
Inteligência artificial
Otimização de preferência direta: um guia completo

Alinhar grandes modelos de linguagem (LLMs) com valores e preferências humanas é um desafio. Métodos tradicionais, como Aprendizagem por Reforço com Feedback Humano (RLHF), abriram caminho integrando informações humanas para refinar os resultados do modelo. No entanto, o RLHF pode ser complexo e consumir muitos recursos, exigindo poder computacional e processamento de dados substanciais. Otimização de preferência direta (DPO) surge como uma abordagem nova e mais simplificada, oferecendo uma alternativa eficiente a estes métodos tradicionais. Ao simplificar o processo de otimização, o DPO não apenas reduz a carga computacional, mas também aumenta a capacidade do modelo de se adaptar rapidamente às preferências humanas
Neste guia, nos aprofundaremos no DPO, explorando seus fundamentos, implementação e aplicações práticas.
A necessidade de alinhamento de preferências
Para entender o DPO, é crucial entender por que alinhar LLMs com preferências humanas é tão importante. Apesar de suas capacidades impressionantes, LLMs treinados em vastos conjuntos de dados podem, às vezes, produzir resultados inconsistentes, tendenciosos ou desalinhados com valores humanos. Esse desalinhamento pode se manifestar de várias maneiras:
- Geração de conteúdo inseguro ou prejudicial
- Fornecer informações imprecisas ou enganosas
- Exibindo vieses presentes nos dados de treinamento
Para resolver esses problemas, os pesquisadores desenvolveram técnicas para ajustar os LLMs usando feedback humano. A mais proeminente dessas abordagens foi a RLHF.
Compreendendo o RLHF: o precursor do DPO
A Aprendizagem por Reforço com Feedback Humano (RLHF) tem sido o método preferido para alinhar LLMs com as preferências humanas. Vamos analisar o processo RLHF para entender suas complexidades:
a) Ajuste fino supervisionado (SFT): O processo começa com o ajuste fino de um LLM pré-treinado em um conjunto de dados de respostas de alta qualidade. Esta etapa ajuda o modelo a gerar resultados mais relevantes e coerentes para a tarefa alvo.
b) Modelagem de recompensa: Um modelo de recompensa separado é treinado para prever as preferências humanas. Isso envolve:
- Gerando pares de respostas para determinados prompts
- Fazer com que os humanos avaliem qual resposta eles preferem
- Treinando um modelo para prever essas preferências
c) Aprendizagem por Reforço: O LLM ajustado é então otimizado ainda mais usando aprendizagem por reforço. O modelo de recompensa fornece feedback, orientando o LLM a gerar respostas que se alinhem com as preferências humanas.
Aqui está um pseudocódigo Python simplificado para ilustrar o processo RLHF:
Embora eficaz, o RLHF tem várias desvantagens:
- Requer treinamento e manutenção de vários modelos (SFT, modelo de recompensa e modelo otimizado para RL)
- O processo RL pode ser instável e sensível a hiperparâmetros
- É computacionalmente caro, exigindo muitas passagens para frente e para trás através dos modelos
Estas limitações motivaram a busca por alternativas mais simples e eficientes, levando ao desenvolvimento do DPO.
Otimização de preferência direta: conceitos básicos

Otimização de preferência direta https://arxiv.org/abs/2305.18290
Esta imagem contrasta duas abordagens distintas para alinhar os resultados do LLM com as preferências humanas: Aprendizagem por Reforço com Feedback Humano (RLHF) e Otimização de Preferência Direta (DPO). O RLHF depende de um modelo de recompensa para orientar a política do modelo de linguagem por meio de ciclos de feedback iterativos, enquanto o DPO otimiza diretamente os resultados do modelo para corresponder às respostas preferidas pelos humanos usando dados de preferência. Esta comparação destaca os pontos fortes e as aplicações potenciais de cada método, fornecendo insights sobre como os futuros LLMs podem ser treinados para se alinharem melhor com as expectativas humanas.
Ideias principais por trás do DPO:
a) Modelagem de recompensa implícita: O DPO elimina a necessidade de um modelo de recompensa separado, tratando o próprio modelo de linguagem como uma função de recompensa implícita.
b) Formulação Baseada em Políticas: Em vez de otimizar uma função de recompensa, o DPO otimiza diretamente a política (modelo de linguagem) para maximizar a probabilidade de respostas preferidas.
c) Solução de formulário fechado: o DPO aproveita uma visão matemática que permite uma solução fechada para a política ideal, evitando a necessidade de atualizações iterativas de RL.
Implementando DPO: um passo a passo prático do código
A imagem abaixo mostra um trecho de código que implementa a função de perda de DPO usando PyTorch. Esta função desempenha um papel crucial no refinamento de como os modelos de linguagem priorizam os resultados com base nas preferências humanas. Aqui está uma análise dos principais componentes:
- Assinatura de Função: O
dpo_lossA função aceita vários parâmetros, incluindo probabilidades de log de política (pi_logps), probabilidades de log do modelo de referência (ref_logps) e índices que representam conclusões preferenciais e não preferidas (yw_idxs,yl_idxs). Além disso, umbetaparâmetro controla a força da penalidade KL. - Extração de probabilidade de log: o código extrai as probabilidades de log para conclusões preferenciais e não preferidas dos modelos de política e de referência.
- Cálculo da razão logarítmica: a diferença entre as probabilidades de log para conclusões preferenciais e não preferenciais é calculada para os modelos de política e de referência. Essa proporção é crítica para determinar a direção e a magnitude da otimização.
- Cálculo de Perdas e Recompensas: A perda é calculada usando o
logsigmoidfunção, enquanto as recompensas são determinadas pelo dimensionamento da diferença entre a política e as probabilidades do log de referência porbeta.

Função de perda DPO usando PyTorch
Vamos mergulhar na matemática por trás do DPO para entender como ele atinge esses objetivos.
A Matemática do DPO
DPO é uma reformulação inteligente do problema de aprendizagem de preferências. Aqui está uma análise passo a passo:
a) Ponto de partida: Maximização de recompensa restrita por KL
O objetivo original do RLHF pode ser expresso como:
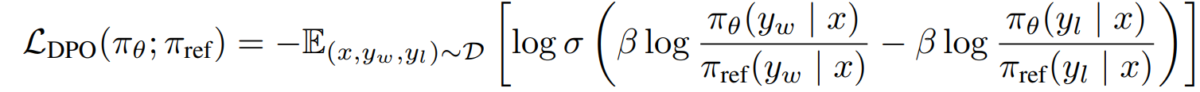
- πθ é a política (modelo de linguagem) que estamos otimizando
- r(x,y) é a função de recompensa
- πref é uma política de referência (geralmente o modelo SFT inicial)
- β controla a força da restrição de divergência KL
b) Formulário de política ideal: Pode-se mostrar que a política ótima para este objetivo assume a forma:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Onde Z(x) é uma constante de normalização.
c) Dualidade política de recompensa: O principal insight do DPO é expressar a função de recompensa em termos da política ideal:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Modelo de Preferência Supondo que as preferências sigam o modelo de Bradley-Terry, podemos expressar a probabilidade de preferir y1 a y2 como:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Onde σ é a função logística.
e) Objetivo do DPO Substituindo a nossa dualidade política de recompensas no modelo de preferência, chegamos ao objetivo do DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Este objetivo pode ser otimizado usando técnicas padrão de gradiente descendente, sem a necessidade de algoritmos RL.
Implementando DPO
Agora que entendemos a teoria por trás do DPO, vamos ver como implementá-lo na prática. Nós usaremos Python e PyTorch para este exemplo:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Desafios e Direções Futuras
Embora o DPO ofereça vantagens significativas em relação às abordagens tradicionais de RLHF, ainda existem desafios e áreas para futuras pesquisas:
a) Escalabilidade para modelos maiores:
À medida que os modelos de linguagem continuam a crescer em tamanho, a aplicação eficiente do DPO a modelos com centenas de bilhões de parâmetros continua sendo um desafio em aberto. Os pesquisadores estão explorando técnicas como:
- Métodos eficientes de ajuste fino (por exemplo, LoRA, ajuste de prefixo)
- Otimizações de treinamento distribuído
- Checkpoint de gradiente e treinamento de precisão mista
Exemplo de uso de LoRA com DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Adaptação multitarefa e de poucas fotos:
O desenvolvimento de técnicas de DPO que possam se adaptar eficientemente a novas tarefas ou domínios com dados de preferência limitados é uma área ativa de pesquisa. As abordagens que estão sendo exploradas incluem:
- Estruturas de meta-aprendizagem para adaptação rápida
- Ajuste fino baseado em prompt para DPO
- Transferir o aprendizado de modelos de preferência geral para domínios específicos
c) Lidar com preferências ambíguas ou conflitantes:
Os dados de preferências do mundo real muitas vezes contêm ambiguidades ou conflitos. É crucial melhorar a robustez do DPO relativamente a esses dados. As soluções potenciais incluem:
- Modelagem de preferência probabilística
- Aprendizagem ativa para resolver ambigüidades
- Agregação de preferências multiagentes
Exemplo de modelagem de preferência probabilística:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Combinando DPO com Outras Técnicas de Alinhamento:
A integração do DPO com outras abordagens de alinhamento poderia levar a sistemas mais robustos e capazes:
- Princípios constitucionais de IA para satisfação explícita de restrições
- Modelagem de debate e recompensa recursiva para elicitação de preferências complexas
- Aprendizagem por reforço inverso para inferir funções de recompensa subjacentes
Exemplo de combinação de DPO com IA constitucional:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Considerações Práticas e Melhores Práticas
Ao implementar o DPO para aplicativos do mundo real, considere as dicas a seguir:
a) Qualidade de dados: A qualidade dos seus dados de preferência é crucial. Certifique-se de que seu conjunto de dados:
- Abrange uma ampla gama de entradas e comportamentos desejados
- Possui anotações de preferências consistentes e confiáveis
- Equilibra diferentes tipos de preferências (por exemplo, factualidade, segurança, estilo)
b) Ajuste de hiperparâmetros: embora o DPO tenha menos hiperparâmetros que o RLHF, o ajuste ainda é importante:
- β (beta): Controla o trade-off entre satisfação de preferência e divergência do modelo de referência. Comece com valores ao redor 0.1-0.5.
- Taxa de aprendizagem: Use uma taxa de aprendizagem mais baixa do que o ajuste fino padrão, normalmente na faixa de 1e-6 a 1e-5.
- Tamanho do lote: Tamanhos de lote maiores (32-128) geralmente funcionam bem para aprendizagem preferencial.
c) Refinamento Iterativo: O DPO pode ser aplicado iterativamente:
- Treine um modelo inicial usando DPO
- Gere novas respostas usando o modelo treinado
- Colete novos dados de preferência sobre essas respostas
- Treine novamente usando o conjunto de dados expandido

Desempenho de otimização de preferência direta
Esta imagem mostra o desempenho de LLMs como GPT-4 em comparação com julgamentos humanos em várias técnicas de treinamento, incluindo Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT) e Proximal Policy Optimization (PPO). A tabela revela que as saídas do GPT-4 estão cada vez mais alinhadas com as preferências humanas, especialmente em tarefas de sumarização. O nível de concordância entre o GPT-4 e os revisores humanos demonstra a capacidade do modelo de gerar conteúdo que ressoa com avaliadores humanos, quase tão próximo quanto o conteúdo gerado por humanos.
Estudos de caso e aplicações
Para ilustrar a eficácia do DPO, vejamos algumas aplicações do mundo real e algumas de suas variantes:
- DPO Iterativo: Desenvolvida por Snorkel (2023), esta variante combina amostragem de rejeição com DPO, possibilitando um processo de seleção mais refinado para dados de treinamento. Ao iterar em várias rodadas de amostragem de preferência, o modelo é mais capaz de generalizar e evitar ajuste excessivo a preferências ruidosas ou tendenciosas.
- IPO (Otimização de preferência iterativa): Introduzido por Azar et al. (2023), o IPO adiciona um termo de regularização para evitar overfitting, que é um problema comum na otimização baseada em preferências. Esta extensão permite que os modelos mantenham um equilíbrio entre aderir às preferências e preservar as capacidades de generalização.
- KTO (Otimização da transferência de conhecimento): Uma variante mais recente de Ethayarajh et al. (2023), KTO dispensa totalmente as preferências binárias. Em vez disso, centra-se na transferência de conhecimento de um modelo de referência para o modelo político, optimizando para um alinhamento mais suave e consistente com os valores humanos.
- DPO multimodal para aprendizagem entre domínios por Xu et al. (2024): uma abordagem em que o DPO é aplicado em diferentes modalidades – texto, imagem e áudio – demonstrando sua versatilidade no alinhamento de modelos com preferências humanas em diversos tipos de dados. Esta pesquisa destaca o potencial do DPO na criação de sistemas de IA mais abrangentes, capazes de lidar com tarefas complexas e multimodais.











