
Inteligência artificial
O LipSync3D do Google oferece sincronização aprimorada do movimento da boca 'Deepfaked'

A colaboração entre os pesquisadores de IA do Google e o Instituto Indiano de Tecnologia Kharagpur oferece uma nova estrutura para sintetizar cabeças falantes de conteúdo de áudio. O projeto visa produzir formas otimizadas e com recursos razoáveis para criar conteúdo de vídeo 'talking head' a partir de áudio, para fins de sincronização de movimentos labiais com áudio dublado ou traduzido por máquina e para uso em avatares, em aplicativos interativos e em outros ambientes em tempo real.

Fonte: https://www.youtube.com/watch?v=L1StbX9OznY
Os modelos de aprendizado de máquina treinados no processo – chamados LipSync3D – requerem apenas um único vídeo da identidade do rosto alvo como dados de entrada. O pipeline de preparação de dados separa a extração da geometria facial da avaliação da iluminação e de outras facetas de um vídeo de entrada, permitindo um treinamento mais econômico e focado.
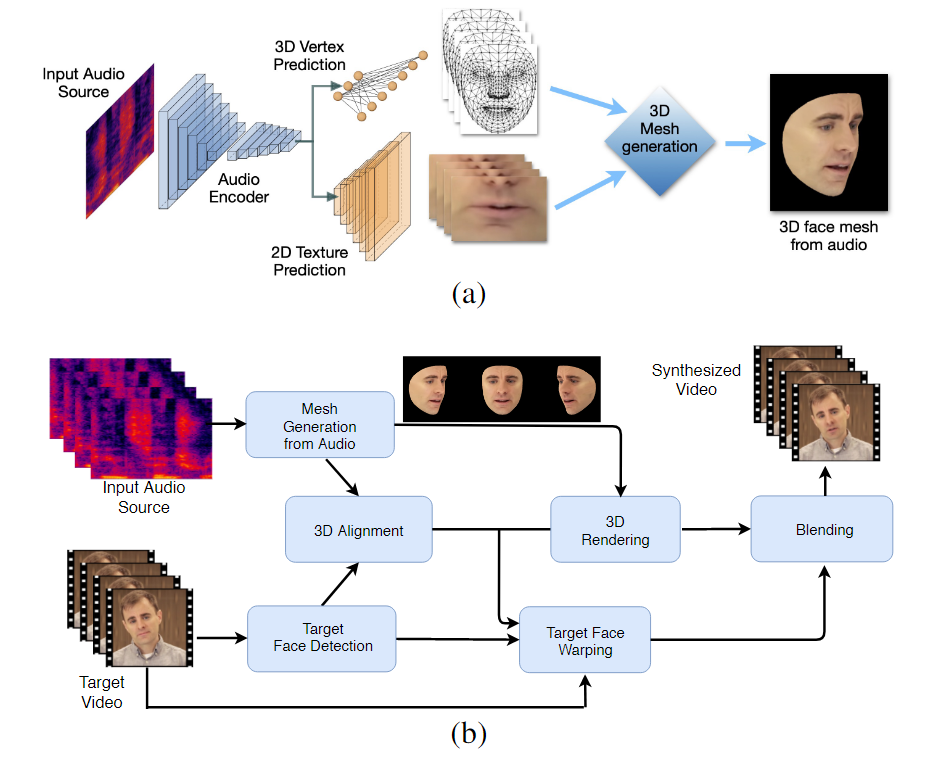
O fluxo de trabalho de dois estágios do LipSync3D. Acima, a geração de uma face 3D texturizada dinamicamente a partir do áudio 'alvo'; abaixo, a inserção da malha gerada em um vídeo de destino.
Na verdade, a contribuição mais notável do LipSync3D para o corpo de esforços de pesquisa nessa área pode ser seu algoritmo de normalização de iluminação, que separa a iluminação de treinamento e de inferência.

O desacoplamento dos dados de iluminação da geometria geral ajuda o LipSync3D a produzir uma saída de movimento labial mais realista sob condições desafiadoras. Outras abordagens dos últimos anos limitaram-se a condições de iluminação 'fixas' que não revelariam sua capacidade mais limitada a esse respeito.
Durante o pré-processamento dos quadros de dados de entrada, o sistema deve identificar e remover pontos especulares, pois são específicos das condições de iluminação em que o vídeo foi feito e, caso contrário, interferirão no processo de reiluminação.

O LipSync3D, como o próprio nome sugere, não realiza uma mera análise de pixels nos rostos que avalia, mas usa ativamente pontos de referência faciais identificados para gerar malhas móveis no estilo CGI, juntamente com as texturas 'desdobradas' que são envolvidas em um CGI tradicional pipeline.

Normalização de pose em LipSync3D. À esquerda estão os quadros de entrada e os recursos detectados; no meio, os vértices normalizados da avaliação da malha gerada; e à direita, o atlas de textura correspondente, que fornece a base para a previsão de textura. Fonte: https://arxiv.org/pdf/2106.04185.pdf
Além do novo método de reiluminação, os pesquisadores afirmam que o LipSync3D oferece três principais inovações em trabalhos anteriores: a separação de geometria, iluminação, pose e textura em fluxos de dados discretos em um espaço normalizado; um modelo de previsão de textura auto-regressiva facilmente treinável que produz síntese de vídeo temporalmente consistente; e maior realismo, conforme avaliado por classificações humanas e métricas objetivas.

Dividir as várias facetas das imagens faciais do vídeo permite maior controle na síntese de vídeo.
O LipSync3D pode derivar o movimento apropriado da geometria labial diretamente do áudio, analisando fonemas e outras facetas da fala e traduzindo-os em poses musculares correspondentes conhecidas ao redor da área da boca.

Esse processo usa um pipeline de previsão conjunta, onde a geometria e a textura inferidas possuem codificadores dedicados em uma configuração de autoencoder, mas compartilham um codificador de áudio com a fala que se pretende impor ao modelo:

A síntese de movimento lábil do LipSync3D também se destina a alimentar avatares CGI estilizados, que na verdade são apenas o mesmo tipo de malha e informações de textura que as imagens do mundo real:
Um avatar 3D estilizado tem seus movimentos labiais alimentados em tempo real por um vídeo de alto-falante de origem. Nesse cenário, os melhores resultados seriam obtidos pelo pré-treinamento personalizado.
Os pesquisadores também antecipam o uso de avatares com um toque um pouco mais realista:
![]()
Os tempos de treinamento de amostra para os vídeos variam de 3 a 5 horas para um vídeo de 2 a 5 minutos, em um pipeline que usa TensorFlow, Python e C++ em uma GeForce GTX 1080. As sessões de treinamento usaram um tamanho de lote de 128 quadros em 500-1000 épocas, com cada época representando uma avaliação completa do vídeo.

Rumo à ressincronização dinâmica do movimento labial
O campo da ressincronização de lábios para acomodar uma nova faixa de áudio tem recebido muita atenção na pesquisa de visão computacional nos últimos anos (veja abaixo), até porque é um subproduto de controvérsias tecnologia deepfake.
Em 2017, a Universidade de Washington pesquisa apresentada capaz de aprender a sincronização labial do áudio, usando-o para alterar os movimentos labiais do então presidente Obama. Em 2018; o Instituto Max Planck de Informática liderou outra iniciativa de pesquisa para habilitar a transferência de vídeo identidade>identidade, com sincronização labial a subproduto do processo; e em maio de 2021, a startup de IA FlawlessAI revelou sua tecnologia proprietária de sincronização labial TrueSync, amplamente recebido na imprensa como um facilitador de tecnologias de dublagem aprimoradas para grandes lançamentos de filmes em vários idiomas.
E, é claro, o desenvolvimento contínuo de repositórios de código aberto deepfake fornece outro ramo da pesquisa ativa de usuários nessa esfera de síntese de imagens faciais.















