
Ética
Práticas atuais de IA podem estar permitindo uma nova geração de trolls de direitos autorais

Uma nova colaboração de pesquisa entre a Huawei e a academia sugere que grande parte da pesquisa atual mais importante em inteligência artificial e aprendizado de máquina poderia ser exposta a litígios assim que se tornasse comercialmente proeminente, porque os conjuntos de dados que tornam possíveis os avanços estão sendo distribuídos com informações inválidas. licenças que não respeitam os termos originais dos domínios públicos dos quais os dados foram obtidos.
Com efeito, isso tem dois resultados possíveis quase inevitáveis: que algoritmos de IA comercializados muito bem-sucedidos, conhecidos por terem usado tais conjuntos de dados, se tornarão os alvos futuros de trolls de patentes oportunistas cujos direitos autorais não foram respeitados quando seus dados foram copiados; e que organizações e indivíduos poderão usar essas mesmas vulnerabilidades legais para protestar contra a implantação ou difusão de tecnologias de aprendizado de máquina que consideram censuráveis.
A papel é intitulado Posso usar este conjunto de dados disponível publicamente para criar software comercial de IA? Mais provável que não, e é uma colaboração entre a Huawei Canada e a Huawei China, juntamente com a York University no Reino Unido e a University of Victoria no Canadá.
Cinco de seis conjuntos de dados de código aberto (populares) não utilizáveis legalmente
Para a pesquisa, os autores pediram aos departamentos da Huawei que selecionassem os conjuntos de dados de código aberto mais desejáveis que gostariam de explorar em projetos comerciais e selecionaram os seis conjuntos de dados mais solicitados das respostas: CIFAR-10 (um subconjunto do 80 milhões de imagens minúsculas conjunto de dados, desde retirado para 'termos depreciativos' e 'imagens ofensivas', embora seus derivados proliferem); IMAGEnet; Cityscapes (que contém exclusivamente material original); FFHQ; VGG Face2 e MSCOCO.
Para analisar se os conjuntos de dados selecionados eram adequados para uso legal em projetos comerciais, os autores desenvolveram um novo pipeline para rastrear a cadeia de licenças tanto quanto possível para cada conjunto, embora muitas vezes tivessem que recorrer a capturas de arquivos da web para localizar licenças de domínios expirados e, em certos casos, ter que 'adivinhar' o status da licença a partir das informações disponíveis mais próximas.
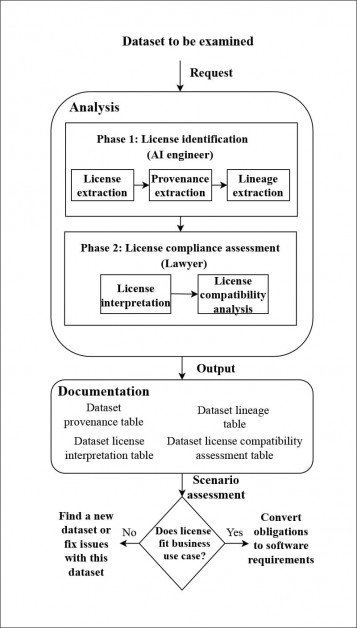
Arquitetura para o sistema de rastreamento de proveniência desenvolvida pelos autores. Fonte: https://arxiv.org/pdf/2111.02374.pdf
Os autores descobriram que as licenças para cinco dos seis conjuntos de dados 'contém riscos associados a pelo menos um contexto de uso comercial':
'[Nós] observamos que, exceto MS COCO, nenhuma das licenças estudadas permite aos profissionais o direito de comercializar um modelo de IA treinado nos dados ou mesmo a saída do modelo de IA treinado. Esse resultado também impede efetivamente que os profissionais usem modelos pré-treinados treinados nesses conjuntos de dados. Conjuntos de dados disponíveis publicamente e modelos de IA pré-treinados neles são amplamente utilizado comercialmente.' *
Os autores observam ainda que três dos seis conjuntos de dados estudados podem resultar em violação de licença em produtos comerciais se o conjunto de dados for modificado, uma vez que apenas o MS-COCO permite isso. No entanto, o aumento de dados e subconjuntos e superconjuntos de conjuntos de dados influentes são uma prática comum.
No caso do CIFAR-10, os compiladores originais não criaram nenhuma forma convencional de licença, exigindo apenas que os projetos que usam o conjunto de dados incluíssem uma citação do documento original que acompanhava a liberação do conjunto de dados, apresentando uma obstrução adicional ao estabelecimento o estatuto jurídico dos dados.
Além disso, apenas o conjunto de dados CityScapes contém material gerado exclusivamente pelos criadores do conjunto de dados, em vez de ser 'selecionado' (raspado) de fontes de rede, com CIFAR-10 e ImageNet usando várias fontes, cada uma das quais precisaria ser investigada e rastreado para estabelecer qualquer tipo de mecanismo de direitos autorais (ou mesmo um aviso significativo).
No Way Out
Existem três fatores nos quais as empresas comerciais de IA parecem confiar para protegê-las de litígios em torno de produtos que usaram conteúdo protegido por direitos autorais de conjuntos de dados livremente e sem permissão para treinar algoritmos de IA. Nenhum deles oferece muita (ou nenhuma) proteção confiável a longo prazo:
1: Leis Nacionais Laissez Faire
Embora os governos de todo o mundo sejam obrigados a relaxar as leis sobre a extração de dados em um esforço para não retroceder na corrida em direção à IA de alto desempenho (que depende de grandes volumes de dados do mundo real para os quais a conformidade e o licenciamento regulares de direitos autorais seriam irrealistas), apenas os Estados Unidos oferecem imunidade total a esse respeito, sob o Doutrina do Uso Justo – política ratificada em 2015 com o conclusão of Authors Guild v. Google, Inc., que afirmou que o gigante das buscas poderia ingerir livremente material protegido por direitos autorais para seu projeto Google Books sem ser acusado de infração.
Se a política da Fair Use Doctrine mudar (ou seja, em resposta a outro caso marcante envolvendo organizações ou corporações suficientemente poderosas), provavelmente seria considerado um a priori estado em termos de exploração de bancos de dados atuais que infringem direitos autorais, protegendo o uso anterior; mas não contínuo uso e desenvolvimento de sistemas que foram ativados por meio de material protegido por direitos autorais sem acordo.
Isso coloca a proteção atual da Doutrina do Uso Justo em uma base muito provisória e poderia, nesse cenário, exigir que os algoritmos de aprendizado de máquina comercializados e estabelecidos cessassem a operação nos casos em que suas origens foram habilitadas por material protegido por direitos autorais - mesmo nos casos em que o do modelo pesos agora lidam exclusivamente com conteúdo permitido, mas foram treinados (e tornaram-se úteis por) conteúdo copiado ilegalmente.
Fora dos EUA, como observam os autores no novo artigo, as políticas geralmente são menos tolerantes. O Reino Unido e o Canadá apenas indenizam o uso de dados protegidos por direitos autorais para fins não comerciais, enquanto a Lei de Mineração de Texto e Dados da UE (que não foi totalmente anulada pela propostas recentes para regulamentação de IA mais formal) também exclui a exploração comercial de sistemas de IA que não cumprem os requisitos de direitos autorais dos dados originais.
Esses últimos arranjos significam que uma organização pode realizar grandes coisas com os dados de outras pessoas, até – mas não incluindo – o ponto de ganhar algum dinheiro com isso. Nesse estágio, o produto ficaria legalmente exposto ou seriam necessários acordos com literalmente milhões de detentores de direitos autorais, muitos dos quais agora não podem ser rastreados devido à natureza mutável da Internet – uma perspectiva impossível e inacessível.
2: Advertência Emptor
Nos casos em que as organizações infratoras esperam adiar a culpa, o novo artigo também observa que muitas licenças para os conjuntos de dados de código aberto mais populares se indenizam automaticamente contra quaisquer reivindicações de abuso de direitos autorais:
'Por exemplo, a licença do ImageNet exige explicitamente que os profissionais indenizem a equipe do ImageNet contra quaisquer reivindicações decorrentes do uso do conjunto de dados. Os conjuntos de dados FFHQ, VGGFace2 e MS COCO exigem que o conjunto de dados, se distribuído ou modificado, seja apresentado sob a mesma licença.'
Efetivamente, isso força aqueles que usam conjuntos de dados FOSS a assumir a culpa pelo uso de material protegido por direitos autorais, em face de eventual litígio (embora não proteja necessariamente os compiladores originais em um caso em que o clima atual de 'porto seguro' é compreendido).
3: Indenização por obscuridade
A natureza colaborativa da comunidade de aprendizado de máquina torna bastante difícil usar o ocultismo corporativo para obscurecer a presença de algoritmos que se beneficiaram de conjuntos de dados que violam direitos autorais. Projetos comerciais de longo prazo geralmente começam em ambientes FOSS abertos, onde o uso de conjuntos de dados é uma questão de registro, no GitHub e em outros fóruns acessíveis ao público, ou onde as origens do projeto foram publicadas em artigos pré-impressos ou revisados por pares.
Mesmo onde isso não ocorre, inversão de modelo is cada vez mais capaz de revelar as características típicas dos conjuntos de dados (ou mesmo saída explicitamente parte do material de origem), fornecendo prova em si ou suspeita suficiente de violação para permitir o acesso ordenado pelo tribunal ao histórico do desenvolvimento do algoritmo e aos detalhes dos conjuntos de dados usados nesse desenvolvimento.
Conclusão
O artigo descreve um uso caótico e ad hoc de material protegido por direitos autorais obtido sem permissão e de uma série de cadeias de licenças que, seguidas logicamente desde a fonte original dos dados, exigiriam negociações com milhares de detentores de direitos autorais cujo trabalho foi apresentado sob a égide de sites com uma ampla variedade de termos de licenciamento, muitos impedindo trabalhos comerciais derivados.
Os autores concluem:
'Conjuntos de dados publicamente disponíveis estão sendo amplamente usados para construir software comercial de IA. Pode-se fazer isso se [e] somente se a licença associada ao conjunto de dados publicamente disponível fornecer o direito de fazê-lo. No entanto, não é fácil verificar os direitos e obrigações previstos na licença associada aos conjuntos de dados disponíveis publicamente. Porque, às vezes, a licença não é clara ou é potencialmente inválida.'
Mais um novo trabalho, intitulado Construindo conjuntos de dados jurídicos, divulgado em 2 de novembro pelo Center for Computational Law da Singapore Management University, também enfatiza a necessidade de cientistas de dados reconhecerem que a era do 'oeste selvagem' de coleta de dados ad hoc está chegando ao fim e reflete as recomendações da Huawei papel para adotar hábitos e metodologias mais rigorosos, a fim de garantir que o uso do conjunto de dados não exponha um projeto a ramificações legais à medida que a cultura muda com o tempo e a atual atividade acadêmica global no setor de aprendizado de máquina busca um retorno comercial em anos de investimento . O autor observa*:
'[O] corpo de legislação que afeta os conjuntos de dados de ML deve crescer, em meio a preocupações que as leis atuais oferecem insuficiente proteções. O projeto de AIA [Lei de Inteligência Artificial da UE], se e quando aprovado, alteraria significativamente o cenário de governança de dados e IA; outras jurisdições podem seguir o exemplo com suas próprias leis. '
* Minha conversão de citações inline em hiperlinks















