A OpenAI lançou seu mais recente e avançado modelo de linguagem – o GPT-4o, também conhecido como o modelo “Omni“. Este sistema de IA revolucionário representa um grande salto para frente, com capacidades que desfiam a linha entre inteligência humana e artificial.
No coração do GPT-4o está sua natureza multimodal nativa, que permite processar e gerar conteúdo de forma transparente em texto, áudio, imagens e vídeo. Essa integração de múltiplas modalidades em um único modelo é inédita e promete redefinir como interagimos com assistentes de IA.
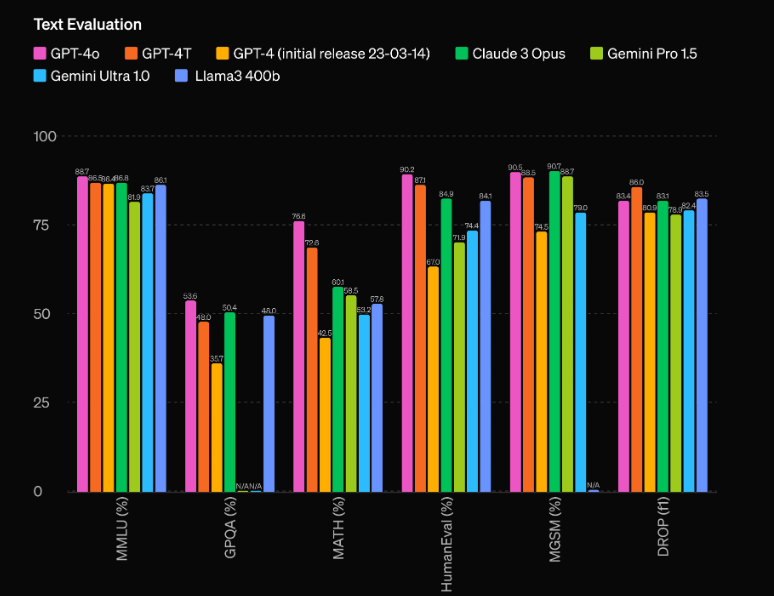
Mas o GPT-4o é muito mais do que apenas um sistema multimodal. Ele apresenta uma melhoria impressionante no desempenho em relação ao seu antecessor, o GPT-4, e deixa modelos concorrentes como o Gemini 1.5 Pro, Claude 3 e Llama 3-70B para trás. Vamos explorar mais a fundo o que torna este modelo de IA verdadeiramente inovador.
Desempenho e Eficiência Sem Precedentes
Um dos aspectos mais impressionantes do GPT-4o é sua capacidade de desempenho sem precedentes. De acordo com as avaliações da OpenAI, o modelo tem uma vantagem notável de 60 pontos Elo sobre o anterior líder, o GPT-4 Turbo. Essa vantagem significativa coloca o GPT-4o em uma liga própria, superando até mesmo os modelos de IA mais avançados atualmente disponíveis.
Mas o desempenho bruto não é a única área onde o GPT-4o brilha. O modelo também apresenta uma eficiência impressionante, operando com o dobro da velocidade do GPT-4 Turbo, enquanto custa apenas metade para executar. Essa combinação de desempenho superior e eficiência em termos de custo torna o GPT-4o uma proposta extremamente atraente para desenvolvedores e empresas que buscam integrar capacidades de IA de ponta em seus aplicativos.
Capacidades Multimodais: Mesclando Texto, Áudio e Visão
Talvez o aspecto mais inovador do GPT-4o seja sua natureza multimodal nativa, que permite processar e gerar conteúdo de forma transparente em múltiplas modalidades, incluindo texto, áudio e visão. Essa integração de múltiplas modalidades em um único modelo é inédita e promete revolucionar como interagimos com assistentes de IA.
Com o GPT-4o, os usuários podem se engajar em conversas naturais e em tempo real usando voz, com o modelo reconhecendo e respondendo instantaneamente a entradas de áudio. Mas as capacidades não param por aí – o GPT-4o também pode interpretar e gerar conteúdo visual, abrindo um mundo de possibilidades para aplicações que variam desde análise e geração de imagens até compreensão e criação de vídeo.
Uma das demonstrações mais impressionantes das capacidades multimodais do GPT-4o é sua capacidade de analisar uma cena ou imagem em tempo real, descrevendo e interpretando com precisão os elementos visuais que percebe. Essa funcionalidade tem implicações profundas para aplicações como tecnologias assistivas para pessoas com deficiência visual, bem como em campos como segurança, vigilância e automação.
Mas as capacidades multimodais do GPT-4o vão além de apenas entender e gerar conteúdo em diferentes modalidades. O modelo também pode mesclar essas modalidades de forma transparente, criando experiências verdadeiramente imersivas e envolventes. Por exemplo, durante a demonstração ao vivo da OpenAI, o GPT-4o foi capaz de gerar uma música com base em condições de entrada, mesclando sua compreensão de linguagem, teoria musical e geração de áudio em uma saída coesa e impressionante.
Usando o GPT0 com Python
[código language=”Python”]
import openai
# Substitua com sua chave de API real
OPENAI_API_KEY = “sua_chave_de_api_openai_aqui”
# Função para extrair o conteúdo da resposta
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get(“choices”) and len(response_dict[“choices”]) > 0:
content = response_dict[“choices”][0][“message”][“content”].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, ”)
return content
raise ValueError(f”Não foi possível resolver a resposta: {response_dict}”)
# Função assíncrona para enviar uma solicitação à API de bate-papo da OpenAI
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
# Exemplo de uso
async def main():
prompt = “Olá!”
model_name = “gpt-4o-2024-05-13”
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == “__main__”:
import asyncio
asyncio.run(main())
[/código]
Eu tenho:
Importado o módulo openai diretamente em vez de usar uma classe personalizada.
Renomeado a função openai_chat_resolve para get_response_content e feito algumas alterações menores na sua implementação.
Substituído a classe AsyncOpenAI pela função openai.ChatCompletion.acreate, que é o método assíncrono oficial fornecido pela biblioteca Python da OpenAI.
Adicionei um exemplo de função main que demonstra como usar a função send_openai_chat_request.
Observe que você precisa substituir “sua_chave_de_api_openai_aqui” com sua chave de API real da OpenAI para que o código funcione corretamente.
Inteligência Emocional e Interação Natural
Outro aspecto inovador do GPT-4o é sua capacidade de interpretar e gerar respostas emocionais, uma capacidade que há muito tempo tem escapado aos sistemas de IA. Durante a demonstração ao vivo, os engenheiros da OpenAI mostraram como o GPT-4o poderia detectar e responder ao estado emocional do usuário, ajustando seu tom e respostas de acordo.
Em um exemplo particularmente impressionante, um engenheiro fingiu hiperventilar, e o GPT-4o imediatamente reconheceu os sinais de distresse em sua voz e padrões de respiração. O modelo então guiou o engenheiro por uma série de exercícios de respiração, modulando seu tom para um modo calmo e reconfortante até que o distresse simulado tivesse passado.
Essa capacidade de interpretar e responder a pistas emocionais é um passo significativo em direção a interações verdadeiramente naturais e humanas com sistemas de IA. Ao entender o contexto emocional de uma conversa, o GPT-4o pode adaptar suas respostas de uma maneira que se sinta mais natural e empática, levando a uma experiência de usuário mais envolvente e satisfatória.
Acessibilidade
A OpenAI decidiu oferecer as capacidades do GPT-4o a todos os usuários, gratuitamente. Esse modelo de preços estabelece um novo padrão, onde concorrentes normalmente cobram taxas de assinatura substanciais para acessar seus modelos.
Embora a OpenAI ainda ofereça um plano pago “ChatGPT Plus” com benefícios como limites de uso mais altos e acesso prioritário, as capacidades principais do GPT-4o estarão disponíveis a todos sem custo.
Aplicações e Desenvolvimentos Futuros no Mundo Real
As implicações das capacidades do GPT-4o são vastas e de longo alcance, com aplicações potenciais que abrangem numerousas indústrias e domínios. No reino do atendimento e suporte ao cliente, por exemplo, o GPT-4o poderia revolucionar como as empresas interagem com seus clientes, fornecendo assistência natural e em tempo real em múltiplas modalidades, incluindo voz, texto e auxílios visuais.
No campo da educação, o GPT-4o poderia ser utilizado para criar experiências de aprendizado imersivas e personalizadas, com o modelo adaptando seu estilo de ensino e entrega de conteúdo para atender às necessidades e preferências de cada aluno individual. Imagine um tutor virtual que não apenas explica conceitos complexos por meio da linguagem natural, mas também gera auxílios visuais e simulações interativas na hora.
A indústria do entretenimento é outra área onde as capacidades multimodais do GPT-4o podem brilhar. Desde a geração de narrativas dinâmicas e envolventes para jogos de vídeo e filmes até a composição de música e trilhas sonoras originais, as possibilidades são infinitas.
Olhando para o futuro, a OpenAI tem planos ambiciosos para continuar expandindo as capacidades de seus modelos, com foco em melhorar as habilidades de raciocínio e integrar dados personalizados. Uma perspectiva fascinante é a integração do GPT-4o com grandes modelos de linguagem treinados em domínios específicos, como bases de conhecimento médicas ou jurídicas. Isso poderia abrir caminho para assistentes de IA altamente especializados capazes de fornecer conselhos e suporte de nível de especialista em seus respectivos campos.
Outra direção emocionante para desenvolvimentos futuros é a integração do GPT-4o com outros modelos e sistemas de IA, permitindo colaboração e compartilhamento de conhecimento sem esforço entre diferentes domínios e modalidades. Imagine um cenário onde o GPT-4o pudesse aproveitar as capacidades de modelos de visão computacional de ponta para analisar e interpretar dados visuais complexos, ou colaborar com sistemas robóticos para fornecer orientação e suporte em tempo real em tarefas físicas.
Considerações Éticas e IA Responsável
Como qualquer tecnologia poderosa, o desenvolvimento e a implantação do GPT-4o e de modelos de IA semelhantes levantam considerações éticas importantes. A OpenAI tem sido vocal sobre seu compromisso com o desenvolvimento de IA responsável, implementando várias salvaguardas e medidas para mitigar riscos e uso indevido potenciais.
Uma preocupação-chave é o potencial para que modelos de IA como o GPT-4o perpetuem ou amplifiquem viés e estereótipos prejudiciais presentes nos dados de treinamento. Para abordar isso, a OpenAI implementou técnicas rigorosas de debiasing e filtros para minimizar a propagação desses viés nos resultados do modelo.
Outra questão crítica é o potencial uso indevido das capacidades do GPT-4o para fins maliciosos, como a geração de deepfakes, disseminação de desinformação ou engajamento em outras formas de manipulação digital. A OpenAI implementou sistemas robustos de filtragem de conteúdo e moderação para detectar e prevenir o uso indevido de seus modelos para atividades prejudiciais ou ilegais.
Além disso, a empresa enfatizou a importância da transparência e responsabilidade no desenvolvimento de IA, publicando regularmente artigos de pesquisa e detalhes técnicos sobre seus modelos e metodologias. Esse compromisso com a abertura e a escrutínio da comunidade científica é crucial para promover a confiança e garantir o desenvolvimento e a implantação responsáveis de tecnologias de IA como o GPT-4o.
Conclusão
O GPT-4o da OpenAI representa uma verdadeira mudança de paradigma no campo da inteligência artificial, inaugurando uma nova era de interação humano-máquina multimodal, emocionalmente inteligente e natural. Com seu desempenho sem precedentes, integração transparente de texto, áudio e visão, e modelo de preços disruptivo, o GPT-4o promete democratizar o acesso a capacidades de IA de ponta e transformar fundamentalmente como interagimos com a tecnologia.
Embora as implicações e aplicações potenciais deste modelo inovador sejam vastas e emocionais, é crucial que seu desenvolvimento e implantação sejam guiados por um firme compromisso com princípios éticos e práticas de IA responsáveis.
Eu passei os últimos cinco anos me imergindo no fascinante mundo de Aprendizado de Máquina e Aprendizado Profundo. Minha paixão e expertise me levaram a contribuir para mais de 50 projetos de engenharia de software diversificados, com um foco particular em IA/ML. Minha curiosidade contínua também me levou em direção ao Processamento de Linguagem Natural, um campo que estou ansioso para explorar mais.