mantém ou até melhora o desempenho. Essa capacidade de combinar escalabilidade com eficiência torna a MoE um dos paradigmas emergentes mais definidores em IA. Este artigo explora como o roteamento avançado e a especialização estão impulsionando essa transformação e o que isso significa para o futuro dos sistemas inteligentes.
Entendendo a Arquitetura Central
A ideia por trás da Mixture of Experts (MoE) não é nova. Ela remonta aos métodos de aprendizado de ensemble dos anos 90. O que mudou é a tecnologia que a torna funcionar. Apenas nos últimos anos, os avanços em hardware e algoritmos de roteamento tornaram prático trazer esse conceito para os modernos modelos de linguagem baseados em Transformers.
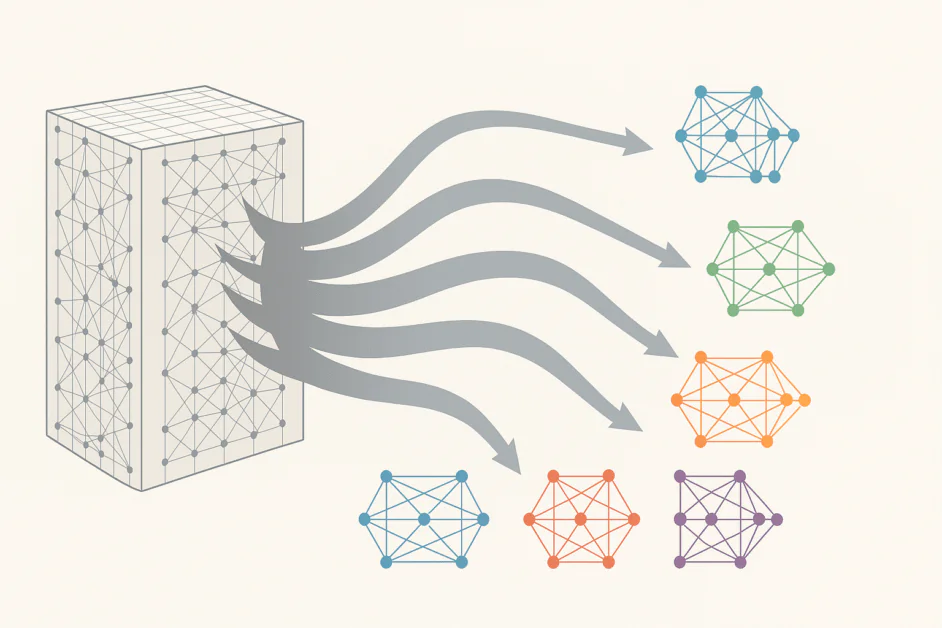
Em sua essência, a MoE redefine uma grande rede neural como uma coleção de sub-redes menores e especializadas, cada uma treinada para lidar com um tipo particular de dados ou tarefa. Em vez de ativar todos os parâmetros para cada entrada, a MoE introduz um mecanismo de roteamento que decide quais especialistas são mais relevantes para um determinado token ou sequência. O resultado é um modelo que usa apenas uma fração de seus parâmetros a qualquer momento, reduzindo dramaticamente a demanda computacional enquanto preserva ou até melhora o desempenho.
Na prática, essa mudança arquitetônica permite que os pesquisadores escalhem modelos para trilhões de parâmetros sem exigir um aumento proporcional nos recursos de processamento. Ela substitui as tradicionais camadas feedforward densas por um sistema mais inteligente e dinâmico. Cada camada MoE contém vários especialistas, geralmente redes feedforward menores, e um roteador ou rede de controle que decide quais especialistas devem processar cada peça de entrada. O roteador age como um gerente de projeto, enviando perguntas relevantes para cada especialista. Com o tempo, o sistema aprende quais especialistas performam melhor para diferentes tipos de problemas, refinando sua estratégia de roteamento à medida que treina.
Essa design oferece uma combinação impressionante de escala e eficiência. Por exemplo, o DeepSeek V3, um dos modelos MoE mais avançados, emprega um impressionante 685 bilhões de parâmetros, mas ativa apenas uma pequena porção deles durante a inferência. Ele entrega o desempenho de um modelo massivo com requisitos computacionais e energéticos significativamente menores.
A Evolução dos Mecanismos de Roteamento
O roteador é o coração da MoE, determinando quais especialistas lidam com cada entrada. Os primeiros modelos usavam estratégias simples, selecionando os dois ou três especialistas principais com base em pesos aprendidos. Os sistemas modernos são muito mais sofisticados.
Os mecanismos de roteamento dinâmicos de hoje ajustam o número de especialistas ativados com base na complexidade da entrada. Uma pergunta simples pode precisar apenas de um especialista, enquanto tarefas de raciocínio difíceis podem ativar vários. O DeepSeek-V2 implementou roteamento limitado por dispositivo para controlar os custos de comunicação em hardware distribuído. O DeepSeek-V3 pioneirou estratégias sem perda auxiliar que permitem uma especialização de especialistas mais rica sem degradação de desempenho.
Os roteadores avançados agora agem como gerentes de recursos inteligentes, ajustando estratégias de seleção com base em características de entrada, profundidade de rede ou feedback de desempenho em tempo real. Alguns pesquisadores estão explorando o aprendizado por reforço para otimizar o desempenho de tarefas de longo prazo. Técnicas como gateamento suave permitem uma seleção de especialistas mais suave, enquanto o despacho probabilístico usa métodos estatísticos para otimizar as atribuições.
Especialização Impulsiona o Desempenho
A promessa central da MoE é que a especialização profunda supera a generalização ampla. Cada especialista se concentra em dominar domínios específicos em vez de ser mediano em tudo. Durante o treinamento, os mecanismos de roteamento consistentemente direcionam certos tipos de entrada para especialistas específicos, criando um poderoso loop de feedback. Alguns especialistas excel em codificação, outros em terminologia médica e outros em escrita criativa.
No entanto, alcançar esse objetivo apresenta desafios. As abordagens tradicionais de balanceamento de carga podem ironicamente dificultar a especialização, forçando o uso uniforme de especialistas. No entanto, o campo está avançando rapidamente. Estudos revelam que modelos MoE de granulação fina exibem especialização clara, com especialistas diferentes dominando em seus respectivos domínios. Estudos confirmam que os mecanismos de roteamento desempenham um papel ativo na formação dessa divisão de trabalho arquitetônica.
Estratégias que empregam especialistas-chave de domínio demonstraram melhorias notáveis de desempenho. Por exemplo, pesquisadores relataram um ganho de precisão de 3,33% no benchmark AIME2024. Quando a especialização funciona, os resultados são notáveis. O DeepSeek V3 supera o GPT-4o em muitos benchmarks de linguagem natural e lidera em todas as tarefas de raciocínio matemático e codificação, um marco impressionante para um modelo de código aberto.
Impacto Prático nas Capacidades do Modelo
A revolução MoE entregou melhorias tangíveis nas capacidades centrais do modelo. Os modelos agora lidam com contextos mais longos de forma mais eficiente; tanto o DeepSeek V3 quanto o GPT-4o podem processar 128K tokens em uma única entrada, com a arquitetura MoE otimizando o desempenho, especialmente em domínios técnicos. Isso é crucial para aplicações como analisar entire codebases ou processar documentos legais longos.
Os ganhos de eficiência de custo são ainda mais dramáticos. Análises sugerem que o DeepSeek-V3 é aproximadamente 29,8 vezes mais barato por token em comparação com o GPT-4o. Essa diferença de preço torna a IA avançada acessível a uma gama mais ampla de usuários e aplicações. Isso acelera significativamente a democratização da IA.
Além disso, a arquitetura permite uma implantação mais sustentável. Treinar um modelo MoE ainda exige recursos substanciais, mas o custo de inferência dramaticamente menor abre caminho para um modelo mais eficiente e economicamente viável para as empresas de IA e seus clientes.
Desafios e o Caminho à Frente
Apesar das vantagens significativas, a MoE não está sem desafios. O treinamento pode ser instável, com especialistas às vezes falhando em se especializar como pretendido. Os primeiros modelos lutaram com “colapso de roteamento”, onde um especialista dominava. Garantir que todos os especialistas recebam dados de treinamento adequados enquanto apenas um subconjunto está ativo exige um equilíbrio cuidadoso.
O maior gargalo é a sobrecarga de comunicação. Em configurações de GPU distribuídas, os custos de comunicação podem consumir até 77% do tempo de processamento. Muitos especialistas são “demasiado colaborativos”, ativando-se frequentemente juntos e forçando transferências de dados repetidas através de aceleradores de hardware. Isso está impulsionando reavaliações fundamentais do design de hardware de IA.
As demandas de memória apresentam outro desafio significativo. Embora a MoE reduza os custos de processamento durante a inferência, todos os especialistas devem ser carregados na memória, estressando dispositivos de borda ou ambientes com recursos limitados. A interpretabilidade permanece outro desafio-chave, pois identificar qual especialista contribuiu para uma saída específica adiciona outra camada de complexidade à arquitetura. Os pesquisadores agora estão explorando métodos para rastrear ativações de especialistas e visualizar caminhos de decisão, visando tornar os sistemas MoE mais transparentes e fáceis de auditar.
O Ponto de Vista Geral
O paradigma Mixture of Experts não é apenas uma nova arquitetura; é uma nova filosofia para construir modelos de IA. Ao combinar roteamento inteligente com especialização em nível de domínio, a MoE alcança o que uma vez parecia contraditório: maior escala com menos computação. Embora desafios de estabilidade, comunicação e interpretabilidade persistam, seu equilíbrio de eficiência, adaptabilidade e precisão aponta para o futuro dos sistemas de IA que não são apenas maiores, mas também mais inteligentes.












