Inteligência artificial
AudioSep : Separe Anything You Describe
LASS ou Separação de Fonte de Áudio por Consulta de Linguagem é o novo paradigma para CASA ou Análise Auditiva Computacional que visa separar um som-alvo de uma mistura de áudio usando uma consulta de linguagem natural que fornece a interface escalável e natural para tarefas e aplicações de áudio digital. Embora os quadros LASS tenham avançado significativamente nos últimos anos em termos de alcançar o desempenho desejado em fontes de áudio específicas, como instrumentos musicais, eles não conseguem separar o áudio-alvo no domínio aberto.
AudioSep, é um modelo fundamental que visa resolver as limitações atuais dos quadros LASS, permitindo a separação de áudio-alvo usando consultas de linguagem natural. Os desenvolvedores do quadro AudioSep treinaram o modelo extensivamente em uma ampla variedade de conjuntos de dados multimodais em larga escala e avaliaram o desempenho do quadro em uma ampla gama de tarefas de áudio, incluindo separação de instrumentos musicais, separação de eventos de áudio e melhoria da fala, entre muitas outras. O desempenho inicial do AudioSep atende aos benchmarks, pois demonstra impressionantes capacidades de aprendizado zero-shot e entrega um forte desempenho de separação de áudio.
Neste artigo, vamos mergulhar mais profundamente no funcionamento do quadro AudioSep, avaliando a arquitetura do modelo, os conjuntos de dados usados para treinamento e avaliação e os conceitos essenciais envolvidos no funcionamento do modelo AudioSep. Vamos começar com uma introdução básica ao quadro CASA.
CASA, USS, QSS, LASS Quadros : A Fundação para AudioSep
O quadro CASA ou Análise Auditiva Computacional é um quadro usado por desenvolvedores para projetar sistemas de escuta de máquina que têm a capacidade de perceber ambientes sonoros complexos de uma maneira semelhante à forma como os humanos percebem o som usando seus sistemas auditivos. A separação de som, com foco especial na separação de som-alvo, é uma área fundamental de pesquisa dentro do quadro CASA, e visa resolver o problema do “cocktail party” ou separar gravações de áudio reais de gravações de fonte de áudio individuais ou arquivos. A importância da separação de som pode ser atribuída principalmente às suas amplas aplicações, incluindo separação de fonte de música, separação de fonte de áudio, melhoria da fala, identificação de som-alvo e muito mais.
A maior parte do trabalho sobre separação de som feito no passado gira principalmente em torno da separação de uma ou mais fontes de áudio, como separação de música ou separação de fala. Um novo modelo chamado USS ou Separação Universal de Som visa separar sons arbitrários em gravações de áudio reais. No entanto, é uma tarefa desafiadora e restritiva separar todas as fontes de som de uma mistura de áudio, principalmente devido à ampla gama de fontes de som diferentes existentes no mundo, que é o principal motivo pelo qual o método USS não é viável para aplicações reais que funcionam em tempo real.
Uma alternativa viável ao método USS é o método QSS ou Separação de Som Baseada em Consulta, que visa separar uma fonte de som individual ou um som-alvo de uma mistura de áudio com base em um conjunto específico de consultas. Graças a isso, o quadro QSS permite que os desenvolvedores e usuários extraiam as fontes de áudio desejadas da mistura com base em seus requisitos, o que torna o método QSS uma solução mais prática para aplicações digitais reais, como edição de conteúdo multimídia ou edição de áudio.
Além disso, os desenvolvedores propuseram recentemente uma extensão do quadro QSS, o quadro LASS ou Separação de Fonte de Áudio por Consulta de Linguagem, que visa separar fontes de som arbitrárias de uma mistura de áudio usando descrições de linguagem natural do som-alvo. Como o quadro LASS permite que os usuários extraiam as fontes de áudio-alvo usando um conjunto de instruções de linguagem natural, ele pode se tornar uma ferramenta poderosa com aplicações amplas em aplicações de áudio digital. Quando comparado com métodos tradicionais de consulta de áudio ou visão, usar instruções de linguagem natural para separação de áudio oferece um grau maior de vantagem, pois adiciona flexibilidade e torna a aquisição de informações de consulta muito mais fácil e conveniente. Além disso, quando comparado com quadros de separação de áudio baseados em rótulos que usam um conjunto pré-definido de instruções ou consultas, o quadro LASS não limita o número de consultas de entrada e tem a flexibilidade de ser generalizado para domínio aberto de forma transparente.
Originalmente, o quadro LASS depende de aprendizado supervisionado, no qual o modelo é treinado em um conjunto de dados de áudio-texto rotulados. No entanto, o principal problema com essa abordagem é a limitada disponibilidade de dados de áudio-texto rotulados e anotados. Para reduzir a dependência do quadro LASS em dados de áudio-texto rotulados, os modelos são treinados usando a abordagem de aprendizado de supervisão multimodal. O objetivo principal por trás do uso de uma abordagem de supervisão multimodal é usar modelos de pré-treinamento contrastivo multimodal, como o modelo CLIP ou Contraste de Pré-treinamento de Linguagem e Imagem, como codificador de consulta para o quadro. Como o modelo CLIP tem a capacidade de alinhar embeddings de texto com outras modalidades, como áudio ou visão, ele permite que os desenvolvedores treinem os modelos LASS usando modalidades ricas em dados e permitam a interferência com os dados textuais em um ambiente de zero-shot. Os quadros LASS atuais, no entanto, usam conjuntos de dados em pequena escala para treinamento, e as aplicações do quadro LASS em centenas de domínios potenciais ainda precisam ser exploradas.
Para resolver as limitações atuais enfrentadas pelos quadros LASS, os desenvolvedores introduziram o AudioSep, um modelo fundamental que visa separar som de uma mistura de áudio usando descrições de linguagem natural. O foco atual para o AudioSep é desenvolver um modelo de separação de som pré-treinado que aproveite conjuntos de dados multimodais em larga escala para permitir a generalização de modelos LASS em aplicações de domínio aberto. Para resumir, o modelo AudioSep é: “Um modelo fundamental para separação universal de som em domínio aberto usando consultas ou descrições de linguagem natural treinadas em conjuntos de dados de áudio e multimodais em larga escala”.
AudioSep : Componentes Chave e Arquitetura
A arquitetura do quadro AudioSep compreende dois componentes principais: um codificador de texto e um modelo de separação.
O Codificador de Texto
O quadro AudioSep usa um codificador de texto do modelo CLIP ou Contraste de Pré-treinamento de Linguagem e Imagem, ou o modelo CLAP ou Contraste de Pré-treinamento de Linguagem e Áudio, para extrair embeddings de texto dentro de uma consulta de linguagem natural. A consulta de texto de entrada consiste em uma sequência de “N” tokens que é processada pelo codificador de texto para extrair os embeddings de texto para a consulta de linguagem de entrada. O codificador de texto usa uma pilha de blocos de transformador para codificar os tokens de texto de entrada, e as representações de saída são agregadas após serem passadas pelas camadas de transformador, o que resulta no desenvolvimento de uma representação vetorial de comprimento fixo, onde D corresponde às dimensões dos modelos CLAP ou CLIP, enquanto o codificador de texto é congelado durante o período de treinamento.
O modelo CLIP é pré-treinado em um conjunto de dados em larga escala de pares de dados de imagem-texto usando aprendizado contrastivo, o que é o principal motivo pelo qual o codificador de texto do CLIP aprende a mapear descrições textuais no espaço semântico compartilhado pelas representações visuais. A vantagem que o AudioSep ganha ao usar o codificador de texto do CLIP é que agora pode escalar ou treinar o modelo LASS a partir de dados de áudio-visão não rotulados, usando as embeddings visuais como uma alternativa, permitindo assim o treinamento de modelos LASS sem a necessidade de dados de áudio-texto rotulados e anotados.
O modelo CLAP funciona de forma semelhante ao modelo CLIP e usa um objetivo de aprendizado contrastivo, pois usa um codificador de texto e um codificador de áudio para conectar áudio e linguagem, trazendo assim descrições de texto e áudio para um espaço latente de áudio-texto unido.
Modelo de Separação
O quadro AudioSep usa um modelo ResUNet de domínio de frequência que é alimentado com uma mistura de cliques de áudio como a espinha dorsal da separação para o quadro. O quadro funciona aplicando uma Transformada de Fourier de Tempo Curto (STFT) na onda para extrair um espectrograma complexo, o espectrograma de magnitude e a Fase de X. O modelo então segue o mesmo ajuste e constrói uma rede codificador-decodificador para processar o espectrograma de magnitude.
A rede ResUNet codificador-decodificador consiste em 6 blocos residuais, 6 blocos decodificadores e 4 blocos de gargalo. O espectrograma em cada bloco codificador usa 4 blocos convencionais residuais para diminuir a amostragem em um recurso de gargalo, enquanto os blocos decodificadores usam 4 blocos deconvolucionais residuais para obter os componentes de separação ao aumentar a amostragem dos recursos. Em seguida, cada um dos blocos codificador e seus blocos decodificadores correspondentes estabelece uma conexão de salto que opera na mesma taxa de aumento ou diminuição de amostragem. O bloco residual do quadro consiste em 2 camadas de ativação Leaky-ReLU, 2 camadas de normalização de lote e 2 camadas de CNN, e, além disso, o quadro introduz um atalho residual adicional que conecta a entrada e saída de cada bloco residual individual. O modelo ResUNet recebe o espectrograma complexo X como entrada e produz a máscara de magnitude M como saída, com o residual de fase condicionado às embeddings de texto que controla a magnitude de escala e rotação do ângulo do espectrograma. O espectrograma complexo separado pode então ser extraído multiplicando a máscara de magnitude prevista e o residual de fase com a Transformada de Fourier de Tempo Curto (STFT) da mistura.

No seu quadro, o AudioSep usa uma camada FiLm ou Modulada Linearmente por Recurso para conectar o modelo de separação e o codificador de texto após a implantação dos blocos convolucionais no ResUNet.
Treinamento e Perda
Durante o treinamento do modelo AudioSep, os desenvolvedores usam o método de aumento de volume e treinam o quadro AudioSep de ponta a ponta usando uma função de perda L1 entre as ondas de forma prevista e as ondas de forma reais.
Conjuntos de Dados e Benchmarks
Como mencionado em seções anteriores, o AudioSep é um modelo fundamental que visa resolver a dependência atual dos modelos LASS em conjuntos de dados de áudio-texto anotados. O modelo AudioSep é treinado em uma ampla variedade de conjuntos de dados para equipá-lo com capacidades de aprendizado multimodal, e aqui está uma descrição detalhada do conjunto de dados e benchmarks usados pelos desenvolvedores para treinar o quadro AudioSep.
AudioSet
O AudioSet é um conjunto de dados de áudio grande e rotulado, composto por mais de 2 milhões de cliques de áudio de 10 segundos extraídos diretamente do YouTube. Cada clique de áudio no conjunto de dados AudioSet é categorizado pela ausência ou presença de classes de som sem detalhes específicos de tempo dos eventos de som. O conjunto de dados AudioSet tem mais de 500 classes de áudio distintas, incluindo sons naturais, sons humanos, sons de veículos e muito mais.
VGGSound
O conjunto de dados VGGSound é um conjunto de dados de áudio-visão em larga escala que, assim como o AudioSet, foi extraído do YouTube e contém mais de 200.000 cliques de vídeo, cada um com 10 segundos de duração. O conjunto de dados VGGSound é categorizado em mais de 300 classes de som, incluindo sons humanos, sons naturais, sons de pássaros e mais. O uso do conjunto de dados VGGSound garante que o objeto responsável por produzir o som-alvo também seja descritível no clipe de vídeo correspondente.
AudioCaps
O AudioCaps é o maior conjunto de dados de legendas de áudio disponível publicamente e é composto por mais de 50.000 cliques de áudio de 10 segundos extraídos do conjunto de dados AudioSet. Os dados no AudioCaps são divididos em três categorias: dados de treinamento, dados de teste e dados de validação, e os cliques de áudio são anotados com descrições de linguagem natural usando a plataforma Amazon Mechanical Turk. É importante notar que cada clique de áudio no conjunto de dados de treinamento tem uma legenda, enquanto os dados de teste e validação têm 5 legendas reais cada.
ClothoV2
O ClothoV2 é um conjunto de dados de legendas de áudio que consiste em cliques extraídos da plataforma FreeSound, e, assim como o AudioCaps, cada clique de áudio é anotado com descrições de linguagem natural usando a plataforma Amazon Mechanical Turk.
WavCaps
Assim como o AudioSet, o WavCaps é um conjunto de dados de áudio grande e rotulado, composto por mais de 400.000 cliques de áudio com legendas, e um tempo de execução total aproximado de 7568 horas de dados de treinamento. Os cliques de áudio no conjunto de dados WavCaps são extraídos de uma ampla variedade de fontes de áudio, incluindo BBC Sound Effects, AudioSet, FreeSound, SoundBible e mais.

Detalhes de Treinamento
Durante a fase de treinamento, o modelo AudioSep amostra aleatoriamente dois segmentos de áudio de dois cliques de áudio diferentes do conjunto de dados de treinamento e os mistura para criar uma mistura de treinamento, onde o comprimento de cada segmento de áudio é de cerca de 5 segundos. O modelo então extrai o espectrograma complexo do sinal de onda usando uma janela Hann de tamanho 1024 com um tamanho de salto de 320.
O modelo então usa o codificador de texto dos modelos CLIP/CLAP para extrair as embeddings de texto com supervisão de texto sendo a configuração padrão para o AudioSep. Para o modelo de separação, o quadro AudioSep usa uma camada ResUNet composta por 30 camadas, 6 blocos codificador e 6 blocos decodificador, semelhante à arquitetura seguida no quadro de separação universal de som. Além disso, cada bloco codificador tem duas camadas convolucionais com um tamanho de kernel de 3×3, com o número de mapas de recursos de saída dos blocos codificador sendo 32, 64, 128, 256, 512 e 1024, respectivamente. Os blocos decodificadores compartilham simetria com os blocos codificador, e os desenvolvedores aplicam o otimizador Adam para treinar o modelo AudioSep com um tamanho de lote de 96.
Resultados de Avaliação
Em Conjuntos de Dados Vistos
A figura a seguir compara o desempenho do quadro AudioSep em conjuntos de dados vistos durante a fase de treinamento, incluindo os conjuntos de dados de treinamento. A figura abaixo representa os resultados de avaliação de benchmark do quadro AudioSep quando comparado com sistemas de linha de base, incluindo modelos de melhoria da fala, LASS e CLIP. O modelo AudioSep com codificador de texto CLIP é representado como AudioSep-CLIP, enquanto o modelo AudioSep com codificador de texto CLAP é representado como AudioSep-CLAP.

Como pode ser visto na figura, o quadro AudioSep se sai bem quando usa legendas de áudio ou rótulos de texto como consultas de entrada, e os resultados indicam o desempenho superior do quadro AudioSep quando comparado com os modelos LASS e de separação de som por consulta de áudio anteriores.
Em Conjuntos de Dados Não Vistos
Para avaliar o desempenho do AudioSep em um ambiente de zero-shot, os desenvolvedores continuaram a avaliar o desempenho em conjuntos de dados não vistos, e o quadro AudioSep entrega um desempenho de separação impressionante em um ambiente de zero-shot, e os resultados são exibidos na figura abaixo.

Além disso, a imagem abaixo mostra os resultados de avaliação do modelo AudioSep contra a melhoria da fala Voicebank-Demand.

A avaliação do quadro AudioSep indica um desempenho forte e desejado em conjuntos de dados não vistos em um ambiente de zero-shot, e assim abre caminho para realizar tarefas de operação de som em novas distribuições de dados.
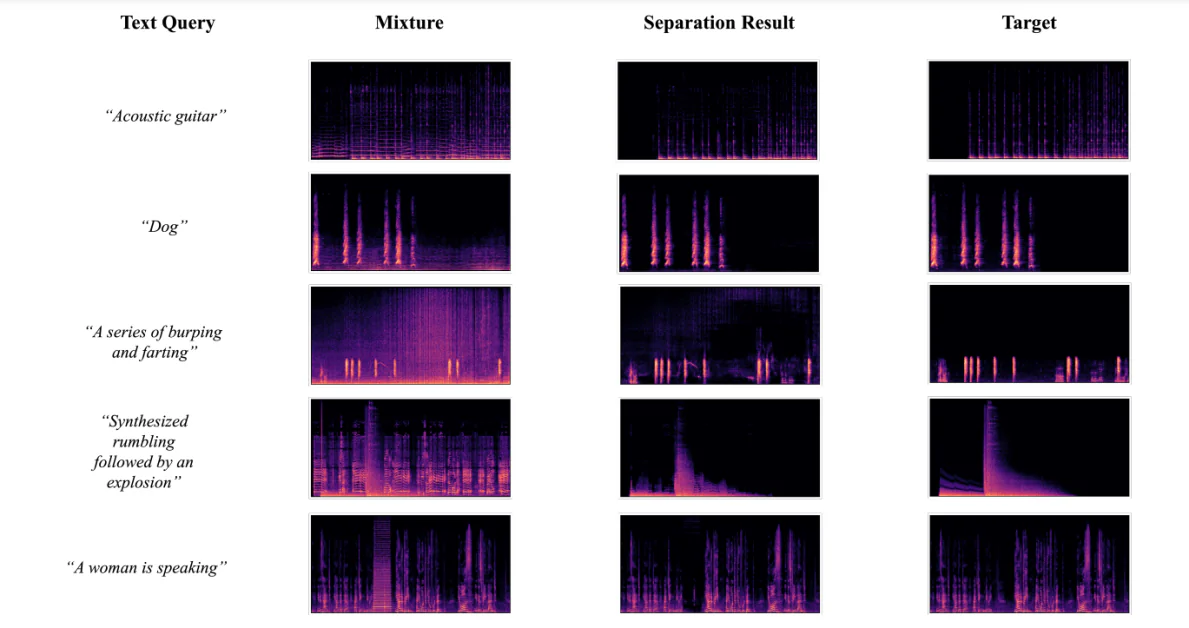
Visualização dos Resultados de Separação
A figura abaixo mostra os resultados obtidos quando os desenvolvedores usaram o quadro AudioSep-CLAP para realizar visualizações de espectrogramas para fontes de áudio-alvo reais, misturas de áudio e fontes de áudio separadas usando consultas de texto de áudios ou sons diversos. Os resultados permitiram que os desenvolvedores observassem que o padrão de fonte separada do espectrograma está próximo da fonte da verdade real, o que suporta ainda mais os resultados objetivos obtidos durante os experimentos.
Comparação de Consultas de Texto
Os desenvolvedores avaliam o desempenho do AudioSep-CLAP e do AudioSep-CLIP no AudioCaps Mini, e os desenvolvedores usam as etiquetas de eventos do AudioSet, as legendas do AudioCaps e as descrições de linguagem natural reanotadas para examinar os efeitos de diferentes consultas, e a figura abaixo mostra um exemplo do AudioCaps Mini em ação.

Conclusão
AudioSep é um modelo fundamental que foi desenvolvido com o objetivo de ser um quadro de separação universal de som em domínio aberto que usa descrições de linguagem natural para separação de áudio. Como observado durante a avaliação, o quadro AudioSep é capaz de realizar aprendizado zero-shot e não supervisionado de forma transparente, usando legendas de áudio ou rótulos de texto como consultas de entrada. Os resultados e o desempenho de avaliação do AudioSep indicam um desempenho forte que supera os quadros de separação de som atuais, como o LASS, e pode ser capaz de resolver as limitações atuais dos quadros de separação de som populares.












