Sztuczna inteligencja
Kompletny przewodnik po Gemma 2: nowym otwartym dużym modelu językowym Google {question} Odpowiedź: “”” self.qa_prompt = PromptTemplate( template=self.template, input_variables=[“context”, “question”] ) self.qa_chain = RetrievalQA.from_chain_type( llm=self.llm, chain_type=”stuff”, retriever=self.retriever, return_source_documents=True, chain_type_kwargs={“prompt”: self.qa_prompt} ) def query(self, question): return self.qa_chain({“query”: question}) # Użycie rag_system = RAGSystem(vector_store) response = rag_system.query(“Jaka jest stolica Francji?”) print(response[“result”]) [/code] Ten system RAG wykorzystuje Gemmę 2 za pośrednictwem Ollama jako model językowy, a Nomic embeddings do odzyskiwania dokumentów. Pozwala on na zadawanie pytań na podstawie zindeksowanych dokumentów, dostarczając odpowiedzi z kontekstem z odpowiednich źródeł. Dostosowywanie Gemmy 2 Dla określonych zadań lub dziedzin, możesz chcieć dostosować Gemmę 2. Oto podstawowy przykład, wykorzystujący bibliotekę Hugging Face Transformers: Pamiętaj, aby dostosować parametry szkolenia do Twoich konkretnych wymagań i zasobów obliczeniowych. Zagadnienia etyczne i ograniczenia Chociaż Gemma 2 oferuje imponujące możliwości, ważne jest, aby być świadomym jej ograniczeń i zagadnień etycznych: Zaoszczędność: Jak wszystkie modele językowe, Gemma 2 może odzwierciedlać uprzedzenia obecne w danych szkoleniowych. Zawsze krytycznie oceniaj jej dane wyjściowe. Dokładność faktów: Chociaż bardzo zdolna, Gemma 2 może czasem generować niepoprawne lub niespójne informacje. Weryfikuj ważne fakty z wiarygodnych źródeł. Długość kontekstu: Gemma 2 ma długość kontekstu 8192 tokenów. Dla dłuższych dokumentów lub rozmów, możesz potrzebować wdrożyć strategie, aby skutecznie zarządzać kontekstem. Zasoby obliczeniowe: Szczególnie dla modelu 27B, mogą być wymagane znaczne zasoby obliczeniowe, aby zapewnić wydajną inferencję i dostosowywanie. Odpowiedzialne użycie: Przestrzegaj zaleceń Google dotyczących odpowiedzialnego AI i upewnij się, że Twoje użycie Gemmy 2 jest zgodne z etycznymi zasadami AI. Podsumowanie Gemma 2 oferuje zaawansowane funkcje, takie jak mechanizm uwagi z przesunięciem, miękkie ograniczanie i nowatorskie techniki łączenia modeli, co sprawia, że jest potężnym narzędziem dla szerokiego zakresu zadań związanych z przetwarzaniem języka naturalnego. Wykorzystując Gemmę 2 w swoich projektach, niezależnie od tego, czy jest to prosta inferencja, złożony system RAG, czy dostosowany model dla określonej dziedziny, możesz skorzystać z mocy najnowocześniejszego AI, jednocześnie zachowując kontrolę nad swoimi danymi i procesami.

Gemma 2 rozbudowuje swojego poprzednika, oferując zwiększoną wydajność i efektywność, wraz z zestawem innowacyjnych funkcji, które sprawiają, że jest szczególnie atrakcyjna zarówno dla badań, jak i praktycznych zastosowań. To, co wyróżnia Gemmę 2, to jej zdolność do dostarczania wyników porównywalnych z dużo większymi modelami własnościowymi, ale w pakiecie zaprojektowanym dla szerszej dostępności i użycia na mniej wydajnym sprzęcie.
Gdy zagłębiłem się w techniczne specyfikacje i architekturę Gemmy 2, znalazłem się coraz bardziej zadowolony z pomysłowości jej projektu. Model ten wykorzystuje kilka zaawansowanych technik, w tym nowe mechanizmy uwagi i innowacyjne podejścia do stabilności szkolenia, które przyczyniają się do jej niezwykłych możliwości.

Google Open Source LLM Gemma
W tym kompletnym przewodniku, będziemy badać Gemmę 2 w głębi, badając jej architekturę, kluczowe funkcje i praktyczne zastosowania. Niezależnie od tego, czy jesteś doświadczonym praktykiem AI, czy entuzjastycznym nowicjuszem w tej dziedzinie, ten artykuł ma na celu dostarczyć cenne informacje na temat tego, jak Gemma 2 działa i jak możesz wykorzystać jej moc w swoich projektach.
Czym jest Gemma 2?
Gemma 2 to najnowszy otwarty model językowy Google, zaprojektowany, aby być lekkim, a jednocześnie potężnym. Został zbudowany na tej samej technologii, która posłużyła do stworzenia modeli Gemini, oferując najnowocześniejszą wydajność w bardziej dostępnym pakiecie. Gemma 2 jest dostępna w dwóch rozmiarach:
Gemma 2 9B: model o 9 miliardach parametrów
Gemma 2 27B: większy model o 27 miliardach parametrów
Każdy rozmiar jest dostępny w dwóch wariantach:
Modele podstawowe: wstępnie przeszkolone na ogromnym korpusie danych tekstowych
Modele dostosowane do instrukcji (IT): dokształcone w celu lepszej wydajności w określonych zadaniach
Dostęp do modeli w Google AI Studio: Google AI Studio – Gemma 2
Przeczytaj raport techniczny tutaj: Raport techniczny Gemmy 2
Kluczowe funkcje i ulepszenia
Gemma 2 wprowadza kilka znaczących ulepszeń w porównaniu z poprzednią wersją:
1. Zwiększona ilość danych szkoleniowych
Modele zostały przeszkolone na znacznie większej ilości danych:
Gemma 2 27B: przeszkolona na 13 bilionach tokenów
Gemma 2 9B: przeszkolona na 8 bilionach tokenów
To rozszerzone zestawienie danych, składające się głównie z danych sieciowych (głównie w języku angielskim), kodu i matematyki, przyczynia się do poprawy wydajności i wszechstronności modeli.
2. Mechanizm uwagi z przesunięciem
Gemma 2 implementuje nowatorskie podejście do mechanizmów uwagi:
Każda inna warstwa wykorzystuje uwagę z przesunięciem z lokalnym kontekstem 4096 tokenów
Warstwy na przemian wykorzystują pełną kwadratową uwagę globalną w całym kontekście 8192 tokenów
To hybrydowe podejście ma na celu zbalansowanie efektywności z możliwością przechwytywania dalekosiężnych zależności wejściowych.
3. Miękkie ograniczanie
W celu poprawy stabilności szkolenia i wydajności, Gemma 2 wprowadza mechanizm miękkiego ograniczania:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Zastosowane do logitów uwagi logity_uwagi = soft_cap(logity_uwagi, cap=50.0) # Zastosowane do logitów warstwy wyjściowej logity_wyjściowe = soft_cap(logity_wyjściowe, cap=30.0)
Ta technika zapobiega nadmiernemu wzrostowi logitów bez ich twardych ograniczeń, utrzymując więcej informacji i stabilizując proces szkolenia.
- Gemma 2 9B: model o 9 miliardach parametrów
- Gemma 2 27B: większy model o 27 miliardach parametrów
Każdy rozmiar jest dostępny w dwóch wariantach:
- Modele podstawowe: wstępnie przeszkolone na ogromnym korpusie danych tekstowych
- Modele dostosowane do instrukcji (IT): dokształcone w celu lepszej wydajności w określonych zadaniach
4. Destylacja wiedzy
Dla modelu 9B, Gemma 2 wykorzystuje techniki destylacji wiedzy:
- Przeszkolenie: model 9B uczy się od większego modelu nauczyciela podczas początkowego przeszkolenia
- Po przeszkoleniu: oba modele 9B i 27B wykorzystują destylację zgodną z polityką, aby udoskonalić swoją wydajność
Ten proces pomaga mniejszemu modelowi przechwycić możliwości większych modeli w bardziej efektywny sposób.
5. Łączenie modeli
Gemma 2 wykorzystuje nowatorską technikę łączenia modeli o nazwie Warp, która łączy wiele modeli w trzech etapach:
- Średnia ruchoma wykładnicza (EMA) podczas dostrajania za pomocą uczenia ze wzmocnieniem
- Sferyczna interpolacja liniowa (SLERP) po dostrajaniu wielu polityk
- Liniowa interpolacja w kierunku inicjacji (LITI) jako ostateczny krok
To podejście ma na celu stworzenie bardziej wytrzymałego i zdolnego ostatecznego modelu.
Wyniki benchmarkowe
Gemma 2 wykazuje imponującą wydajność w różnych benchmarkach:
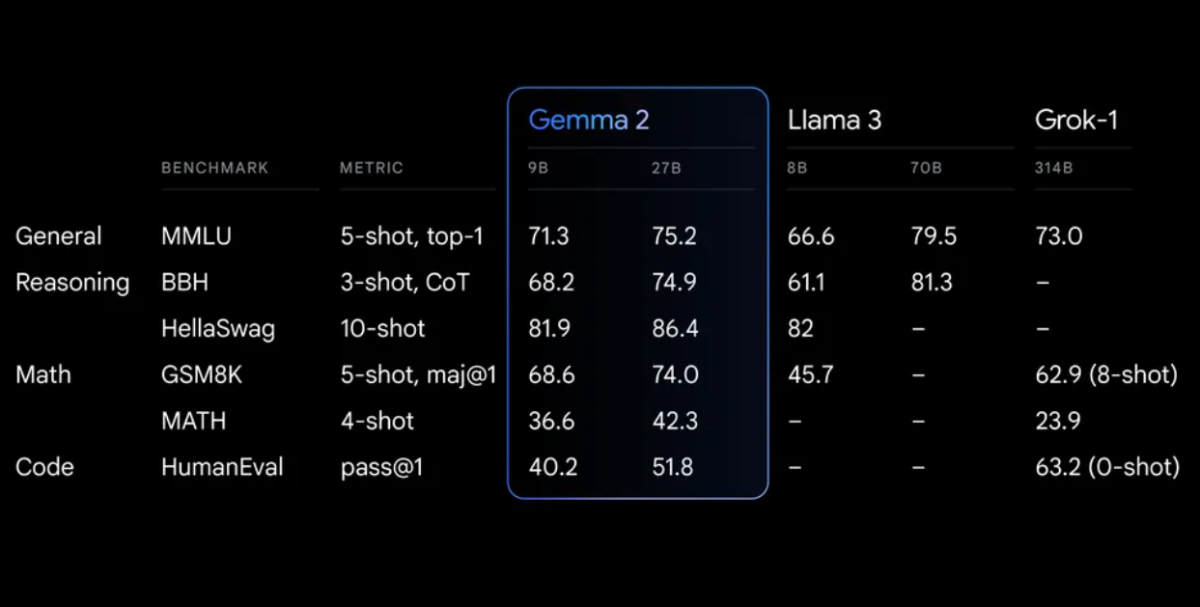
Gemma 2 na zredesignowanej architekturze, zaprojektowanej zarówno dla wyjątkowej wydajności, jak i efektywności inferencji
Rozpoczęcie pracy z Gemmą 2
Aby rozpocząć korzystanie z Gemmy 2 w swoich projektach, masz kilka opcji:
1. Google AI Studio
Dla szybkiej eksperymentacji bez wymagań sprzętowych, możesz uzyskać dostęp do Gemmy 2 za pośrednictwem Google AI Studio.
2. Hugging Face Transformers
Gemma 2 jest zintegrowana z popularną biblioteką Hugging Face Transformers. Oto, jak możesz ją wykorzystać:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Załaduj model i tokenizator model_name = "google/gemma-2-27b-it" # lub "google/gemma-2-9b-it" dla mniejszej wersji tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Przygotuj dane wejściowe prompt = "Wyjaśnij pojęcie splątania kwantowego w prosty sposób." inputs = tokenizer(prompt, return_tensors="pt") # Wygeneruj tekst outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Dla użytkowników TensorFlow, Gemma 2 jest dostępna za pośrednictwem Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Załaduj model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Wygeneruj tekst
prompt = "Wyjaśnij pojęcie splątania kwantowego w prosty sposób."
output = model.generate(prompt, max_length=200)
print(output)
Zaawansowane użycie: Budowanie lokalnego systemu RAG z Gemmą 2
Jednym z potężnych zastosowań Gemmy 2 jest budowanie systemu Retrieval Augmented Generation (RAG). Stworzymy prosty, w pełni lokalny system RAG, wykorzystując Gemmę 2 i Nomic embeddings.
Krok 1: Konfigurowanie środowiska
Najpierw upewnij się, że masz zainstalowane niezbędne biblioteki:
pip install langchain ollama nomic chromadb
Krok 2: Indeksowanie dokumentów
Stwórz indeksator, aby przetworzyć Twoje dokumenty:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












