Inteligência artificial
A Inteligência Artificial Ajuda Falantes Nervosos a ‘Ler o Ambiente’ Durante Videoconferências

Em 2013, uma pesquisa sobre fobias comuns determinou que a perspectiva de falar em público era pior do que a perspectiva da morte para a maioria dos respondentes. A síndrome é conhecida como glossophobia.
A migração impulsionada pela COVID de reuniões “presenciais” para conferências online no Zoom em plataformas como Zoom e Google Spaces, surpreendentemente, não melhorou a situação. Quando a reunião contém um grande número de participantes, nossas habilidades naturais de avaliação de ameaças são prejudicadas pelas linhas e ícones de baixa resolução dos participantes e pela dificuldade em ler sinais visuais sutis de expressão facial e linguagem corporal. O Skype, por exemplo, foi considerado uma plataforma pobre para transmitir sinais não verbais.
Os efeitos no desempenho da fala em público da percepção de interesse e responsividade são bem documentados agora e intuitivamente óbvios para a maioria de nós. A resposta opaca do público pode causar hesitação nos falantes e fazer com que recorram a discurso de preenchimento, sem saber se seus argumentos estão encontrando concordância, desdém ou desinteresse, muitas vezes tornando a experiência desconfortável para ambos, o falante e seus ouvintes.
Sob pressão da mudança inesperada para videoconferências online inspirada pelas restrições e precauções da COVID, o problema é, sem dúvida, piorando, e vários esquemas de feedback de plateia foram sugeridos nas comunidades de visão computacional e pesquisa de afeto nos últimos dois anos.
Soluções Focadas em Hardware
A maioria deles, no entanto, envolve equipamentos adicionais ou software complexo que pode levantar questões de privacidade ou logísticas – estilos de abordagem relativamente de alto custo ou de outra forma limitados por recursos que precedem a pandemia. Em 2001, o MIT propôs o Galvactivator, um dispositivo wearable que infere o estado emocional do participante da plateia, testado durante um simpósio de um dia.

Em 2001, o Galvactivator do MIT, que mediu a resposta de condutividade da pele em uma tentativa de entender a opinião e o engajamento da plateia. Fonte: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Uma grande quantidade de energia acadêmica também foi dedicada à possível implantação de ‘controle remoto’ como um Sistema de Resposta da Plateia (ARS), uma medida para aumentar a participação ativa das plateias (o que automaticamente aumenta o engajamento, desde que force o visualizador a desempenhar o papel de um nó de feedback ativo), mas que também foi imaginado como um meio de encorajamento do falante.
Outras tentativas de ‘conectar’ o falante e a plateia incluíram monitoramento da frequência cardíaca, o uso de equipamentos complexos corporais para aproveitar a eletroencefalografia, ‘medidores de aplausos’, reconhecimento de emoções baseado em visão computacional para trabalhadores de mesa, e o uso de emoticons enviados pela plateia durante a oração do falante.

Em 2017, o EngageMeter, um projeto de pesquisa acadêmica conjunto da LMU Munich e da Universidade de Stuttgart. Fonte: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Como uma sub-busca da área lucrativa de análise de plateia, o setor privado tem um interesse particular em estimativa e rastreamento de olhar – sistemas onde cada membro da plateia (que pode, por sua vez, eventualmente ter que falar), é submetido a rastreamento ocular como um índice de engajamento e aprovação.
Todos esses métodos são bastante de alta fricção. Muitos deles exigem equipamentos adicionais ou software complexo que pode levantar questões de privacidade ou logísticas – estilos de abordagem relativamente de alto custo ou de outra forma limitados por recursos. Portanto, o desenvolvimento de sistemas minimalistas baseados em pouco mais do que ferramentas comuns para videoconferência se tornou de interesse nos últimos 18 meses.
Relatando Aprovação da Plateia Discretamente
Para esse fim, uma nova colaboração de pesquisa entre a Universidade de Tóquio e a Universidade Carnegie Mellon oferece um sistema novo que pode se aproveitar de ferramentas padrão de videoconferência (como o Zoom) usando apenas um site habilitado para webcam em que o software de estimativa de pose e olhar leve está em execução. Dessa forma, até mesmo a necessidade de plugins de navegador local é evitada.
Os acenos e a atenção estimada do usuário são traduzidos em dados representativos que são visualizados de volta ao falante, permitindo um ‘teste de litmus ao vivo’ da extensão com que o conteúdo está engajando a plateia – e também, pelo menos, um indicador vago de períodos de discurso onde o falante pode estar perdendo o interesse da plateia.
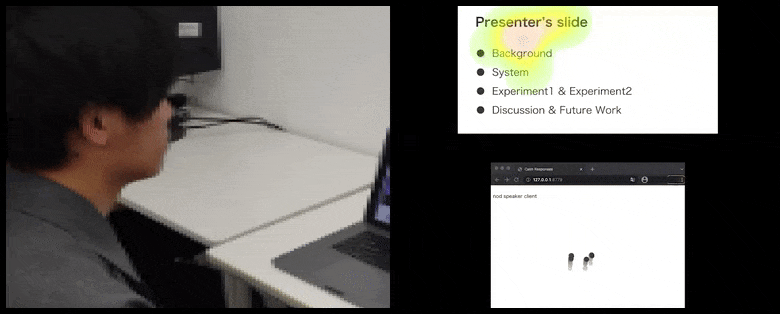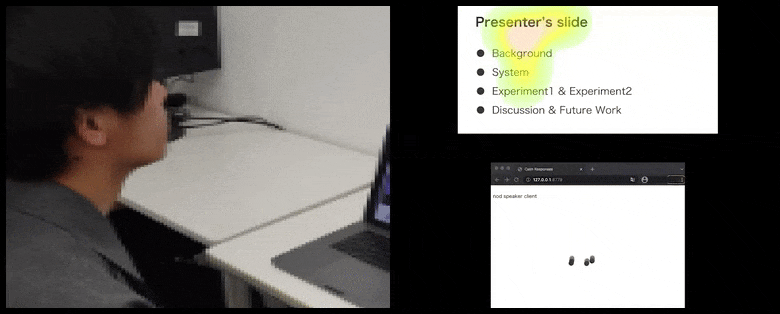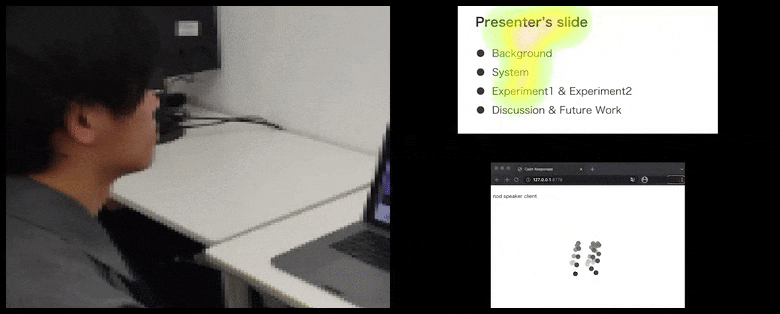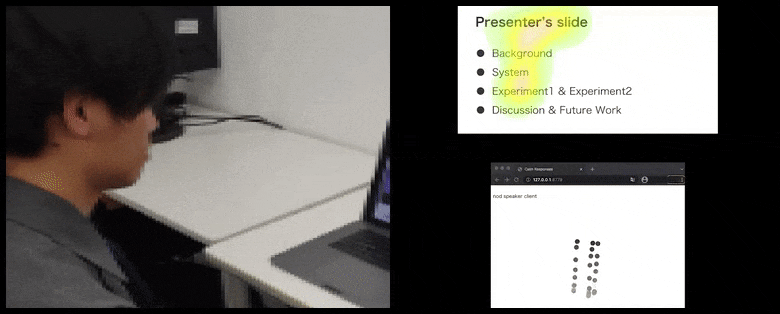
Com CalmResponses, a atenção e os acenos do usuário são adicionados a um pool de feedback da plateia e traduzidos em uma representação visual que pode beneficiar o falante. Veja o vídeo incorporado no final do artigo para mais detalhes e exemplos. Fonte: https://www.youtube.com/watch?v=J_PhB4FCzk0
Em muitas situações acadêmicas, como palestras online, os alunos podem ser completamente invisíveis para o falante, desde que não tenham ativado suas câmeras devido à consciência sobre seu ambiente ou aparência atual. CalmResponses pode abordar esse obstáculo espinhoso para o feedback do falante relatando o que sabe sobre como o falante está olhando para o conteúdo e se está acenando, sem necessidade de o visualizador ativar sua câmera.
O artigo é intitulado CalmResponses: Exibindo Reações Coletivas da Plateia na Comunicação Remota, e é um trabalho conjunto entre dois pesquisadores da UoT e um da Carnegie Mellon.
Os autores oferecem uma demonstração ao vivo na web e liberaram o código-fonte no GitHub.
O Framework CalmResponses
O interesse de CalmResponses em acenos, em oposição a outras disposições possíveis da cabeça, é baseado em pesquisas (algumas delas datando da era de Darwin) que indicam que mais de 80% de todos os movimentos da cabeça dos ouvintes são compostos por acenos (mesmo quando estão expressando desacordo). Ao mesmo tempo, os movimentos do olhar foram mostrados em vários estudos para ser um índice confiável de interesse ou engajamento.
CalmResponses é implementado com HTML, CSS e JavaScript e compreende três subsistemas: um cliente de plateia, um cliente de falante e um servidor. O cliente de plateia passa dados de olhar ou movimento de cabeça do usuário via WebSockets sobre a plataforma de aplicativos em nuvem Heroku.

Acenos da plateia visualizados à direita em um movimento animado sob CalmResponses. Nesse caso, a visualização do movimento está disponível não apenas para o falante, mas para toda a plateia. Fonte: https://arxiv.org/pdf/2204.02308.pdf
Para a seção de rastreamento de olhar do projeto, os pesquisadores usaram WebGazer, um framework de rastreamento de olhar baseado em JavaScript leve e baseado em navegador que pode ser executado com baixa latência diretamente a partir de um site (veja o link acima para a implementação baseada na web dos pesquisadores).
Como a necessidade de implementação simples e reconhecimento de resposta agregada bruta supera a necessidade de alta precisão na estimativa de pose e olhar, os dados de pose de entrada são suavizados de acordo com os valores médios antes de serem considerados para a estimativa de resposta geral.
A ação de aceno é avaliada via a biblioteca JavaScript clmtrackr, que ajusta modelos faciais a faces detectadas em imagens ou vídeos por meio de deslocamento de referência regularizado. Para fins de economia e baixa latência, apenas a marca detectada para o nariz é ativamente monitorada na implementação dos autores, desde que isso é suficiente para acompanhar ações de aceno.
O movimento da ponta do nariz do usuário cria um rastro que contribui para o pool de resposta da plateia relacionada a acenos, visualizado de forma agregada para todos os participantes.
Mapa de Calor
Enquanto a atividade de aceno é representada por pontos dinâmicos em movimento (veja imagens acima e vídeo no final), a atenção visual é relatada em termos de um mapa de calor que mostra ao falante e à plateia onde o foco geral de atenção está concentrado na tela de apresentação compartilhada ou no ambiente de videoconferência.

Todos os participantes podem ver onde a atenção geral do usuário está focada. O artigo não menciona se essa funcionalidade está disponível quando o usuário pode ver uma ‘galeria’ de outros participantes, o que poderia revelar foco espúrio em um participante particular, por vários motivos.
Testes
Dois ambientes de teste foram formulados para CalmResponses na forma de um estudo de ablação tácito, usando três conjuntos variados de circunstâncias: no ‘Condición B’ (base), os autores replicaram uma palestra online típica de estudantes, onde a maioria dos estudantes mantém suas câmeras web desligadas, e o falante não tem a capacidade de ver os rostos da plateia; no ‘Condición CR-E’, o falante podia ver o feedback de olhar (mapas de calor); no ‘Condición CR-N’, o falante podia ver tanto a atividade de aceno quanto a atividade de olhar da plateia.
O primeiro cenário experimental compreendia a condição B e a condição CR-E; o segundo compreendia a condição B e a condição CR-N. O feedback foi obtido de ambos, o falante e a plateia.
Em cada experimento, três fatores foram avaliados: avaliação objetiva e subjetiva da apresentação (incluindo um questionário de auto-relato do falante sobre como a apresentação foi); o número de eventos de ‘discurso de preenchimento’, indicativo de insegurança e hesitação momentânea; e comentários qualitativos. Esses critérios são comuns estimadores de qualidade da fala e ansiedade do falante.
O pool de teste consistia em 38 pessoas com idades entre 19-44, composto por 29 homens e nove mulheres com uma idade média de 24,7, todos japoneses ou chineses e todos fluentes em japonês. Eles foram divididos aleatoriamente em cinco grupos de 6-7 participantes, e nenhum dos sujeitos se conhecia pessoalmente.
Os testes foram realizados no Zoom, com cinco falantes dando apresentações no primeiro experimento e seis no segundo.

Condições de preenchimento marcadas como caixas laranja. Em geral, o conteúdo de preenchimento caiu em proporção razoável ao aumento do feedback da plateia do sistema.
Os pesquisadores observam que o número de preenchimentos de um falante diminuiu notavelmente, e que na ‘Condição CR-N’, o falante raramente pronunciou frases de preenchimento. Veja o artigo para os resultados muito detalhados e granulares relatados; no entanto, os resultados mais marcantes foram na avaliação subjetiva dos falantes e participantes da plateia.
Comentários da plateia incluíram:
‘Eu senti que estava envolvido nas apresentações” [AN2], “Eu não sabia se os discursos dos falantes foram melhorados, mas senti um senso de unidade a partir da visualização dos movimentos de cabeça dos outros.’ [AN6]
‘Eu não sabia se os discursos dos falantes foram melhorados, mas senti um senso de unidade a partir da visualização dos movimentos de cabeça dos outros.’
Os pesquisadores observam que o sistema introduz um novo tipo de pausa artificial na apresentação do falante, desde que o falante está inclinado a se referir ao sistema visual para avaliar o feedback da plateia antes de prosseguir.
Eles também observam um tipo de ‘efeito de jaleco branco’, difícil de evitar em circunstâncias experimentais, onde alguns participantes se sentiram constrangidos pelas possíveis implicações de segurança de serem monitorados para dados biométricos.
Conclusão
Uma vantagem notável em um sistema como este é que todas as tecnologias acessórias não padrão necessárias para essa abordagem desaparecem completamente após seu uso. Não há plugins de navegador residuais para serem desinstalados, ou para lançar dúvidas na mente dos participantes sobre se devem permanecer em seus respectivos sistemas; e não há necessidade de orientar os usuários pelo processo de instalação (embora o framework baseado na web exija um minuto ou dois de calibração inicial pelo usuário), ou de navegar a possibilidade de os usuários não terem permissões adequadas para instalar software local, incluindo add-ons e extensões baseados em navegador.
Embora os movimentos faciais e oculares avaliados não sejam tão precisos quanto poderiam ser em circunstâncias em que frameworks de aprendizado de máquina dedicados (como a série YOLO) poderiam ser usados, essa abordagem quase sem atrito para a avaliação da plateia fornece precisão adequada para análise de sentimento e postura ampla em cenários típicos de videoconferência. Acima de tudo, é muito barato.
Confira o vídeo do projeto associado abaixo para mais detalhes e exemplos.
Publicado pela primeira vez em 11 de abril de 2022.












