
Inteligência artificial
Cerebras apresenta a solução de inferência de IA mais rápida do mundo: velocidade 20x por uma fração do custo
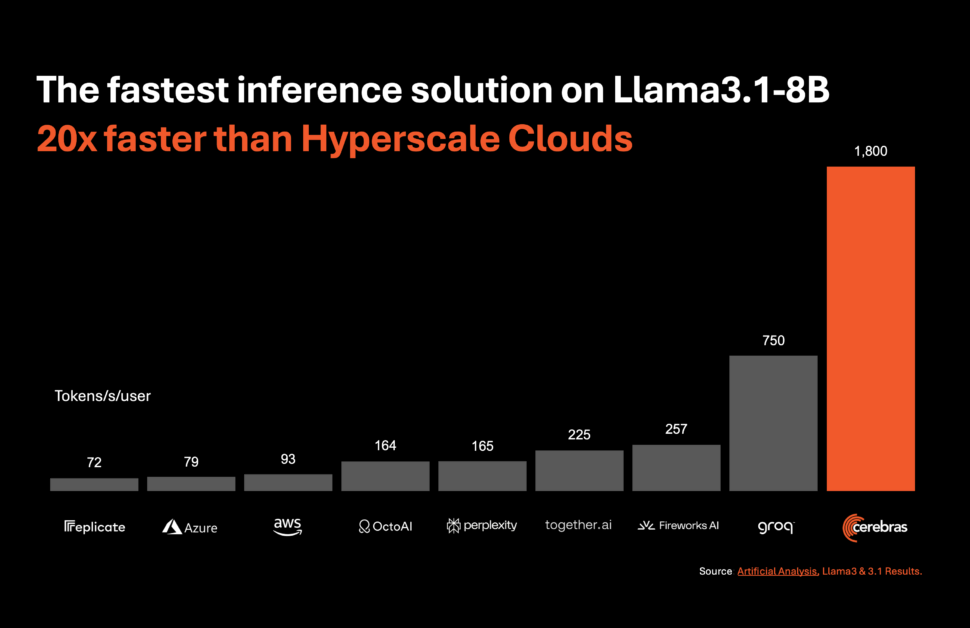
Sistemas de Cerebras, pioneira em computação de IA de alto desempenho, introduziu uma solução inovadora que irá revolucionar a inferência de IA. Em 27 de agosto de 2024, a empresa anunciou o lançamento do Cerebras Inference, o serviço de inferência de IA mais rápido do mundo. Com métricas de desempenho que superam as dos sistemas tradicionais baseados em GPU, o Cerebras Inference oferece 20 vezes mais velocidade por uma fração do custo, estabelecendo uma nova referência em computação de IA.
Velocidade e eficiência de custos sem precedentes
O Cerebras Inference foi projetado para oferecer desempenho excepcional em vários modelos de IA, especialmente no segmento de rápida evolução de grandes modelos de linguagem (LLM). Por exemplo, ele processa 1,800 tokens por segundo para o modelo Llama 3.1 8B e 450 tokens por segundo para o modelo Llama 3.1 70B. Esse desempenho não é apenas 20 vezes mais rápido que o das soluções baseadas em GPU NVIDIA, mas também tem um custo significativamente menor. A Cerebras oferece este serviço a partir de apenas 10 centavos por milhão de tokens para o modelo Llama 3.1 8B e 60 centavos por milhão de tokens para o modelo Llama 3.1 70B, representando uma melhoria de 100x no preço-desempenho em comparação com as ofertas existentes baseadas em GPU.
Mantendo a precisão enquanto ultrapassa os limites da velocidade
Um dos aspectos mais impressionantes do Cerebras Inference é sua capacidade de manter a precisão de última geração e, ao mesmo tempo, oferecer velocidade incomparável. Ao contrário de outras abordagens que sacrificam a precisão pela velocidade, a solução da Cerebras permanece dentro do domínio de 16 bits durante toda a execução de inferência. Isso garante que os ganhos de desempenho não ocorram às custas da qualidade dos resultados do modelo de IA, um fator crucial para desenvolvedores focados na precisão.
Micah Hill-Smith, cofundador e CEO da Artificial Analysis, destacou a importância desta conquista: “A Cerebras está oferecendo velocidades uma ordem de magnitude mais rápidas do que as soluções baseadas em GPU para os modelos Llama 3.1 8B e 70B AI da Meta. Estamos medindo velocidades acima de 1,800 tokens de saída por segundo no Llama 3.1 8B e acima de 446 tokens de saída por segundo no Llama 3.1 70B – um novo recorde nesses benchmarks.”
A crescente importância da inferência de IA
Inferência de IA é o segmento de computação de IA que mais cresce, respondendo por aproximadamente 40% do mercado total de hardware de IA. O advento da inferência de IA de alta velocidade, como a oferecida pela Cerebras, é semelhante à introdução da Internet de banda larga – abrindo novas oportunidades e anunciando uma nova era para aplicações de IA. Com o Cerebras Inference, os desenvolvedores agora podem construir aplicativos de IA de próxima geração que exigem desempenho complexo e em tempo real, como agentes de IA e sistemas inteligentes.
Andrew Ng, fundador da DeepLearning.AI, destacou a importância da velocidade no desenvolvimento de IA: “DeepLearning.AI tem vários fluxos de trabalho de agente que exigem a solicitação repetida de um LLM para obter um resultado. A Cerebras construiu uma capacidade de inferência impressionantemente rápida que será muito útil para tais cargas de trabalho."

Amplo apoio à indústria e parcerias estratégicas
A Cerebras obteve forte apoio de líderes do setor e formou parcerias estratégicas para acelerar o desenvolvimento de aplicações de IA. Kim Branson, vice-presidente sênior de IA/ML da GlaxoSmithKline, um dos primeiros clientes da Cerebras, enfatizou o potencial transformador desta tecnologia: “Velocidade e escala mudam tudo.”
Outras empresas, como LiveKit, Perplexidadee Meter também expressaram entusiasmo pelo impacto que a Cerebras Inference terá em suas operações. Essas empresas estão aproveitando o poder dos recursos computacionais da Cerebras para criar experiências de IA mais responsivas e semelhantes às humanas, melhorar a interação do usuário em mecanismos de busca e aprimorar os sistemas de gerenciamento de rede.
Inferência Cerebras: níveis e acessibilidade
O Cerebras Inference está disponível em três níveis com preços competitivos: Gratuito, Desenvolvedor e Empresarial. O nível gratuito fornece acesso gratuito à API com limites de uso generosos, tornando-o acessível a uma ampla gama de usuários. O nível de desenvolvedor oferece uma opção de implantação flexível e sem servidor, com modelos Llama 3.1 custando 10 centavos e 60 centavos por milhão de tokens. O nível Enterprise atende organizações com cargas de trabalho sustentadas, oferecendo modelos ajustados, acordos de nível de serviço personalizados e suporte dedicado, com preços disponíveis mediante solicitação.
Impulsionando a Inferência do Cerebras: O Wafer Scale Engine 3 (WSE-3)
No centro do Cerebras Inference está o sistema Cerebras CS-3, alimentado pelo Wafer Scale Engine 3 (WSE-3) líder do setor. Este processador AI é incomparável em tamanho e velocidade, oferecendo 7,000 vezes mais largura de banda de memória do que o H100 da NVIDIA. A enorme escala do WSE-3 permite lidar com muitos usuários simultâneos, garantindo velocidades alucinantes sem comprometer o desempenho. Essa arquitetura permite que a Cerebras evite as compensações que normalmente afetam os sistemas baseados em GPU, fornecendo o melhor desempenho da categoria para cargas de trabalho de IA.
Integração perfeita e API amigável ao desenvolvedor
O Cerebras Inference foi projetado pensando nos desenvolvedores. Possui uma API totalmente compatível com a API OpenAI Chat Completions, permitindo fácil migração com alterações mínimas de código. Essa abordagem amigável ao desenvolvedor garante que a integração do Cerebras Inference aos fluxos de trabalho existentes seja a mais perfeita possível, permitindo a rápida implantação de aplicativos de IA de alto desempenho.
Cerebras Systems: impulsionando a inovação em todos os setores
A Cerebras Systems não é apenas líder em computação de IA, mas também um participante importante em vários setores, incluindo saúde, energia, governo, computação científica e serviços financeiros. As soluções da empresa foram fundamentais para impulsionar avanços em instituições como o National Laboratories, Aleph Alpha, The Mayo Clinic e GlaxoSmithKline.
Ao fornecer velocidade, escalabilidade e precisão incomparáveis, a Cerebras está permitindo que organizações desses setores enfrentem alguns dos problemas mais desafiadores em IA e além. Seja acelerando a descoberta de medicamentos na área da saúde ou aprimorando as capacidades computacionais na pesquisa científica, a Cerebras está na vanguarda na promoção da inovação.
Conclusão: uma nova era para inferência de IA
A Cerebras Systems está estabelecendo um novo padrão para inferência de IA com o lançamento do Cerebras Inference. Ao oferecer 20 vezes a velocidade dos sistemas tradicionais baseados em GPU por uma fração do custo, a Cerebras não está apenas tornando a IA mais acessível, mas também abrindo caminho para a próxima geração de aplicações de IA. Com sua tecnologia de ponta, parcerias estratégicas e compromisso com a inovação, a Cerebras está preparada para liderar a indústria de IA em uma nova era de desempenho e escalabilidade sem precedentes.
Para obter mais informações sobre Cerebras Systems e experimentar o Cerebras Inference, visite www.cerebras.ai.







