
Artificial Intelligence
Rozwiązywanie problemu artefaktów JPEG w zbiorach danych obrazu komputerowego
Nowe badanie przeprowadzone na Uniwersytecie Maryland i sztucznej inteligencji Facebooka wykazało „znaczny spadek wydajności” systemów głębokiego uczenia, które wykorzystują w swoich zbiorach danych wysoce skompresowane obrazy JPEG, a także oferuje nowe metody łagodzenia skutków tego zjawiska.
Połączenia raport, pod tytulem Analizowanie i łagodzenie defektów kompresji JPEG w głębokim uczeniu się, twierdzi, że jest „znacznie bardziej kompleksowy” niż poprzednie badania nad wpływem artefaktów na szkoleniowe zbiory danych widzenia komputerowego. W artykule stwierdzono, że „[intensywna] lub umiarkowana kompresja JPEG powoduje znaczny spadek wydajności w przypadku standardowych wskaźników” oraz że sieci neuronowe być może nie są tak odporne na takie zakłócenia jak poprzednie prace wskazuje.

Zdjęcie psa ze zbioru danych MobileNetV2018 2. Przy jakości 10 (po lewej) system klasyfikacji nie identyfikuje właściwej rasy „Pembroke Welsh Corgi”, zamiast tego zgaduje „Norwich terrier” (system już wie, że to zdjęcie psa, ale nie rasa); druga od lewej: gotowa wersja obrazu w formacie JPEG, poprawiona pod względem artefaktów, ponownie nie pozwala na identyfikację właściwej rasy; druga od prawej, ukierunkowana korekta artefaktów przywraca prawidłową klasyfikację; i po prawej, oryginalne zdjęcie, prawidłowo sklasyfikowane. Źródło: https://arxiv.org/pdf/2011.08932.pdf
Artefakty kompresji jako „dane”
Ekstremalna kompresja JPEG prawdopodobnie utworzy widoczne lub półwidoczne obramowania wokół pliku 8×8 bloki z którego plik JPEG jest składany w siatkę pikseli. Gdy pojawią się te artefakty blokujące lub „dzwoniące”, prawdopodobnie zostaną błędnie zinterpretowane przez systemy uczenia maszynowego jako elementy rzeczywistego świata obiektu obrazu, chyba że zostanie to w jakiś sposób skompensowane.

Powyżej komputerowy system uczenia maszynowego wyodrębnia „czysty” obraz gradientu z obrazu dobrej jakości. Poniżej „blokujące” artefakty w zapisie obrazu o niższej jakości przesłaniają cechy obiektu i mogą „zainfekować” cechy pochodzące ze zbioru obrazów, szczególnie w przypadkach, gdy w zbiorze danych występują obrazy o wysokiej i niskiej jakości , na przykład w kolekcjach zdrapanych z Internetu, w przypadku których zastosowano jedynie ogólne czyszczenie danych. Źródło: http://www.cs.utep.edu/ofuentes/papers/quijasfuentes2014.pdf
Jak widać na pierwszym obrazku powyżej, takie artefakty mogą wpływać na zadania klasyfikacji obrazów, co ma konsekwencje także dla algorytmów rozpoznawania tekstu, które mogą nieprawidłowo identyfikować postacie dotknięte artefaktami.
W przypadku systemów szkoleniowych zajmujących się syntezą obrazów (takich jak oprogramowanie deepfake lub systemy generowania obrazów oparte na GAN) „fałszywy” blok obrazów o niskiej jakości i silnie skompresowanych w zbiorze danych może albo obniżyć średnią jakość reprodukcji, albo zostać uwzględnione i zasadniczo zastąpione przez większą liczbę cech wyższej jakości wyodrębnionych z lepszych obrazów w zestawie. W obu przypadkach pożądane są lepsze dane lub przynajmniej spójne dane.
JPEG – zwykle „wystarczająco dobry”
Kompresja JPEG to nieodwracalnie stratny kodek, który można zastosować do różnych formatów obrazów, chociaż jest stosowany głównie do pliku obrazu JFIF obwoluta. Mimo to nazwa formatu JPEG (.jpg) pochodzi od powiązanej z nim metody kompresji, a nie opakowania JFIF dla danych obrazu.
W ostatnich latach pojawiły się całe architektury uczenia maszynowego, które obejmują łagodzenie artefaktów w stylu JPEG w ramach procedur zwiększania/przywracania opartych na sztucznej inteligencji, a usuwanie artefaktów kompresji w oparciu o sztuczną inteligencję jest obecnie włączone do wielu produktów komercyjnych, takich jak obraz/przywracanie Topaz wideo apartamenti cechy neuronowe najnowszych wersji programu Adobe Photoshop.
Ponieważ 1986 Obecnie powszechnie używany schemat JPEG został w zasadzie zablokowany na początku lat 1990. XX wieku. Nie można dodać do obrazu metadanych, które wskazywałyby, na jakim poziomie jakości (1–100) obraz JPEG został zapisany – przynajmniej bez modyfikacji trzydzieści lat starszych systemów oprogramowania konsumenckiego, profesjonalnego i akademickiego, które nie oczekiwały dostępności takich metadanych.
W związku z tym nierzadko dostosowuje się procedury szkoleniowe w zakresie uczenia maszynowego do ocenionej lub znanej jakości danych obrazów JPEG, tak jak zrobili to naukowcy w przypadku nowego artykułu (patrz poniżej). W przypadku braku wpisu metadanych „jakość” obecnie konieczne jest poznanie szczegółów sposobu kompresji obrazu (tj. skompresowania ze źródła bezstratnego) lub oszacowanie jakości za pomocą algorytmów percepcyjnych lub ręcznej klasyfikacji.
Ekonomiczny kompromis
JPEG nie jest jedyną metodą kompresji stratnej, która może mieć wpływ na jakość zbiorów danych uczenia maszynowego; ustawienia kompresji w plikach PDF również mogą w ten sposób usuwać informacje i ustawiać je na bardzo niski poziom jakości, aby zaoszczędzić miejsce na dysku do celów archiwizacji lokalnej lub sieciowej.
Można się o tym przekonać, próbkując różne pliki PDF z Archive.org, a niektóre z nich zostały skompresowane tak mocno, że stanowią znaczące wyzwanie dla systemów rozpoznawania obrazów lub tekstu. W wielu przypadkach, np. w przypadku książek chronionych prawem autorskim, wydaje się, że ta intensywna kompresja została zastosowana jako forma taniego DRM, w podobny sposób, w jaki właściciele praw autorskich mogą zdecydować się na obniżenie rozdzielczości filmów wideo YouTube przesyłanych przez użytkowników, do których posiadają adres IP, pozostawianie „blokowych” filmów jako żetonów promocyjnych, aby zainspirować do zakupów w „pełnej rozdzielczości”, zamiast ich usuwania.
W wielu innych przypadkach rozdzielczość lub jakość obrazu jest niska po prostu dlatego, że dane są bardzo stare i pochodzą z epoki, gdy pamięć lokalna i sieciowa była droższa, a ograniczone prędkości sieci faworyzowały wysoce zoptymalizowane i przenośne obrazy zamiast reprodukcji wysokiej jakości .
Twierdzono, że JPEG nie jest najlepszym rozwiązaniem już dziś, został „zapisany” jako nieusuwalna, starsza infrastruktura, która jest zasadniczo powiązana z podstawami Internetu.
Obciążenie dziedzictwa
Chociaż późniejsze innowacje, takie jak JPEG 2000, PNG i (ostatni) format .webp zapewniają najwyższą jakość, ponowne próbkowanie starszych, bardzo popularnych zbiorów danych uczenia maszynowego prawdopodobnie „zresetowałoby” ciągłość i historię wyzwań związanych z wizją komputerową z roku na rok w środowisku akademickim – utrudnienie, które występowałoby także w przypadku ponownego zapisywania obrazów PNG w wyższych ustawieniach jakości. Można to uznać za rodzaj długu technicznego.
Chociaż szanowane serwerowe biblioteki do przetwarzania obrazów, takie jak ImageMagick, obsługują lepsze formaty, w tym .webp, wymagania dotyczące transformacji obrazów często występują w starszych systemach, które nie są skonfigurowane do niczego innego niż JPG lub PNG (które oferują bezstratną kompresję, ale kosztem opóźnienia i miejsce na dysku). Nawet WordPress, zasilanie CMS prawie 40% wszystkich stron internetowych, dodano tylko obsługę .webp trzy miesiące temu.
PNG był późnym (prawdopodobnie zbyt późnym) wejściem w sektor formatów obrazów, powstałym jako rozwiązanie open source w drugiej połowie lat 1990. deklarację z 1995 r przez Unisys i CompuServe, że odtąd pobierane będą opłaty licencyjne za format kompresji LZW używany w plikach GIF, które były wówczas powszechnie używane w przypadku logo i elementów o jednolitym kolorze, nawet jeśli format ten wskrzeszenie na początku 2010 roku skupiał się na możliwości dostarczania atrakcyjnych animowanych treści o niskiej przepustowości (jak na ironię, animowane pliki PNG nigdy nie zyskały popularności ani szerokiego wsparcia, a nawet były zakazane na Twitterze w 2019).
Pomimo swoich wad kompresja JPEG jest szybka, zajmuje mało miejsca i jest głęboko osadzona w systemach wszelkiego typu, dlatego też prawdopodobnie w najbliższej przyszłości nie zniknie całkowicie ze sceny uczenia maszynowego.
Jak najlepiej wykorzystać odprężenie AI/JPEG
W pewnym stopniu społeczność uczących się maszyn przyzwyczaiła się do wad kompresji JPEG: w 2011 roku Europejskie Towarzystwo Radiologiczne (ESR) opublikowało „The Puzzle of Monogamous Marriage” w sprawie „Przydatności nieodwracalnej kompresji obrazu w obrazowaniu radiologicznym”, zawierający wytyczne dotyczące „akceptowalnych” strat; kiedy czcigodny MNIST zbiór danych do rozpoznawania tekstu (którego dane obrazu były pierwotnie dostarczane w nowatorskim formacie binarnym) został przeniesiony do „zwykłego” formatu obrazu, JPEG, a nie PNG, został wybrany; oraz wcześniejsza (2020) współpraca autorów nowego artykułu „nowa architektura” do kalibracji systemów uczenia maszynowego pod kątem niedociągnięć związanych z różną jakością obrazu JPEG, bez konieczności uczenia modeli przy każdym ustawieniu jakości JPEG – jest to funkcja wykorzystana w nowej pracy.
Rzeczywiście badania nad użytecznością danych JPEG o różnej jakości są stosunkowo dobrze prosperującą dziedziną uczenia maszynowego. Właściwie jeden (niepowiązany) projekt z 2016 roku z Centrum Badań nad Automatyką na Uniwersytecie Maryland koncentruje się na domenie DCT (gdzie artefakty JPEG pojawiają się przy niskich ustawieniach jakości) jako sposób na głęboką ekstrakcję obiektów; koncentruje się kolejny projekt z 2019 roku odczyt na poziomie bajtów danych JPEG bez czasochłonnej konieczności faktycznej dekompresji obrazów (tzn. otwierania ich w pewnym momencie w zautomatyzowanym procesie); i a „The Puzzle of Monogamous Marriage” z Francji w 2019 r. aktywnie wykorzystuje kompresję JPEG w procedurach rozpoznawania obiektów.
Testowanie i wnioski
Wracając do najnowszego badania przeprowadzonego przez UoM i Facebooka, badacze starali się przetestować zrozumiałość i użyteczność formatu JPEG na obrazach skompresowanych w zakresie 10–90 (poniżej którego obraz jest niemożliwie zakłócony, a powyżej którego jest równy kompresji bezstratnej). Obrazy użyte w testach zostały wstępnie skompresowane do każdej wartości w docelowym zakresie jakości, co wymagało co najmniej ośmiu sesji treningowych.
Modele szkolono w zakresie stochastycznego opadania gradientowego za pomocą czterech metod: bazowy, gdzie nie dodano żadnych dodatkowych środków łagodzących; nadzorowane dostrajanie, gdzie zaletą zestawu szkoleniowego są wstępnie wytrenowane wagi i oznakowane dane (chociaż badacze przyznają, że trudno jest to odtworzyć w zastosowaniach na poziomie konsumenckim); korekta artefaktów, gdzie przed treningiem przeprowadza się wzmocnienie/poprawę na skompresowanych obrazach; I korekta artefaktów ukierunkowana na zadanie, gdzie sieć poprawna z artefaktami jest dostrajana na podstawie zwracanych błędów.
Szkolenie odbyło się na szerokiej gamie trafnych zbiorów danych, w tym na wielu wariantach ResNet, SzybkiRCNN, MobileNetV2, MaskaRCNN i Kerasa PoczątekV3.
Wyniki utraty próbek po korekcji artefaktów ukierunkowanej na zadanie są wizualizowane poniżej (niżej = lepiej).
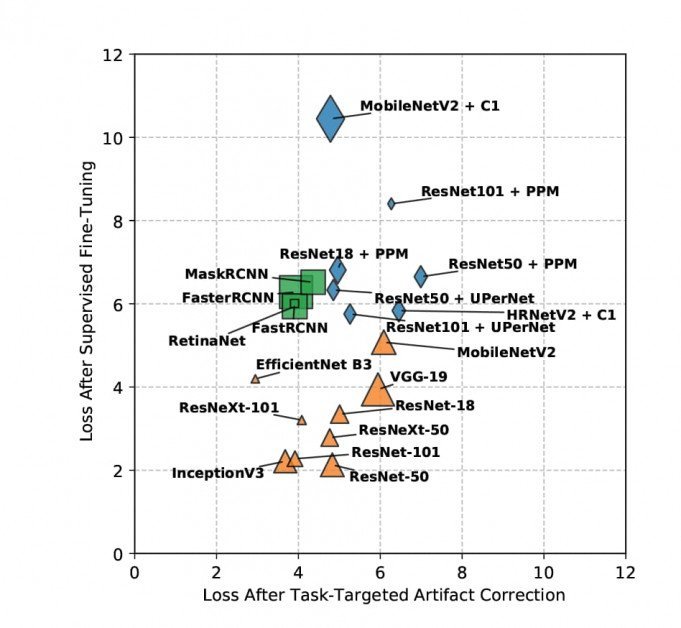
Nie można zagłębiać się w szczegóły wyników uzyskanych w badaniu, ponieważ ustalenia badaczy dzielą się pomiędzy cel, jakim jest ocena artefaktów JPEG, a nowe metody łagodzenia tego problemu; szkolenie zostało powtórzone według jakości na tak wielu zbiorach danych; a zadania obejmowały wiele celów, takich jak wykrywanie obiektów, segmentacja i klasyfikacja. Zasadniczo nowy raport jawi się jako kompleksowe dzieło referencyjne dotyczące wielu zagadnień.
Niemniej jednak w artykule ogólnie stwierdza się, że „kompresja JPEG wiąże się z poważnymi karami w przypadku ustawień kompresji o wysokim lub umiarkowanym poziomie”. Twierdzi również, że jej nowatorskie, nieoznakowane strategie łagodzenia skutków osiągają lepsze wyniki niż inne podobne podejścia; że w przypadku złożonych zadań metoda nadzorowana przez badaczy również przewyższa inne metody, pomimo braku dostępu do etykiet prawdy; oraz że te nowatorskie metodologie umożliwiają ponowne wykorzystanie modelu, ponieważ uzyskane wagi można przenosić między zadaniami.
Jeśli chodzi o zadania klasyfikacyjne, w artykule wyraźnie stwierdzono, że „JPEG pogarsza jakość gradientu, a także powoduje błędy lokalizacyjne”.
Autorzy mają nadzieję rozszerzyć przyszłe badania na inne metody kompresji, takie jak te w dużej mierze pomijane JPEG 2000, a także WebP, HEIF i BPG. Sugerują ponadto, że ich metodologię można zastosować do analogicznych badań nad algorytmami kompresji wideo.
Ponieważ metoda korekcji artefaktów ukierunkowanych na zadania okazała się tak skuteczna w badaniu, autorzy sygnalizują również zamiar uwolnienia wag wyszkolonych w trakcie projektu, spodziewając się, że „[wiele] zastosowań odniesie korzyści ze stosowania naszych wag TTAC bez modyfikacji”.
nb Zdjęcie źródłowe artykułu pochodzi z thispersondoesnotexist.com













