Możliwość generowania cyfrowych aktywów 3D z podpowiedziami tekstowymi reprezentuje jeden z najbardziej ekscytujących niedawnych rozwojów w dziedzinie sztucznej inteligencji i grafiki komputerowej. Ponieważ rynek cyfrowych aktywów 3D ma się rozrosnąć z 28,3 miliarda dolarów w 2024 roku do 51,8 miliarda dolarów do 2029 roku, modele AI do generowania 3D z tekstu są gotowe odegrać znaczącą rolę w rewolucjonizowaniu tworzenia treści w branżach takich jak gry, filmy, handel elektroniczny i wiele innych. Ale jak dokładnie działają te systemy AI? W tym artykule dokonamy szczegółowego przeanalizowania technicznych szczegółów za generowaniem 3D z tekstu.
Wyzwanie generacji 3D
Generowanie aktywów 3D z tekstu jest znacznie bardziej złożonym zadaniem niż generowanie obrazów 2D. Podczas gdy obrazy 2D są podstawowo siatkami pikseli, aktywa 3D wymagają reprezentowania geometrii, tekstur, materiałów i często animacji w trójwymiarowej przestrzeni. Ta dodatkowa wymiarowość i złożoność sprawia, że zadanie generacji jest znacznie bardziej wymagające.
Niektóre kluczowe wyzwania w generowaniu 3D z tekstu obejmują:
Reprezentowanie geometrii i struktury 3D
Generowanie spójnych tekstur i materiałów na powierzchni 3D
Zapewnienie fizycznej prawdopodobieństwa i spójności z wielu punktów widzenia
Uchwycenie drobnych szczegółów i globalnej struktury jednocześnie
Generowanie aktywów, które mogą być łatwo renderowane lub drukowane w 3D
Aby pokonać te wyzwania, modele generujące 3D z tekstu wykorzystują kilka kluczowych technologii i technik.
Kluczowe składniki systemów generujących 3D z tekstu
Większość najnowocześniejszych systemów generujących 3D z tekstu dzieli kilka podstawowych składników:
Kodowanie tekstu: Konwersja wejściowej podpowiedzi tekstowej na reprezentację numeryczną
Reprezentacja 3D: Metoda reprezentowania geometrii i wyglądu 3D
Model generatywny: Podstawowy model AI generujący aktywa 3D
Renderowanie: Konwersja reprezentacji 3D na obrazy 2D do wizualizacji
Przeanalizujmy każdy z nich bardziej szczegółowo.
Kodowanie tekstu
Pierwszym krokiem jest konwersja wejściowej podpowiedzi tekstowej na reprezentację numeryczną, z którą może pracować model AI. Zazwyczaj wykonuje się to przy użyciu dużych modeli językowych, takich jak BERT lub GPT.
Reprezentacja 3D
Istnieje kilka powszechnych sposobów reprezentowania geometrii 3D w modelach AI:
Siątka voxel: 3-wymiarowe tablice wartości reprezentujących zajętość lub cechy
Chmura punktów: Zbiory punktów 3D
Siątka: Wierzchołki i twarze definiujące powierzchnię
Funkcje implicite: Ciągłe funkcje definiujące powierzchnię (np. funkcje odległości podpisane)
Każdy z nich ma kompromis pomiędzy rozdzielczością, użyciem pamięci i łatwością generacji. Wiele modeli wykorzystuje funkcje implicite lub NeRF, ponieważ umożliwiają one uzyskanie wyników wysokiej jakości przy rozsądnym zużyciu obliczeniowym.
Na przykład możemy reprezentować prostą sferyczną jako funkcję odległości podpisanej:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluate SDF at a 3D point
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance to sphere surface: {distance}")
Model generatywny
Rdzeniem systemu generującego 3D z tekstu jest model generatywny, który produkuje reprezentację 3D z osadzaniem tekstu. Większość modeli wykorzystuje pewną wariację modelu dyfuzyjnego, podobnego do tych używanych w generowaniu obrazów 2D.
Modele dyfuzyjne działają przez stopniowe dodawanie szumu do danych, a następnie uczą się odwracać ten proces. W przypadku generacji 3D proces ten zachodzi w przestrzeni wybranej reprezentacji 3D.
Uproszczony pseudokod dla kroku szkolenia modelu dyfuzyjnego mógłby wyglądać jak poniżej:
def diffusion_training_step(model, x_0, text_embedding):
# Sample a random timestep
t = torch.randint(0, num_timesteps, (1,))
# Add noise to the input
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Predict the noise
predicted_noise = model(x_t, t, text_embedding)
# Compute loss
loss = F.mse_loss(noise, predicted_noise)
return loss
# Training loop
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
Podczas generacji zaczynamy od czystego szumu i iteracyjnie go usuwamy, warunkując na osadzaniu tekstu.
Renderowanie
Aby wizualizować wyniki i obliczać straty podczas szkolenia, musimy renderować naszą reprezentację 3D do obrazów 2D. Zazwyczaj wykonuje się to przy użyciu różniczkowalnych technik renderowania, które pozwalają na przepływ gradientów z powrotem przez proces renderowania.
Dla reprezentacji opartych na siatkach możemy użyć renderera opartego na rastrowaniu:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Set up camera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Example usage
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
Dla reprezentacji implicitej, takich jak NeRF, zwykle używamy technik marszowania promieni do renderowania widoków.
Łącząc wszystko: Potok generacji 3D z tekstu
Teraz, gdy omówiliśmy kluczowe składniki, przejdźmy przez to, jak łączą się one w typowym potoku generacji 3D z tekstu:
Kodowanie tekstu: Wejściowa podpowiedź jest zakodowana w gęstą reprezentację wektorową przy użyciu modelu językowego.
Początkowa generacja: Model dyfuzyjny, warunkowany na osadzaniu tekstu, generuje początkową reprezentację 3D (np. NeRF lub funkcję implicite).
Spójność wielowidokowa: Model renderuje wiele widoków wygenerowanego aktywa 3D i zapewnia spójność pomiędzy punktami widzenia.
Udoskonalenie: Dodatkowe sieci mogą udoskonalić geometrię, dodać tekstury lub poprawić szczegóły.
Wynik końcowy: Reprezentacja 3D jest konwertowana do pożądanego formatu (np. siatki z teksturami) do użycia w dalszych aplikacjach.
Oto uproszczony przykład, jak to mogłoby wyglądać w kodzie:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode text
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Generate initial 3D representation
initial_3d = self.diffusion_model(text_embedding)
# Render multiple views
views = self.renderer(initial_3d, num_views=4)
# Refine based on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Usage
model = TextTo3D()
text_prompt = "A red sports car"
generated_3d = model(text_prompt)
Najlepsze dostępne modele aktywów 3D z tekstu
3DGen – Meta
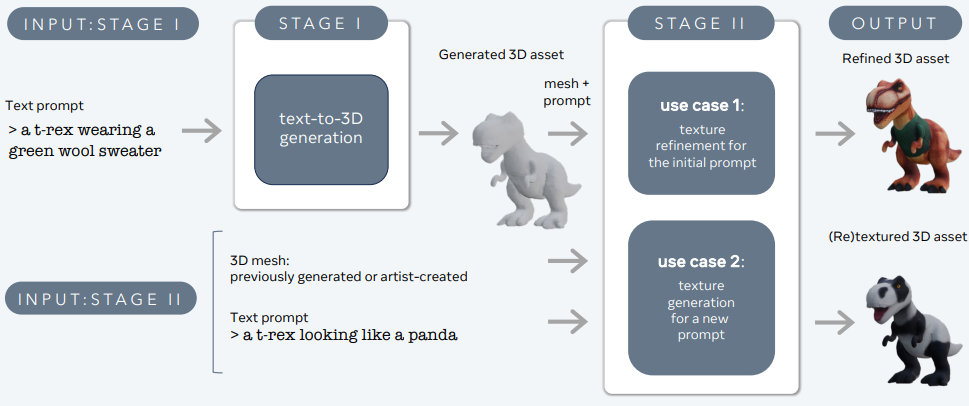
3DGen jest zaprojektowany, aby rozwiązać problem generowania treści 3D — takich jak postacie, rekwizyty i sceny — z opisów tekstowych.
3DGen obsługuje renderowanie oparte na fizyce (PBR), niezbędne do realistycznego oświetlenia aktywów 3D w aplikacjach świata rzeczywistego. Umożliwia również generatywne ponowne teksturyzowanie wcześniej wygenerowanych lub stworzonych przez artystów kształtów 3D przy użyciu nowych wejść tekstowych. Potok integruje dwa podstawowe składniki: Meta 3D AssetGen i Meta 3D TextureGen, które obsługują generowanie 3D z tekstu i generowanie tekstur, odpowiednio.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) jest odpowiedzialny za początkową generację aktywów 3D z podpowiedziami tekstowymi. Ten składnik produkuje siatkę 3D z teksturami i mapami materiałów PBR w ciągu około 30 sekund.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) udoskonala tekstury wygenerowane przez AssetGen. Może również generować nowe tekstury dla istniejących siatek 3D na podstawie dodatkowych opisów tekstowych. Ten etap trwa około 20 sekund.
Point-E (OpenAI)
Point-E, opracowany przez OpenAI, jest kolejnym godnym uwagi modelem generującym 3D z tekstu. W przeciwieństwie do DreamFusion, który produkuje reprezentacje NeRF, Point-E generuje chmury punktów 3D.
Kluczowe cechy Point-E:
a) Dwuetapowy potok: Point-E najpierw generuje syntetyczny widok 2D przy użyciu modelu dyfuzyjnego 2D z tekstu, a następnie używa tego obrazu do warunkowania drugiego modelu dyfuzyjnego, który produkuje chmurę punktów 3D.
b) Wydajność: Point-E jest zaprojektowany, aby być obliczeniowo wydajny, zdolny do generowania chmur punktów 3D w ciągu kilku sekund na jednej karcie graficznej.
c) Informacja koloru: Model może generować chmury punktów w kolorze, zachowując zarówno geometryczne, jak i informacje o wyglądzie.
Ograniczenia:
Niższa jakość w porównaniu z podejściami opartymi na siatkach lub NeRF
Chmury punktów wymagają dodatkowej obróbki dla wielu aplikacji
Shap-E (OpenAI):
Budując na Point-E, OpenAI wprowadził Shap-E, który generuje siatki 3D zamiast chmur punktów. To rozwiązuje niektóre z ograniczeń Point-E, jednocześnie utrzymując wydajność obliczeniową.
Kluczowe cechy Shap-E:
a) Reprezentacja implicite: Shap-E uczy się generować reprezentacje implicite (funkcje odległości podpisane) obiektów 3D.
b) Ekstrakcja siatki: Model używa różniczkowalnej implementacji algorytmu marching cubes, aby przekonwertować reprezentację implicite w siatkę wielokątów.
c) Generowanie tekstur: Shap-E może również generować tekstury dla siatek 3D, prowadząc do bardziej atrakcyjnych wizualnie wyników.
Przewagi:
Szybkie czasy generacji (sekundy do minut)
Bezpośredni wynik siatki odpowiedni do renderowania i dalszych aplikacji
Możliwość generowania zarówno geometrii, jak i tekstur
GET3D (NVIDIA):
GET3D, opracowany przez badaczy NVIDIA, jest kolejnym potężnym modelem generującym 3D z tekstu, który koncentruje się na wytwarzaniu wysokiej jakości siatek 3D z teksturami.
Kluczowe cechy GET3D:
a) Wyraźna reprezentacja powierzchni: W przeciwieństwie do DreamFusion lub Shap-E, GET3D bezpośrednio generuje wyraźne reprezentacje powierzchni (siatki) bez pośrednich reprezentacji implicite.
b) Generowanie tekstur: Model obejmuje różniczkowalną technikę renderowania, aby nauczyć się i wygenerować wysokiej jakości tekstury dla siatek 3D.
c) Architektura oparta na GAN: GET3D wykorzystuje podejście sieci generatywnej przeciwnej (GAN), co pozwala na szybką generację po przeszkoleniu modelu.
Przewagi:
Wysoka jakość geometrii i tekstur
Szybkie czasy inferencji
Bezpośrednia integracja z silnikami renderowania 3D
Ograniczenia:
Wymaga danych szkoleniowych 3D, które mogą być rzadkie dla niektórych kategorii obiektów
Podsumowanie
Generacja 3D z tekstu za pomocą sztucznej inteligencji reprezentuje fundamentalną zmianę w tym, jak tworzymy i wchodzimy w interakcje z treściami 3D. Wykorzystując zaawansowane techniki głębokiego uczenia, te modele mogą produkować złożone, wysokiej jakości aktywa 3D z prostych opisów tekstowych. Wraz z dalszym rozwojem tej technologii możemy oczekiwać coraz bardziej zaawansowanych i zdolnych systemów generujących 3D z tekstu, które rewolucjonizują branże od gier i filmów po projektowanie produktów i architekturę.
Spędziłem ostatnie pięć lat, zanurzając się w fascynującym świecie Machine Learning i Deep Learning. Moja pasja i ekspertyza doprowadziły mnie do udziału w ponad 50 różnych projektach inżynierii oprogramowania, ze szczególnym uwzględnieniem AI/ML. Moja nieustanna ciekawość również skierowała mnie w stronę Natural Language Processing, dziedziny, którą chcę bardziej zbadać.