Inteligência artificial
O DALL-E 2 está apenas “colando coisas juntas” sem entender as relações entre elas?

Um novo artigo de pesquisa da Universidade de Harvard sugere que o quadro de texto-para-imagem da OpenAI, DALL-E 2, tem dificuldade notável em reproduzir relações entre os elementos que compõem as fotos sintetizadas, apesar da sofisticação deslumbrante de grande parte de sua saída.
Os pesquisadores realizaram um estudo com 169 participantes crowdsourced, que foram apresentados a imagens do DALL-E 2 com base nos princípios humanos mais básicos de semântica de relacionamento, juntamente com os textos-prompt que as criaram. Quando perguntados se os prompts e as imagens estavam relacionados, menos de 22% das imagens foram percebidas como pertinentes aos seus prompts associados, em termos das relações simples que o DALL-E 2 foi solicitado a visualizar.

Uma captura de tela dos testes realizados para o novo artigo. Os participantes foram solicitados a selecionar todas as imagens que correspondiam ao prompt. Fonte: https://arxiv.org/pdf/2208.00005.pdf
Os resultados também sugerem que a capacidade aparente do DALL-E de conjunção de elementos díspares pode diminuir à medida que esses elementos se tornam menos prováveis de ter ocorrido nos dados de treinamento do mundo real que alimentam o sistema.
Por exemplo, imagens para o prompt ‘criança tocando uma tigela’ obtiveram uma taxa de concordância de 87% (ou seja, os participantes clicaram na maioria das imagens como sendo relevantes para o prompt), enquanto imagens igualmente fotorealistas de ‘um macaco tocando um iguana’ alcançaram apenas 11% de concordância:


DALL-E luta para retratar o evento improvável de um ‘macaco tocando um iguana’, provavelmente porque é incomum, mais provável não existente, no conjunto de treinamento.
No segundo exemplo, o DALL-E 2 frequentemente obtém a escala e até mesmo a espécie errada, presumivelmente devido à falta de imagens do mundo real que retratem esse evento. Em contraste, é razoável esperar um grande número de fotos de treinamento relacionadas a crianças e comida, e que esse subdomínio/classe esteja bem desenvolvido.
A dificuldade do DALL-E em justapor elementos de imagem fortemente contrastantes sugere que o público está atualmente tão deslumbrado pelas capacidades fotorealistas e amplamente interpretativas do sistema que não desenvolveu um olho crítico para os casos em que o sistema efetivamente apenas ‘colou’ um elemento drasticamente sobre o outro, como nesses exemplos do site oficial do DALL-E 2:

Síntese de corte e cola, dos exemplos oficiais para DALL-E 2. Fonte: https://openai.com/dall-e-2/
O novo artigo afirma*:
‘A compreensão relacional é um componente fundamental da inteligência humana, que se manifesta cedo no desenvolvimento, e é calculada rapidamente e automaticamente na percepção.
‘A dificuldade do DALL-E 2 com relações espaciais básicas (como em, on, under) sugere que, qualquer que seja o que ele tenha aprendido, ele ainda não aprendeu os tipos de representações que permitem que os humanos estruturem o mundo de forma flexível e robusta.
‘Uma interpretação direta dessa dificuldade é que sistemas como o DALL-E 2 ainda não têm composicionalidade relacional.’
Os autores sugerem que sistemas de geração de imagem orientada por texto, como a série DALL-E, poderiam se beneficiar de aproveitar algoritmos comuns à robótica, que modelam identidades e relações simultaneamente, devido à necessidade do agente interagir efetivamente com o ambiente, em vez de apenas fabricar uma mistura de elementos diversos.
Uma abordagem dessas, intitulada CLIPort, usa o mesmo mecanismo CLIP que serve como um elemento de avaliação de qualidade no DALL-E 2:
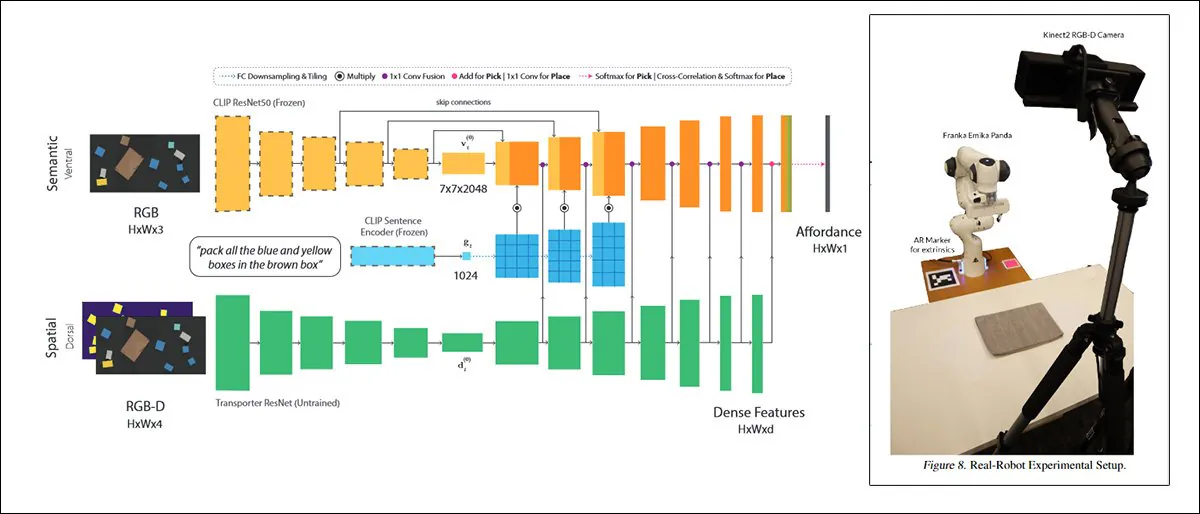
CLIPort, uma colaboração de 2021 entre a Universidade de Washington e a NVIDIA, usa CLIP em um contexto tão prático que os sistemas treinados nele devem necessariamente desenvolver uma compreensão de relações físicas, um motivador que está ausente no DALL-E 2 e em outros quadros de síntese de imagem ‘fantásticos’. Fonte: https://arxiv.org/pdf/2109.12098.pdf
Os autores sugerem ainda que ‘outra melhoria plausível’ poderia ser para a arquitetura dos sistemas de síntese de imagem, como o DALL-E, incorporar efeitos multiplicativos em uma única camada de computação, permitindo o cálculo de relações de uma maneira inspirada nas capacidades de processamento de informações de sistemas biológicos sistemas.
O novo artigo é intitulado Testando a Compreensão Relacional na Geração de Imagem Orientada por Texto, e vem de Colin Conwell e Tomer D. Ullman, do Departamento de Psicologia de Harvard.
Além da Crítica Inicial
Comentando sobre o ‘truque’ por trás do realismo e integridade da saída do DALL-E 2, os autores notam trabalhos anteriores que encontraram limitações nos sistemas de imagem geradora de estilo DALL-E.
Em junho deste ano, a UoC Berkeley notou a dificuldade do DALL-E em lidar com reflexos e sombras; no mesmo mês, um estudo da Coreia investigou a ‘singularidade’ e originalidade da saída do estilo DALL-E 2 com um olho crítico; uma análise preliminar de imagens do DALL-E 2, logo após o lançamento, da NYU e da Universidade do Texas, encontrou vários problemas com a composicionalidade e outros fatores essenciais nas imagens do DALL-E 2; e no mês passado, um trabalho conjunto entre a Universidade de Illinois e o MIT ofereceu sugestões para melhorias arquiteturais para esses sistemas em termos de composicionalidade.
Os pesquisadores observam ainda que luminares do DALL-E, como Aditya Ramesh, concederam os problemas do quadro com a ligação, tamanho relativo, texto e outros desafios.
Os desenvolvedores por trás do sistema de síntese de imagem rival da Google, Imagen, também propuseram DrawBench, um sistema de comparação de imagem que mede a precisão da imagem em diferentes frameworks com métricas diversas.
Em vez disso, os autores do novo artigo sugerem que um resultado melhor poderia ser obtido enfrentando a estimativa humana – em vez de métricas algorítmicas internas – contra as imagens resultantes, para estabelecer onde as fraquezas estão e o que poderia ser feito para mitigá-las.
O Estudo
Para isso, o novo projeto baseia sua abordagem em princípios psicológicos e busca se afastar do atual surto de interesse em engenharia de prompts (que é, em efeito, uma concessão às limitações do DALL-E 2, ou qualquer sistema comparável), para investigar e potencialmente abordar as limitações que tornam essas ‘soluções’ necessárias.












