Sztuczna inteligencja
Tworzenie obrazów satelitarnych z map wektorowych

Naukowcy z Wielkiej Brytanii opracowali oparty na sztucznej inteligencji system syntezy obrazów, który może w locie konwertować mapy wektorowe na obrazy w stylu satelitarnym. Architektura neuronowa nosi nazwę Seamless Satellite-image Synthesis (SSS) i oferuje perspektywę realistycznych środowisk wirtualnych oraz rozwiązań nawigacyjnych, które mają lepszą rozdzielczość niż obrazy satelitarne; są bardziej aktualne (ponieważ systemy map kartograficznych można aktualizować na żywo); oraz mogą umożliwiać realistyczne widoki w stylu orbitalnym na obszarach, gdzie rozdzielczość czujników satelitarnych jest ograniczona lub niedostępna.

Dane wektorowe niezależne od rozdzielczości można przetłumaczyć na znacznie większe rozmiary obrazów niż te często dostępne z rzeczywistych obrazów satelitarnych i mogą szybko odzwierciedlać aktualizacje w sieciowych mapach kartograficznych, takie jak nowe przeszkody lub zmiany w infrastrukturze sieci drogowej. Źródło: https://arxiv.org/pdf/2111.03384.pdf
Aby zademonstrować możliwości systemu, naukowcy stworzyli interaktywne środowisko w stylu Google Earth, w którym widz może przybliżać i obserwować generowane obrazy satelitarne w różnych skalach renderowania i szczegółowości, z kafelkami aktualizowanymi na żywo w sposób bardzo podobny do konwencjonalnych systemów interaktywnych dla obrazów satelitarnych:
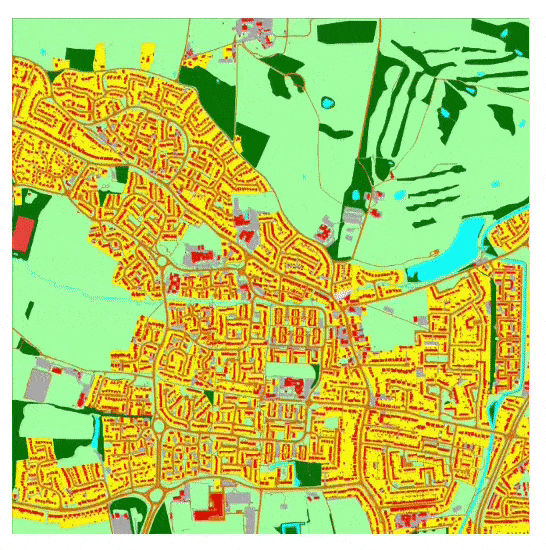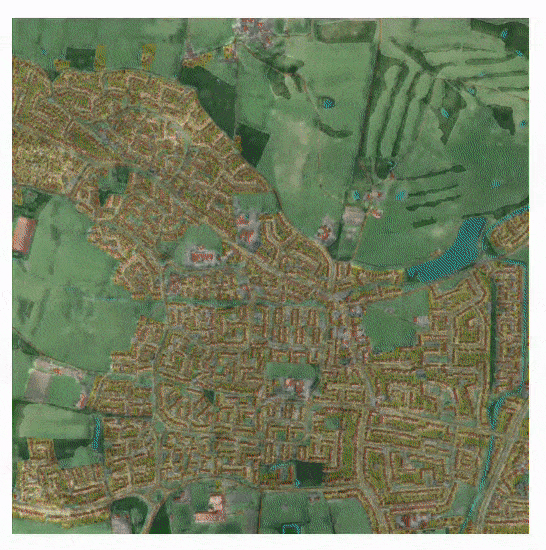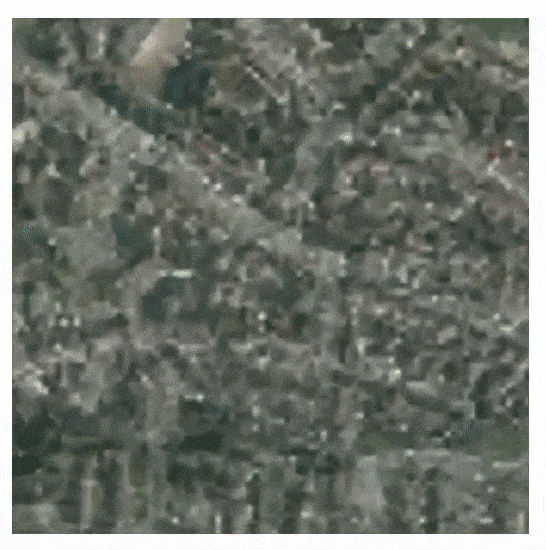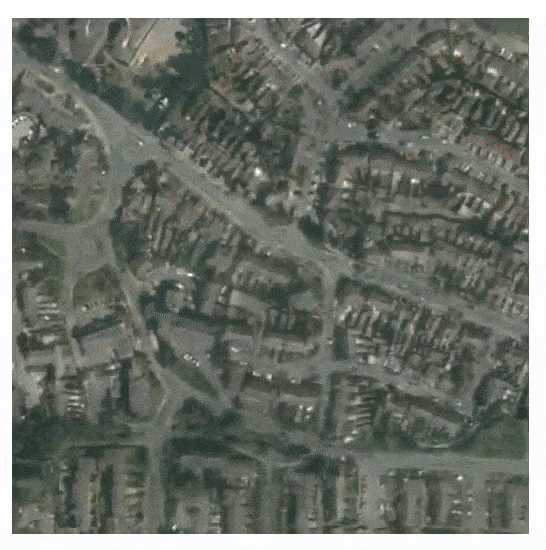
Przybliżanie stworzonego środowiska, opartego na mapie kartograficznej. Zobacz film na końcu artykułu, aby uzyskać lepszą rozdzielczość i więcej szczegółów na temat procesu. Źródło: Ponadto, ponieważ system może generować obrazy w stylu satelitarnym z dowolnej mapy wektorowej, teoretycznie można go wykorzystać do budowania historycznych, prognozowanych lub fikcyjnych światów, do włączenia do symulatorów lotu i środowisk wirtualnych. Dodatkowo, naukowcy przewidują syntezę w pełni trójwymiarowych środowisk wirtualnych z danych kartograficznych przy użyciu transformerów. W bliższej perspektywie autorzy uważają, że ich framework może być wykorzystany do wielu praktycznych zastosowań, w tym interaktywnego planowania miast i modelowania proceduralnego, wyobrażając sobie scenariusz, w którym zainteresowane strony mogą edytować mapę interaktywnie i widzieć obrazy z lotu ptaka prognozowanego terenu w ciągu kilku sekund. Nowy artykuł pochodzi od dwóch badaczy z University of Leeds i nosi tytuł Seamless Satellite-image Synthesis. [caption id="attachment_178565" align="alignnone" width="1200"]
Architektura i źródłowe dane treningowe
Nowy system wykorzystuje architekturę syntezy obrazów Pix2Pix z UCL Berkeley z 2017 roku oraz SPADE firmy NVIDIA. Framework zawiera dwie nowatorskie konwolucyjne sieci neuronowe – map2sat, która wykonuje konwersję z wektorów na obrazy pikselowe; oraz seam2cont, która nie tylko oblicza bezszwową metodę łączenia kafelków 256×256, ale także zapewnia interaktywne środowisko eksploracji.

Architektura SSS.
System uczy się syntetyzować widoki satelitarne, trenując na widokach wektorowych i ich rzeczywistych odpowiednikach satelitarnych, tworząc uogólnione zrozumienie, jak interpretować aspekty wektorowe na fotorealistyczne interpretacje. Obrazy wektorowe użyte w zbiorze danych są rasteryzowane z plików GeoPackage (.geo), które zawierają do 13 etykiet klas, takich jak ścieżka, środowisko naturalne, budynek i droga, które są wykorzystywane przy decydowaniu, jaki rodzaj obrazu umieścić w widoku satelitarnym. Zrasteryzowane obrazy satelitarne .geo również zachowują metadane lokalnego systemu odniesień przestrzennych (CRS), które są używane do interpretowania ich w kontekście szerszej struktury mapy oraz umożliwienia użytkownikowi interaktywnej nawigacji po stworzonych mapach.
Bezszwowe kafelki pod twardymi ograniczeniami
Tworzenie eksplorowalnych środowisk mapowych jest wyzwaniem, ponieważ ograniczenia sprzętowe w projekcie ograniczają kafelki do rozmiaru zaledwie 256 x 256 pikseli. Dlatego ważne jest, aby proces renderowania lub kompozycji brał pod uwagę “szerszy obraz”, zamiast koncentrować się wyłącznie na aktualnym kafelku, co prowadziłoby do rażących zestawień przy zestawianiu kafelków, z drogami nagle zmieniającymi kolor i innymi nierealistycznymi artefaktami renderowania. Dlatego SSS wykorzystuje hierarchię sieci generatorów w przestrzeni skal do generowania różnorodności treści w różnych skalach, a system jest w stanie dowolnie oceniać kafelki w dowolnej skali pośredniej, której może potrzebować widz. Sekcja seam2cont architektury wykorzystuje dwa nakładające się i niezależne warstwy wyjścia map2sat i oblicza odpowiednią granicę w kontekście szerszego obrazu do przedstawienia:

Moduł seam2cont wykorzystuje jeden obraz z szwem kafelkowym i jeden bez szwów z sieci map2sat, aby obliczyć bezszwowe granice między wygenerowanymi kafelkami 256×256 pikseli.
Sieć map2sat jest zoptymalizowaną adaptacją pełnoprawnej sieci SPADE, wyłącznie wytrenowaną na 256×256 pikselach. Autorzy zauważają, że jest to lekka i zwrotna implementacja, prowadząca do wag wynoszących zaledwie 31,5 MB w porównaniu do 436,9 MB w pełnej sieci SPADE. Do wytrenowania dwóch podsieci wykorzystano 3000 rzeczywistych obrazów satelitarnych w ciągu 70 epok czasu treningu; wszystkie obrazy zawierają równoważne informacje semantyczne (tj. niskopoziomowe koncepcyjne zrozumienie przedstawionych obiektów, takich jak ‘drogi’) oraz metadane pozycjonowania oparte na geolokalizacji. Dalsze materiały są dostępne na stronie projektu, a także towarzyszący film (osadzony poniżej).












