
Inteligência artificial
Fidelidade vs. Realismo em vídeos deepfake

Nem todos os praticantes de deepfake compartilham o mesmo objetivo: o ímpeto do setor de pesquisa de síntese de imagem – apoiado por proponentes influentes como adobe, NVIDIA e Facebook – é avançar no estado da arte para que as técnicas de aprendizado de máquina possam eventualmente recriar ou sintetizar a atividade humana em alta resolução e sob as condições mais desafiadoras (fidelidade).
Em contraste, o objetivo daqueles que desejam usar tecnologias deepfake para disseminar desinformação é criar simulações plausíveis de pessoas reais por meio de muitos outros métodos além da mera veracidade de rostos deepfake. Nesse cenário, fatores adicionais como contexto e plausibilidade são quase iguais ao potencial de um vídeo para simular rostos. (realismo).
Essa abordagem de "prestidigitação" se estende à degradação da qualidade final da imagem de um vídeo deepfake, de modo que o vídeo inteiro (e não apenas a parte enganosa representada por um rosto deepfake) tenha uma "aparência" coesa e precisa em relação à qualidade esperada para o meio.
"Coeso" não significa necessariamente "bom" – basta que a qualidade seja consistente entre o conteúdo original e o inserido, adulterado, e atenda às expectativas. Em termos de saída de streaming VOIP em plataformas como Skype e Zoom, o padrão pode ser notavelmente baixo, com falhas, vídeos instáveis e uma série de potenciais artefatos de compressão, além de algoritmos de "suavização" projetados para reduzir seus efeitos – que, por si só, constituem uma gama adicional de efeitos "inautênticos" que aceitamos como corolários das restrições e excentricidades do streaming ao vivo.
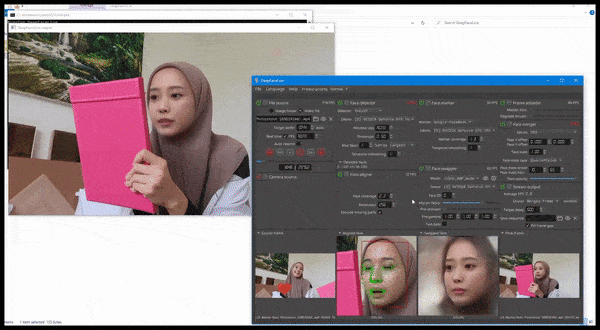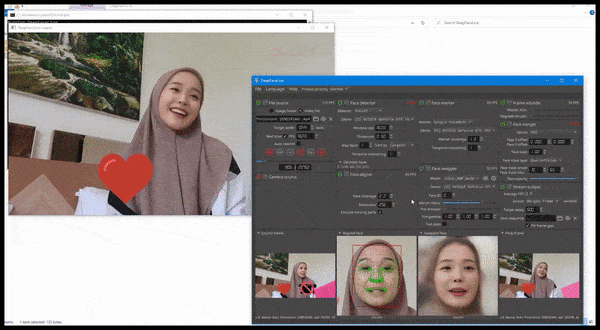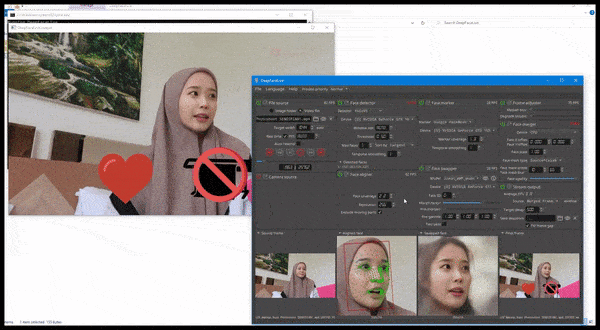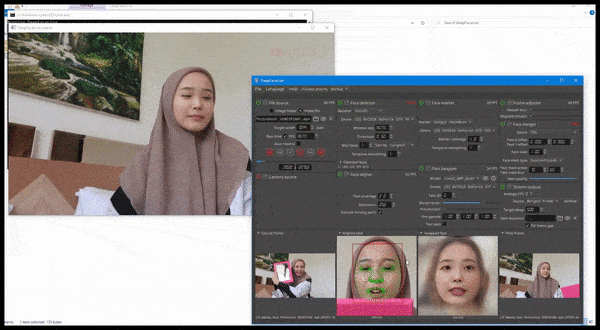
DeepFaceLive em ação: esta versão de streaming do software deepfake premier DeepFaceLab pode fornecer realismo contextual apresentando falsificações no contexto de qualidade de vídeo limitada, completa com problemas de reprodução e outros artefatos de conexão recorrentes. Fonte: https://www.youtube.com/watch?v=IL517EgYH8U
Degradação incorporada
De fato, os dois pacotes de deepfake mais populares (ambos derivados do controverso código-fonte de 2017) contêm componentes destinados a integrar o rosto deepfake ao contexto de vídeos "históricos" ou de qualidade inferior, degradando o rosto gerado. DeepFace Lab, bicúbico_degrade_power parâmetro realiza isso e, em Troca de rosto, a configuração de 'grão' na configuração do Ffmpeg também ajuda na integração da face falsa ao preservar o grão durante a codificação*.

A configuração de "granulação" no FaceSwap auxilia na integração autêntica em conteúdo de vídeo não HQ e em conteúdo antigo que pode apresentar efeitos de granulação de filme que são relativamente raros hoje em dia.
Freqüentemente, em vez de um vídeo deepfake completo e integrado, os deepfakers produzem uma série isolada de arquivos PNG com canais alfa, cada imagem mostrando apenas a saída da face sintética, para que o fluxo de imagem possa ser convertido em vídeo em plataformas com 'capacidades de efeitos 'degradantes', como o Adobe After Effects, antes que os elementos falsos e reais sejam unidos para o vídeo final.
Além dessas degradações intencionais, o conteúdo do trabalho deepfake é frequentemente recomprimido, seja algoritmicamente (onde plataformas de mídia social buscam economizar largura de banda produzindo versões mais leves dos uploads dos usuários) em plataformas como YouTube e Facebook, ou pelo reprocessamento do trabalho original em GIFs animados, seções de detalhes ou outros fluxos de trabalho com motivações diversas que tratam o lançamento original como ponto de partida e, posteriormente, introduzem compactação adicional.
Contextos realistas de detecção de deepfake
Com isso em mente, um novo artigo da Suíça propôs uma reformulação da metodologia por trás das abordagens de detecção de deepfake, ensinando os sistemas de detecção a aprender as características do conteúdo deepfake quando ele é apresentado em contextos deliberadamente degradados.

Aumento de dados estocásticos aplicado a um dos conjuntos de dados usados no novo artigo, apresentando ruído gaussiano, correção gama e desfoque gaussiano, bem como artefatos de compactação JPEG. Fonte: https://arxiv.org/pdf/2203.11807.pdf
No novo artigo, os pesquisadores argumentam que os pacotes de detecção de deepfake de vanguarda dependem de condições de referência irrealistas para o contexto das métricas que aplicam, e que a saída de deepfake "degradada" pode ficar abaixo do limite mínimo de qualidade para detecção, embora seu conteúdo realisticamente "sujo" provavelmente engane os espectadores devido a uma atenção correta ao contexto.
Os pesquisadores instituíram um novo processo de degradação de dados "do mundo real" que conseguiu melhorar a generalização dos principais detectores de deepfake, com perda marginal de precisão em relação às taxas de detecção originais obtidas por dados "limpos". Eles também oferecem uma nova estrutura de avaliação que pode avaliar a robustez dos detectores de deepfake em condições do mundo real, apoiada por extensos estudos de ablação.
O papel é intitulado Uma nova abordagem para melhorar a detecção de deepfake baseada em aprendizado em condições realistas, e vem de pesquisadores do Multimedia Signal Processing Group (MMSPG) e da Ecole Polytechnique Federale de Lausanne (EPFL), ambos com sede em Lausanne.
Confusão Útil
Esforços anteriores para incorporar saída degradada em abordagens de detecção de deepfake incluem o Rede neural mista, uma oferta de 2018 do MIT e FAIR, e AugMix, uma colaboração de 2020 entre a DeepMind e o Google, ambos métodos de aumento de dados que tentam "turvar" o material de treinamento de uma forma que tende a ajudar na generalização.
Os pesquisadores do novo trabalho também observam prévio estudos que aplicou ruído gaussiano e artefatos de compressão a dados de treinamento para estabelecer os limites da relação entre um recurso derivado e o ruído no qual ele está inserido.
O novo estudo oferece um pipeline que simula as condições comprometidas tanto do processo de aquisição de imagens quanto da compressão, além de diversos outros algoritmos que podem degradar ainda mais a saída da imagem no processo de distribuição. Ao incorporar esse fluxo de trabalho do mundo real a uma estrutura avaliativa, é possível produzir dados de treinamento para detectores de deepfakes mais resistentes a artefatos.

A lógica conceitual e o fluxo de trabalho para a nova abordagem.
O processo de degradação foi aplicado a dois conjuntos de dados populares e bem-sucedidos usados para detecção de deepfake: FaceForensics ++ e Celeb-DFv2. Além disso, as principais estruturas de detecção de deepfake Cápsula-Forense e XceptionNet foram treinados nas versões adulteradas dos dois conjuntos de dados.
Os detectores foram treinados com o otimizador Adam por 25 e 10 épocas, respectivamente. Para a transformação do conjunto de dados, 100 quadros foram amostrados aleatoriamente de cada vídeo de treinamento, com 32 quadros extraídos para teste, antes da adição de processos degradantes.
As distorções consideradas para o fluxo de trabalho foram barulho, onde o ruído gaussiano de média zero foi aplicado em seis níveis variáveis; redimensionando, para simular a resolução reduzida de filmagem externa típica, que pode normalmente afetam detectores; no mundo , onde vários níveis de compactação JPEG foram aplicados aos dados; suavização, onde três filtros de suavização típicos usados em 'redução de ruído' são avaliados para a estrutura; aprimoramento, onde foram ajustados contraste e brilho; e combinações, onde qualquer combinação de três dos métodos mencionados acima foi aplicada simultaneamente a uma única imagem.
Testes e Resultados
Ao testar os dados, os pesquisadores adotaram três métricas: Precisão (ACC); Área sob a curva característica de operação do receptor (AUC); e Pontuação F1.
Os pesquisadores testaram as versões treinadas padrão dos dois detectores deepfake contra os dados adulterados e descobriram que faltavam:
Em geral, a maioria das distorções e processamentos realistas são extremamente prejudiciais para detectores de deepfake baseados em aprendizado normalmente treinados. Por exemplo, o método Capsule-Forensics apresenta pontuações de AUC muito altas nos conjuntos de teste FFpp não compactado e Celeb-DFv2 após o treinamento nos respectivos conjuntos de dados, mas sofre uma queda drástica de desempenho em dados modificados de nossa estrutura de avaliação. Tendências semelhantes foram observadas com o detector XceptionNet.
Por outro lado, o desempenho dos dois detectores foi notavelmente melhorado ao serem treinados nos dados transformados, com cada detector agora mais capaz de detectar mídia enganosa não vista.
'O esquema de aumento de dados melhora significativamente a robustez dos dois detectores e, ao mesmo tempo, eles ainda mantêm alto desempenho em dados originais inalterados.'

Comparações de desempenho entre os conjuntos de dados brutos e aumentados usados nos dois detectores deepfake avaliados no estudo.
O artigo conclui:
'Os métodos de detecção atuais são projetados para alcançar o desempenho mais alto possível em benchmarks específicos. Isso geralmente resulta em sacrificar a capacidade de generalização para cenários mais realistas. Neste artigo, um esquema de aumento de dados cuidadosamente concebido com base no processo de degradação natural da imagem é proposto.
'Experimentos extensivos mostram que a técnica simples, mas eficaz, melhora significativamente a robustez do modelo contra várias distorções realistas e operações de processamento em fluxos de trabalho de geração de imagens típicos.'
* A granulação correspondente na face gerada é uma função da transferência de estilo durante o processo de conversão.
Publicado pela primeira vez em 29 de março de 2022. Atualizado às 8h33 EST para esclarecer o uso de grãos no Ffmpeg.











