Inteligência artificial
Guia Completo sobre Gemma 2: O Novo Modelo de Linguagem Aberto da Google

Gemma 2 é uma evolução de seu predecessor, oferecendo desempenho e eficiência aprimorados, além de uma série de recursos inovadores que o tornam particularmente atraente para aplicações de pesquisa e práticas. O que distingue Gemma 2 é sua capacidade de entregar desempenho comparável a modelos proprietários muito maiores, mas em um pacote projetado para acessibilidade mais ampla e uso em configurações de hardware mais modestas.
À medida que mergulhei nas especificações técnicas e arquitetura de Gemma 2, fiquei cada vez mais impressionado com a ingenuidade de seu design. O modelo incorpora várias técnicas avançadas, incluindo mecanismos de atenção novos e abordagens inovadoras para estabilidade de treinamento, que contribuem para suas capacidades notáveis.

Google Open Source LLM Gemma
Neste guia abrangente, exploraremos Gemma 2 em profundidade, examinando sua arquitetura, recursos-chave e aplicações práticas. Seja você um praticante de AI experiente ou um novo entusiasta no campo, este artigo visa fornecer insights valiosos sobre como Gemma 2 funciona e como você pode aproveitar seu poder em seus próprios projetos.
O que é Gemma 2?
Gemma 2 é o novo modelo de linguagem de código aberto da Google, projetado para ser leve, mas poderoso. Ele é construído com base na mesma pesquisa e tecnologia usadas para criar os modelos Gemini da Google, oferecendo desempenho de ponta em um pacote mais acessível. Gemma 2 vem em dois tamanhos:
Gemma 2 9B: Um modelo de 9 bilhões de parâmetros
Gemma 2 27B: Um modelo maior de 27 bilhões de parâmetros
Cada tamanho está disponível em duas variantes:
Modelos base: Pré-treinados em um vasto corpus de dados de texto
Modelos ajustados para instruções (IT): Ajustados para melhor desempenho em tarefas específicas
Acesse os modelos no Google AI Studio: Google AI Studio – Gemma 2
Leia o relatório técnico aqui: Relatório Técnico Gemma 2
Recursos-Chave e Melhorias
Gemma 2 introduz várias avanços significativos em relação a seu predecessor:
1. Aumento dos Dados de Treinamento
Os modelos foram treinados em muito mais dados:
Gemma 2 27B: Treinado em 13 trilhões de tokens
Gemma 2 9B: Treinado em 8 trilhões de tokens
Esse conjunto de dados expandido, consistindo principalmente de dados da web (em sua maioria em inglês), código e matemática, contribui para o desempenho melhorado e a versatilidade dos modelos.
2. Atenção com Janela Deslizante
Gemma 2 implementa uma abordagem nova para mecanismos de atenção:
Cada outra camada usa atenção com janela deslizante com um contexto local de 4096 tokens
Camadas alternadas empregam atenção global quadrática completa em todo o contexto de 8192 tokens
Essa abordagem híbrida visa equilibrar eficiência com a capacidade de capturar dependências de longo alcance na entrada.
3. Limitação Suave
Para melhorar a estabilidade e o desempenho do treinamento, Gemma 2 introduz um mecanismo de limitação suave:
<p>def limitacao_suave(x, limite): return limite * torch.tanh(x / limite)</p> <p># Aplicado aos logits de atenção logits_atencao = limitacao_suave(logits_atencao, limite=50.0)</p> # Aplicado aos logits da camada final <p>logits_finais = limitacao_suave(logits_finais, limite=30.0)
Essa técnica impede que os logits cresçam excessivamente grandes sem truncamento rígido, mantendo mais informações e estabilizando o processo de treinamento.
- Gemma 2 9B: Um modelo de 9 bilhões de parâmetros
- Gemma 2 27B: Um modelo maior de 27 bilhões de parâmetros
Cada tamanho está disponível em duas variantes:
- Modelos base: Pré-treinados em um vasto corpus de dados de texto
- Modelos ajustados para instruções (IT): Ajustados para melhor desempenho em tarefas específicas
4. Destilação de Conhecimento
Para o modelo de 9B, Gemma 2 emprega técnicas de destilação de conhecimento:
- Pré-treinamento: O modelo de 9B aprende com um modelo professor maior durante o treinamento inicial
- Pós-treinamento: Tanto os modelos de 9B quanto 27B usam destilação de política para refinar seu desempenho
Esse processo ajuda o modelo menor a capturar as capacidades dos modelos maiores de forma mais eficaz.
5. Mesclagem de Modelos
Gemma 2 utiliza uma técnica de mesclagem de modelos chamada Warp, que combina vários modelos em três etapas:
- Média Móvel Exponencial (EMA) durante o ajuste fino de aprendizado por reforço
- Interpolação Linear Esférica (SLERP) após o ajuste fino de várias políticas
- Interpolação Linear em Direção à Inicialização (LITI) como etapa final
Essa abordagem visa criar um modelo final mais robusto e capaz.
Benchmarks de Desempenho
Gemma 2 demonstra desempenho impressionante em várias benchmarks:
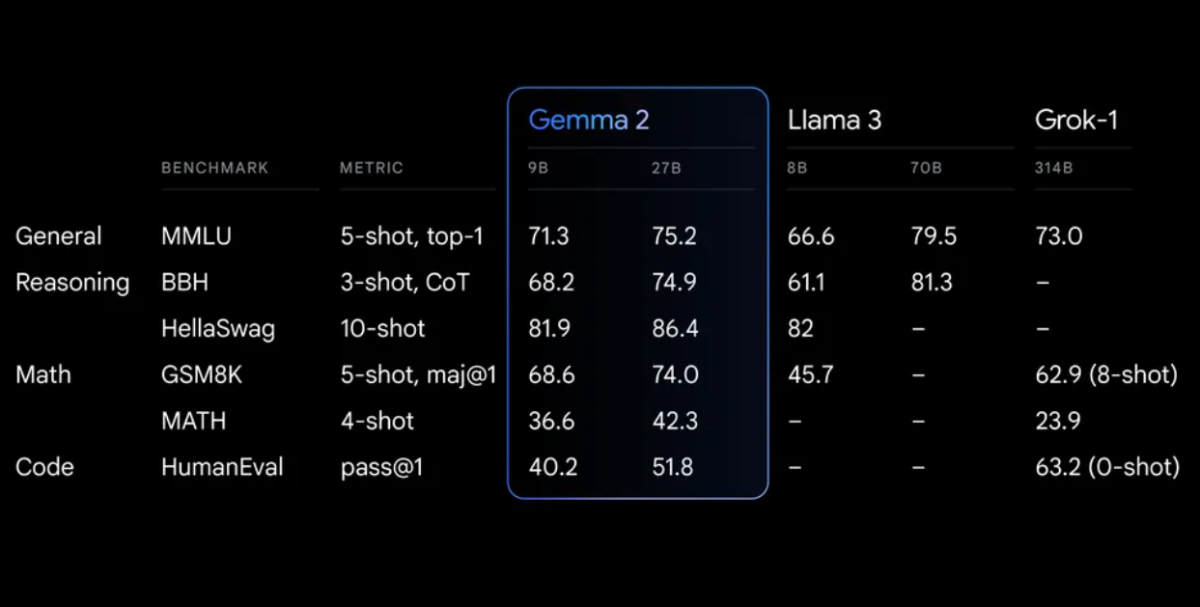
Gemma 2 em uma arquitetura redesenhada, projetada para desempenho excepcional e eficiência de inferência
Começando com Gemma 2
Para começar a usar Gemma 2 em seus projetos, você tem várias opções:
1. Google AI Studio
Para experimentação rápida sem requisitos de hardware, você pode acessar Gemma 2 por meio do Google AI Studio.
2. Hugging Face Transformers
Gemma 2 é integrado à biblioteca Hugging Face Transformers. Aqui está como você pode usá-lo:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> <p>from transformers import AutoTokenizer, AutoModelForCausalLM</p> <p># Carregue o modelo e o tokenizador nome_modelo = "google/gemma-2-27b-it" # ou "google/gemma-2-9b-it" para a versão menor tokenizador = AutoTokenizer.from_pretrained(nome_modelo) modelo = AutoModelForCausalLM.from_pretrained(nome_modelo)</p> <p># Prepare a entrada prompt = "Explique o conceito de entrelaçamento quântico em termos simples." entradas = tokenizador(prompt, return_tensors="pt")</p> <p># Gere texto saidas = modelo.generate(**entradas, max_length=200) resposta = tokenizador.decode(saidas[0], skip_special_tokens=True)</p> print(resposta)
3. TensorFlow/Keras
Para usuários do TensorFlow, Gemma 2 está disponível por meio do Keras:
<p>import tensorflow as tf from keras_nlp.models import GemmaCausalLM</p> <p># Carregue o modelo modelo = GemmaCausalLM.from_preset("gemma_2b_en")</p> <p># Gere texto prompt = "Explique o conceito de entrelaçamento quântico em termos simples." saida = modelo.generate(prompt, max_length=200)</p> print(saida)
Uso Avançado: Construindo um Sistema RAG Local com Gemma 2
Uma aplicação poderosa de Gemma 2 é na construção de um sistema de Geração Aumentada por Recuperação (RAG). Vamos criar um sistema RAG simples e totalmente local usando Gemma 2 e embeddings Nomic.
Etapa 1: Configurando o Ambiente
Primeiro, certifique-se de que você tem as bibliotecas necessárias instaladas:
<p>pip install langchain ollama nomic chromadb</p>
Etapa 2: Indexando Documentos
Crie um indexador para processar seus documentos:
<p>import os from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.document_loaders import DirectoryLoader from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings</p> <p>class Indexador: def __init__(self, caminho_diretorio): self.caminho_diretorio = caminho_diretorio self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")</p> <p>def carregar_e_dividir_documentos(self): carregador = DirectoryLoader(self.caminho_diretorio, glob="**/*.txt") documentos = carregador.load() return self.text_splitter.split_documents(documentos)</p> <p>def criar_armazenamento_de_vetores(self, documentos): return Chroma.from_documents(documentos, self.embeddings, persist_directory="./chroma_db")</p> <p>def indexar(self): documentos = self.carregar_e_dividir_documentos() armazenamento_de_vetores = self.criar_armazenamento_de_vetores(documentos) armazenamento_de_vetores.persist() return armazenamento_de_vetores</p> <p># Uso indexador = Indexador("caminho/para/seus/documentos") armazenamento_de_vetores = indexador.indexar()</p>
Etapa 3: Configurando o Sistema RAG
Agora, vamos criar o sistema RAG usando Gemma 2:
<p>from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate</p>
<p>class SistemaRAG:
def __init__(self, armazenamento_de_vetores):
self.armazenamento_de_vetores = armazenamento_de_vetores
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.armazenamento_de_vetores.as_retriever(search_kwargs={"k": 3})</p>
<p>self.template = """Use as seguintes partes do contexto para responder à pergunta no final.
Se você não souber a resposta, apenas diga que não sabe, não tente inventar uma resposta.</p>
{contexto}
<p>Pergunta: {pergunta}
Resposta: """</p>
<p>self.prompt_pergunta = PromptTemplate(
template=self.template, input_variables=["contexto", "pergunta"]
)</p>
<p>self.cadeia_pergunta = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.prompt_pergunta}
)</p>
<p>def consultar(self, pergunta):
return self.cadeia_pergunta({"query": pergunta})</p>
<p># Uso
sistema_rag = SistemaRAG(armazenamento_de_vetores)
resposta = sistema_rag.consultar("Qual é a capital da França?")
print(resposta["result"])</p>
Esse sistema RAG usa Gemma 2 por meio do Ollama para o modelo de linguagem e embeddings Nomic para recuperação de documentos. Ele permite que você faça perguntas com base nos documentos indexados, fornecendo respostas com contexto das fontes relevantes.
Ajuste Fino de Gemma 2
Para tarefas ou domínios específicos, você pode querer ajustar Gemma 2. Aqui está um exemplo básico usando a biblioteca Hugging Face Transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer from datasets import load_dataset <p># Carregue o modelo e o tokenizador nome_modelo = "google/gemma-2-9b-it" tokenizador = AutoTokenizer.from_pretrained(nome_modelo) modelo = AutoModelForCausalLM.from_pretrained(nome_modelo)</p> <p># Prepare o conjunto de dados conjunto_de_dados = load_dataset("seu_conjunto_de_dados")</p> <p>def funcao_tokenizar(exemplos): return tokenizador(exemplos["texto"], padding="max_length", truncation=True)</p> <p>conjunto_de_dados_tokenizado = conjunto_de_dados.map(funcao_tokenizar, batched=True)</p> <p># Defina os argumentos de treinamento argumentos_treinamento = TrainingArguments( output_dir="./resultados", num_train_epochs=3, per_device_train_batch_size=4, per_device_eval_batch_size=4, warmup_steps=500, weight_decay=0.01, logging_dir="./logs", )</p> <p># Inicialize o treinador treinador = Trainer( modelo=modelo, args=argumentos_treinamento, train_dataset=conjunto_de_dados_tokenizado["treino"], eval_dataset=conjunto_de_dados_tokenizado["teste"], )</p> # Inicie o ajuste fino treinador.train() <p># Salve o modelo ajustado modelo.save_pretrained("./modelo_ajustado_gemma2") tokenizador.save_pretrained("./modelo_ajustado_gemma2")</p>
Lembre-se de ajustar os parâmetros de treinamento com base em suas necessidades específicas e recursos computacionais.
Considerações Éticas e Limitações
Embora Gemma 2 ofereça capacidades impressionantes, é crucial estar ciente de suas limitações e considerações éticas:
- Vieses: Como todos os modelos de linguagem, Gemma 2 pode refletir vieses presentes em seus dados de treinamento. Avalie sempre criticamente suas saídas.
- Exatidão Factual: Embora muito capaz, Gemma 2 pode às vezes gerar informações incorretas ou inconsistentes. Verifique fatos importantes de fontes confiáveis.
- Comprimento de Contexto: Gemma 2 tem um comprimento de contexto de 8192 tokens. Para documentos ou conversas mais longos, você pode precisar implementar estratégias para gerenciar o contexto de forma eficaz.
- Recursos Computacionais: Especialmente para o modelo de 27B, recursos computacionais significativos podem ser necessários para inferência e ajuste fino eficientes.
- Uso Responsável: Adira às práticas de AI responsável da Google e certifique-se de que o uso de Gemma 2 esteja alinhado com princípios éticos de AI.
Conclusão
Gemma 2, com recursos avançados como atenção com janela deslizante, limitação suave e técnicas de mesclagem de modelos novas, é uma ferramenta poderosa para uma ampla gama de tarefas de processamento de linguagem natural.
Ao aproveitar Gemma 2 em seus projetos, seja por meio de inferência simples, sistemas RAG complexos ou modelos ajustados para domínios específicos, você pode aproveitar o poder da AI de ponta enquanto mantém controle sobre seus dados e processos.












