Inteligência artificial
Reestruturando Faces em Vídeos com Aprendizado de Máquina

Uma colaboração de pesquisa entre a China e o Reino Unido desenvolveu um novo método para reestruturar faces em vídeo. A técnica permite um alargamento e estreitamento convincentes da estrutura facial, com alta consistência e ausência de artefatos.
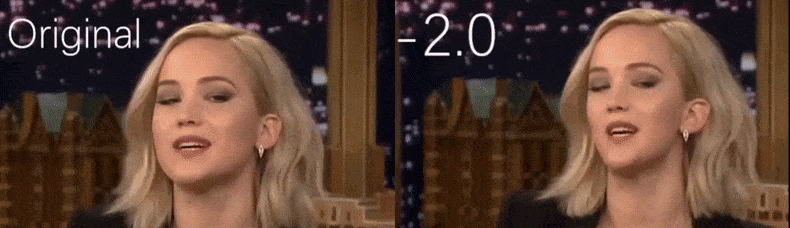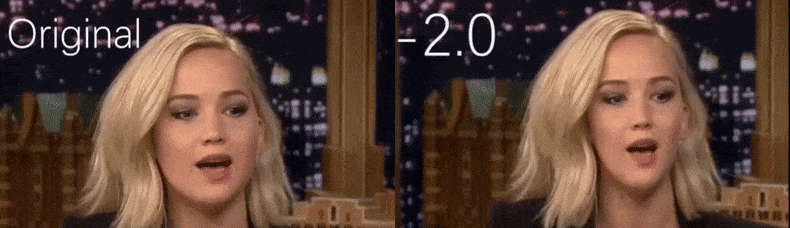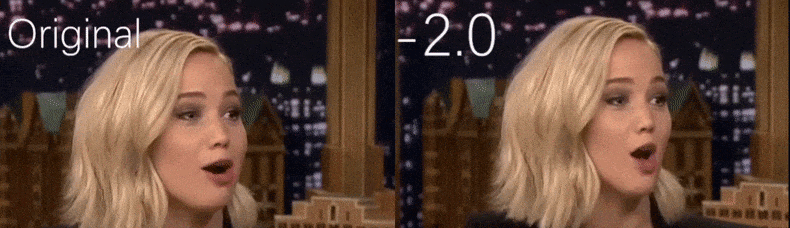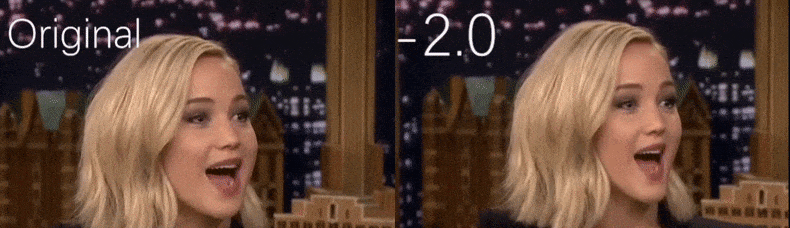
De um vídeo do YouTube usado como material de origem pelos pesquisadores, a atriz Jennifer Lawrence aparece como uma personalidade mais gaunt (à direita). Veja o vídeo acompanhante incorporado ao final do artigo para muitos mais exemplos em melhor resolução. Fonte: https://www.youtube.com/watch?v=tA2BxvrKvjE
Esse tipo de transformação geralmente é possível apenas por meio de métodos tradicionais de CGI que precisariam recriar entirely a face por meio de procedimentos detalhados e caros de captura de movimento, rigging e texturização.
Em vez disso, o que há de CGI na técnica é integrado a uma pipeline neural como informações faciais 3D paramétricas que são subsequentemente usadas como base para um fluxo de trabalho de aprendizado de máquina.

Faces paramétricas tradicionais estão sendo cada vez mais usadas como diretrizes para processos transformadores que usam IA em vez de CGI. Fonte: https://arxiv.org/pdf/2205.02538.pdf
Os autores afirmam:
‘Nosso objetivo é gerar resultados de reestruturação de vídeo de retrato de alta qualidade, editando a forma geral das faces de retrato de acordo com a deformação facial natural no mundo real. Isso pode ser usado para aplicações como geração de faces para embelezamento e exagero de faces para efeitos visuais.’
Embora a distorção e torção de faces 2D tenham sido disponíveis para os consumidores desde o advento do Photoshop (e tenham levado a subculturas estranhas e frequentemente inaceitáveis sub-culturas em torno da distorção facial e dismorfia corporal), é um truque difícil de realizar em vídeo sem usar CGI.

As dimensões faciais de Mark Zuckerberg expandidas e estreitadas pela nova técnica sino-britânica.
A reestruturação corporal é atualmente um campo de intenso interesse no setor de visão computacional, principalmente devido ao seu potencial no comércio eletrônico de moda, embora fazer com que alguém pareça mais alto ou diverso esquelético seja atualmente um desafio notável.
Da mesma forma, mudar a forma de uma cabeça em footage de vídeo de maneira consistente e convincente tem sido o tema de trabalhos anteriores dos pesquisadores do novo artigo, embora essa implementação tenha sofrido de artefatos e outras limitações. O novo sistema estende a capacidade dessa pesquisa anterior de saída estática para saída de vídeo.
O novo sistema foi treinado em um desktop PC com um AMD Ryzen 9 3950X com 32GB de memória e usa um algoritmo de fluxo óptico do OpenCV para mapas de movimento, suavizados pelo framework StructureFlow; a Rede de Alinhamento Facial (FAN) componente para estimativa de marcos, que também é usada nos pacotes de deepfakes populares; e o Ceres Solver para resolver desafios de otimização.

Um exemplo extremo de alargamento facial com o novo sistema.
O artigo é intitulado Reestruturação Paramétrica de Retratos em Vídeos e vem de três pesquisadores da Universidade de Zhejiang e um da Universidade de Bath.
Sobre o Rosto
Sob o novo sistema, o vídeo é extraído em uma sequência de imagens e uma pose rígida é primeiro estimada para cada face. Em seguida, um número representativo de quadros subsequentes são estimados em conjunto para construir parâmetros de identidade consistentes ao longo de toda a sequência de imagens (ou seja, os quadros do vídeo).

Arquitetura do fluxo do sistema de torção facial.
Depois disso, a expressão é avaliada, produzindo um parâmetro de reestruturação que é implementado por regressão linear. Em seguida, uma abordagem de função de distância assinada (SDF) constrói um mapeamento denso 2D das linhas faciais antes e após a reestruturação.
Finalmente, uma otimização de torção consciente de conteúdo é realizada no vídeo de saída.
Rostos Paramétricos
O processo utiliza um Modelo Facial 3D Moldável (3DMM), um adjunto cada vez mais popular aos sistemas de síntese facial baseados em neurais e GAN, bem como sendo aplicável para sistemas de detecção de deepfakes.

Não do novo artigo, mas um exemplo de um Modelo Facial 3D Moldável (3DMM) – um protótipo facial paramétrico usado no novo projeto. Topo esquerdo, aplicação de marcos em um rosto 3DMM. Topo direito, os vértices da malha 3D de um isomap. Fundo esquerdo mostra ajuste de marcos; fundo-meio, um isomap da textura facial extraída; e fundo-direito, um ajuste e forma resultantes. Fonte: http://www.ee.surrey.ac.uk/CVSSP/Publications/papers/Huber-VISAPP-2016.pdf
O fluxo de trabalho do novo sistema deve considerar casos de oclusão, como uma instância em que o sujeito olha para longe. Isso é um dos maiores desafios nos softwares de deepfake, desde que os marcos FAN têm pouca capacidade de levar em conta esses casos e tendem a se deteriorar em qualidade à medida que a face se desvia ou é ocultada.
O novo sistema consegue evitar essa armadilha definindo uma energia de contorno que é capaz de corresponder à fronteira entre o rosto 3D (3DMM) e o rosto 2D (definido por marcos FAN).
Otimização
Uma implantação útil para tal sistema seria implementar deformação em tempo real, por exemplo, em filtros de vídeo-conferência. O framework atual não permite isso e os recursos computacionais necessários fariam a deformação “ao vivo” um desafio notável.
De acordo com o artigo, e supondo um alvo de vídeo de 24fps, as operações por quadro na pipeline representam uma latência de 16,344 segundos para cada segundo de footage, com acréscimos adicionais para estimativa de identidade e deformação facial 3D (321ms e 160ms, respectivamente).
Portanto, a otimização é fundamental para fazer progressos em direção à redução da latência. Como a otimização conjunta em todos os quadros adicionaria uma sobrecarga severa ao processo e a otimização do tipo init (presumindo a identidade consistente do falante a partir do primeiro quadro) poderia levar a anomalias, os autores adotaram um esquema esparsamente calculado para calcular os coeficientes dos quadros amostrados em intervalos práticos.
A otimização conjunta é então realizada nesse subconjunto de quadros, levando a um processo de reconstrução mais magro.
Torção Facial
A técnica de torção usada no projeto é uma adaptação do trabalho dos autores de 2020 Retratos Profundos e Torcidos (DSP).

Retratos Profundos e Torcidos, uma submissão de 2020 para a ACM Multimedia. O artigo é liderado por pesquisadores do ZJU-Tencent Game and Intelligent Graphics Innovation Technology Joint Lab. Fonte: http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
Os autores observam ‘Nós estendemos esse método de reestruturar uma imagem monocular para reestruturar a sequência de imagens inteira.’
Testes
O artigo observa que não havia material comparável anterior para avaliar o novo método. Portanto, os autores compararam quadros da saída de vídeo torcida com a saída estática do DSP.

Testando o novo sistema contra imagens estáticas do Retratos Profundos e Torcidos.
Os autores afirmam:
‘Os resultados mostram que nossa abordagem pode produzir robustamente vídeos de retrato reestruturados coerentes, enquanto o método baseado em imagem pode facilmente levar a artefatos de flickering notáveis.’
Confira o vídeo acompanhante abaixo, para mais exemplos:
Publicado pela primeira vez em 9 de maio de 2022. Alterado às 18h EET, substituído ‘campo’ por ‘função’ para SDF.












