
Artificial Intelligence
Tworzenie modelu językowego w stylu GPT dla pojedynczego pytania

Naukowcy z Chin opracowali ekonomiczną metodę tworzenia systemów przetwarzania języka naturalnego w stylu GPT-3, unikając jednocześnie coraz bardziej zaporowych nakładów czasu i pieniędzy związanych ze szkoleniem dużych zbiorów danych – tendencja rosnąca, która w przeciwnym razie grozi ostatecznym spadkiem tego sektora sztucznej inteligencji dla graczy FAANG i inwestorów wysokiego szczebla.
Proponowane ramy nazywają się Modelowanie języka sterowane zadaniami (TLM). Zamiast trenować ogromny i złożony model na ogromnym zbiorze miliardów słów oraz tysięcy etykiet i klas, TLM zamiast tego szkoli znacznie mniejszy model, który w rzeczywistości zawiera zapytanie bezpośrednio w modelu.

Po lewej: typowe podejście hiperskalowe do modeli językowych o dużej objętości; tak, prosta metoda TLM umożliwiająca eksplorację dużego korpusu językowego według tematu lub pytania. Źródło: https://arxiv.org/pdf/2111.04130.pdf
W efekcie tworzony jest unikalny algorytm lub model NLP, aby odpowiedzieć na pojedyncze pytanie, zamiast tworzyć ogromny i nieporęczny ogólny model językowy, który może odpowiedzieć na szerszą gamę pytań.
Testując TLM, naukowcy odkryli, że nowe podejście pozwala uzyskać wyniki podobne lub lepsze niż w przypadku wstępnie wytrenowanych modeli językowych, takich jak RoBERTa-Largeoraz hiperskalowe systemy NLP, takie jak GPT-3 OpenAI, TRILLION Parameter Switch Transformer firmy Google Model, Korei HyperClover, Laboratoria AI21 jurajski 1i Microsoftu Megatron-Turing NLG 530B.
W próbach TLM na ośmiu zbiorach danych klasyfikacyjnych w czterech domenach autorzy dodatkowo odkryli, że system zmniejsza liczbę FLOPów uczących (operacje zmiennoprzecinkowe na sekundę) wymagane o dwa rzędy wielkości. Badacze mają nadzieję, że TLM może „demokratyzować” sektor, który staje się coraz bardziej elitarny, z modelami NLP tak dużymi, że w rzeczywistości nie da się ich zainstalować lokalnie, zamiast tego, w przypadku GPT-3, stoi za drogi i interfejsy API OpenAI o ograniczonym dostępie oraz, teraz Microsoft Azure.
Autorzy podają, że skrócenie czasu szkolenia o dwa rzędy wielkości zmniejsza koszt szkolenia z ponad 1,000 procesorów graficznych na jeden dzień do zaledwie 8 procesorów graficznych w ciągu 48 godzin.
Nowa raport jest zatytułowany NLP od podstaw bez szkolenia wstępnego na dużą skalę: proste i skuteczne ramyi pochodzi od trzech badaczy z Uniwersytetu Tsinghua w Pekinie oraz badacza z chińskiej firmy zajmującej się rozwojem sztucznej inteligencji Recurrent AI, Inc.
Nieprzystępne odpowiedzi
Połączenia koszt szkolenia skutecznych, uniwersalnych modeli językowych jest coraz częściej określane jako potencjalna „termiczna granica” określająca stopień, w jakim skuteczny i dokładny NLP może naprawdę zostać rozpowszechniony w kulturze.
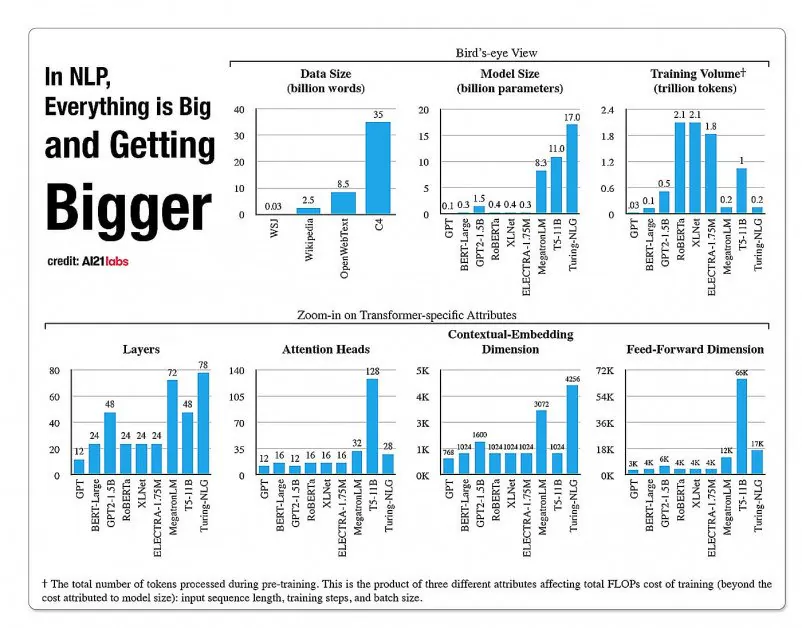
Statystyki dotyczące wzrostu aspektów w architekturach modeli NLP na podstawie raportu A2020 Labs z 121 roku. Źródło: https://arxiv.org/pdf/2004.08900.pdf
W 2019 roku pracownik naukowy obliczony że szkolenie kosztuje 61,440 XNUMX dolarów Model XLNet (wówczas pokonywał BERT w zadaniach NLP) przez 2.5 dnia na 512 rdzeniach na 64 urządzeniach, podczas gdy GPT-3 szacunkowa koszt szkolenia wynosił 12 milionów dolarów – 200 razy więcej niż koszt szkolenia jego poprzednika, GPT-2 (chociaż ostatnie ponowne szacunki mówią, że można go teraz przeszkolić zaledwie 4,600,000 USD na najtańszych procesorach graficznych w chmurze).
Podzbiory danych w oparciu o potrzeby zapytań
Zamiast tego nowa proponowana architektura ma na celu wyprowadzenie dokładnych klasyfikacji, etykiet i uogólnień poprzez wykorzystanie zapytania jako swego rodzaju filtra w celu zdefiniowania podzbioru informacji z dużej językowej bazy danych, które będą szkolone wraz z zapytaniem w celu dostarczenia odpowiedzi na ograniczony temat.
Autorzy stwierdzają:
Motywacją TLM są dwie kluczowe idee. Po pierwsze, ludzie radzą sobie z zadaniem, korzystając jedynie z niewielkiej części światowej wiedzy (np. uczniowie muszą przeczytać tylko kilka rozdziałów spośród wszystkich książek na świecie, aby wkuć się do egzaminu).
„Wystawiamy hipotezę, że w dużym korpusie istnieje duża redundancja w przypadku określonego zadania. Po drugie, szkolenie na nadzorowanych danych oznaczonych etykietami jest znacznie bardziej efektywne pod względem wydajności danych w dalszej części procesu niż optymalizacja celu modelowania języka na danych nieoznaczonych. W oparciu o te motywacje TLM wykorzystuje dane zadań jako zapytania w celu pobrania niewielkiego podzbioru ogólnego korpusu. Następnie następuje wspólna optymalizacja celu nadzorowanego zadania i celu modelowania języka przy użyciu zarówno uzyskanych danych, jak i danych zadania.
Oprócz tego, że wysoce skuteczny trening NLP jest przystępny cenowo, autorzy dostrzegają szereg korzyści płynących ze stosowania modeli NLP zorientowanych na zadania. Po pierwsze, badacze mogą cieszyć się większą elastycznością dzięki niestandardowym strategiom dotyczącym długości sekwencji, tokenizacji, strojenia hiperparametrów i reprezentacji danych.
Naukowcy przewidują także rozwój hybrydowych systemów przyszłości, które pozwolą na kompromis w zakresie ograniczonego wstępnego szkolenia PLM (którego w przeciwnym razie nie przewiduje się w obecnym wdrażaniu) z większą wszechstronnością i uogólnieniem w stosunku do czasu szkolenia. Uważają, że system jest krokiem naprzód w rozwoju wewnętrznych metod generalizacji typu zero-shot.
Testowanie i wyniki
TLM przetestowano pod kątem wyzwań klasyfikacyjnych w ośmiu zadaniach w czterech dziedzinach – nauk biomedycznych, aktualności, recenzji i informatyki. Zadania podzielono na kategorie wysokozasobowe i niskozasobowe. Zadania o dużych zasobach obejmowały ponad 5,000 danych zadań, takich jak AGNews i RCT, pośród innych; uwzględniono zadania wymagające niskich zasobów ChemProt i ACL-ARC, Jak również Hiperpartyzant zbiór danych dotyczących wykrywania wiadomości.
Naukowcy opracowali dwa zestawy szkoleniowe, zatytułowane Corpus-BERT i Corpus-RoBERTa, przy czym ten drugi jest dziesięciokrotnie większy od pierwszego. W eksperymentach porównano ogólne modele wstępnie wyszkolonego języka BERTI (z Google) i ROBERTA (z Facebooka) do nowej architektury.
W artykule zauważono, że chociaż TLM jest metodą ogólną i powinna mieć bardziej ograniczony zakres i zastosowanie niż szersze i masowe, najnowocześniejsze modele, jest w stanie wykonywać metody dostrajania zbliżone do adaptacyjnych w danej dziedzinie.

Wyniki porównania wydajności TLM z zestawami opartymi na BERT i RoBERTa. Wyniki przedstawiają średni wynik F1 w trzech różnych skalach treningowych oraz liczbę parametrów, całkowite obliczenia treningowe (FLOP) i rozmiar korpusu treningowego.
Autorzy doszli do wniosku, że TLM jest w stanie osiągnąć wyniki porównywalne lub lepsze niż PLM, przy znacznej redukcji potrzebnych FLOP i wymagającym jedynie 1/16 korpusu szkoleniowego. W średnich i dużych skalach TLM najwyraźniej może poprawić wydajność średnio o 0.59 i 0.24 punktu, jednocześnie zmniejszając rozmiar danych szkoleniowych o dwa rzędy wielkości.
„Te wyniki potwierdzają, że TLM jest bardzo dokładny i znacznie wydajniejszy niż PLM. Co więcej, TLM zyskuje więcej korzyści w zakresie wydajności na większą skalę. Oznacza to, że PLM działające na większą skalę mogły zostać przeszkolone w zakresie przechowywania bardziej ogólnej wiedzy, która nie jest przydatna w konkretnym zadaniu.















