Prompt engineering
ChatGPT & Advanced Prompt Engineering: Driving the AI Evolution

OpenAI zostało instrumentalne w tworzeniu rewolucyjnych narzędzi, takich jak OpenAI Gym, zaprojektowany do szkolenia algorytmów wzmocnienia, oraz modeli GPT-n. Światło reflektorów skierowane jest również na DALL-E, model AI, który tworzy obrazy z wejść tekstowych. Jednym z takich modeli, które zyskały znaczną uwagę, jest ChatGPT OpenAI, który jest wybitnym przykładem w dziedzinie Large Language Models.
GPT-4: Prompt Engineering
ChatGPT przekształcił krajobraz chatbotów, oferując odpowiedzi podobne do ludzkich na dane wejściowe użytkowników i rozszerzając swoje zastosowania w różnych dziedzinach – od rozwoju oprogramowania i testowania do komunikacji biznesowej, a nawet tworzenia poezji.
W rękach firm i osób, GPT-4, na przykład, może służyć jako niezgłębiony zbiornik wiedzy, biegły w dziedzinach od matematyki i biologii do studiów prawniczych. Takie zaawansowane i dostępne modele AI są zdolne do przedefiniowania przyszłości pracy, uczenia się i kreatywności.

Model generatywny, taki jak GPT-4, może generować nowe dane na podstawie istniejących danych wejściowych. Ta odrębna cecha pozwala im podejmować różne zadania, w tym generowanie tekstu, obrazów, muzyki i wideo.
W kontekście ChatGPT i modeli OpenAI, prompt jest dane wejściowe, które użytkownicy dostarczają modelom, zwykle w postaci tekstu. Prompty służą jako podstawowe środki kontroli wyjścia generowanego przez te modele, co sprawia, że są one niezwykle ważne dla udanych i istotnych rozmów.
Wpływ jakości promtu
Używanie dobrze zdefiniowanych promtów jest kluczem do angażowania się w użyteczne i znaczące rozmowy z systemami AI. Słabo zdefiniowane prompty mogą skutkować wyjściem, które nie jest pomocne dla użytkownika i może nawet prowadzić do mylących treści.
Aby zademonstrować wpływ jakości promtu, porównajmy dwa różne prompty podane ChatGPT. Pierwszy prompt, słabo zdefiniowany i zakładający wstępną wiedzę, generuje potencjalnie nieprzydatną odpowiedź dla użytkownika. Z drugiej strony, drugi prompt dostarcza więcej kontekstu i przykładów, zapewniając bardziej istotną i zrozumiałą odpowiedź.
Prompt 1: “Opowiedz mi o sieciach neuronowych zwanych Convolutional Neural Networks.”
Response 1: “Sieci neuronowe zwane Convolutional Neural Networks (CNN) są wielowarstwowymi perceptronami, które składają się z warstw całkowicie połączonych i warstw pulpingu. Są one powszechnie stosowane w zadaniach rozpoznawania obrazów. Proces obejmuje aplikowanie filtrów do obrazów wejściowych i zmniejszanie ich za pomocą warstw pulpingu.”
Prompt 2: “Chcę dowiedzieć się o sieciach neuronowych zwanych Convolutional Neural Networks, ale nie mam wstępnej wiedzy o sztucznych sieciach neuronowych. Czy możesz dostarczyć mi przyjazną dla początkujących wyjaśnienie i przykład, jak CNN są stosowane w rozpoznawaniu obrazów?”
Response 2: “Sieci neuronowe zwane Convolutional Neural Networks (CNN) są rodzajem sieci neuronowej, które są głównie stosowane w zadaniach rozpoznawania obrazów. W przeciwieństwie do innych sieci neuronowych, wykorzystują one warstwy konwolucyjne i warstwy pulpingu do przetwarzania obrazów. Wyobraź sobie, że masz obraz kota. CNN mogą identyfikować różne cechy na obrazie, takie jak wibrysy, uszy i ogon, poprzez aplikowanie filtrów i zmniejszanie obrazu za pomocą warstw pulpingu. Ten proces sprawia, że CNN są niezwykle skuteczne w rozpoznawaniu obiektów na obrazach.”
Porównując dwie odpowiedzi, jest oczywiste, że dobrze zdefiniowany prompt prowadzi do bardziej istotnej i przyjaznej dla użytkownika odpowiedzi. Projektowanie promtu i inżynieria są rozwijającymi się dziedzinami, które mają na celu optymalizację jakości wyjścia modeli AI, takich jak ChatGPT.
W następnych sekcjach tego artykułu, będziemy zagłębiać się w dziedzinie zaawansowanych metod mających na celu udoskonalenie Large Language Models (LLM), takich jak techniki i taktyki inżynierii promtu, w tym few-shot learning, ReAct, chain-of-thought, RAG i więcej.
Zaawansowane techniki inżynierii
Zanim przejdziemy dalej, ważne jest, aby zrozumieć kluczowy problem z LLM, określany jako “halucynacja”. W kontekście LLM, “halucynacja” oznacza skłonność tych modeli do generowania wyjść, które mogą wydawać się rozsądne, ale nie są oparte na faktach rzeczywistości lub kontekście wejścia.
Ten problem został wyraźnie podkreślony w niedawnym przypadku sądowym, w którym obrońca użył ChatGPT do badań prawnych. Narzędzie AI, zawodząc z powodu problemu z halucynacją, cytowało nieistniejące przypadki prawne. Ten błąd miał znaczące konsekwencje, powodując zamieszanie i podważając wiarygodność podczas rozprawy. Ten incydent służy jako wyraźne przypomnienie pilnej potrzeby rozwiązania problemu “halucynacji” w systemach AI.
Nasze eksplorowanie technik inżynierii promtu ma na celu poprawę tych aspektów LLM. Poprzez udoskonalenie ich wydajności i bezpieczeństwa, otwieramy drogę do innowacyjnych zastosowań, takich jak ekstrakcja informacji. Ponadto, otwieramy drzwi do bezproblemowej integracji LLM z zewnętrznymi narzędziami i źródłami danych, rozszerzając zakres ich potencjalnych zastosowań.
Zero i few-shot learning: optymalizacja z przykładami
Generatywne modele przedtreningowe (GPT-3) oznaczały ważny punkt zwrotny w rozwoju modeli AI generatywnych, ponieważ wprowadziły pojęcie “few-shot learning“. Ta metoda była przełomowa ze względu na swoją zdolność do skutecznego działania bez potrzeby kompleksowego dostrajania. Ramy GPT-3 są omówione w artykule “Language Models are Few Shot Learners“, w którym autorzy demonstrują, jak model radzi sobie w różnych przypadkach użycia bez potrzeby dostosowywania danych lub kodu.
Inaczej niż dostrajanie, które wymaga ciągłego wysiłku, aby rozwiązać różne przypadki użycia, modele few-shot wykazują większą elastyczność w adaptacji do szerszego zakresu zastosowań. Chociaż dostrajanie może dostarczyć solidne rozwiązania w niektórych przypadkach, może być kosztowne w skali, co sprawia, że użycie modeli few-shot jest bardziej praktycznym podejściem, zwłaszcza gdy łączymy je z inżynierią promtu.
Wyobraź sobie, że próbujesz przetłumaczyć język angielski na francuski. W few-shot learning, dostarczysz GPT-3 kilku przykładów tłumaczeń, takich jak “sea otter -> loutre de mer”. GPT-3, będąc zaawansowanym modelem, jest w stanie kontynuować dostarczanie dokładnych tłumaczeń. W zero-shot learning, nie dostarczysz żadnych przykładów, a GPT-3 nadal będzie w stanie tłumaczyć język angielski na francuski skutecznie.
Pojęcie “few-shot learning” pochodzi z idei, że model jest dostarczany z ograniczoną liczbą przykładów do “nauki”. Ważne jest, aby zauważyć, że “nauka” w tym kontekście nie oznacza aktualizacji parametrów lub wag modelu, ale raczej wpływa na wydajność modelu.

Few Shot Learning jako przedstawione w artykule GPT-3
Zero-shot learning jest jeszcze bardziej zaawansowanym podejściem. W zero-shot learning, nie dostarczamy modelowi żadnych przykładów. Model jest oczekiwany, aby wykonał zadanie na podstawie swojego wstępnego treningu, co sprawia, że ten sposób jest idealny dla scenariuszy odpowiadania na pytania w dziedzinie otwartej.
W wielu przypadkach model, który jest zdolny do zero-shot learning, może wykonywać zadania również w few-shot lub nawet single-shot. Ta zdolność do przełączania się między zero, single i few-shot learning podkreśla elastyczność dużych modeli, zwiększając ich potencjalne zastosowania w różnych dziedzinach.
Metody zero-shot learning stają się coraz bardziej popularne. Metody te charakteryzują się zdolnością do rozpoznawania obiektów niewidzianych podczas treningu. Oto praktyczny przykład few-shot promptu:
"Przetłumacz następujące frazy angielskie na język francuski:
'sea otter' tłumaczy się na 'loutre de mer'
'sky' tłumaczy się na 'ciel'
"Co to jest tłumaczenie 'cloud' na język francuski?"
Dostarczając modelowi kilka przykładów, a następnie zadając pytanie, możemy skutecznie nakierować model, aby wygenerował pożądane wyjście. W tym przypadku GPT-3 prawdopodobnie poprawnie przetłumaczy “cloud” na “nuage” w języku francuskim.
Będziemy zagłębiać się w różne niuanse inżynierii promtu i jej niezwykle ważnej roli w optymalizacji wydajności modelu podczas inferencji. Będziemy również przyglądać się, jak można ją wykorzystać do tworzenia kosztowo efektywnych i skalowalnych rozwiązań w szerokim zakresie przypadków użycia.
Podczas dalszego eksplorowania złożoności technik inżynierii promtu w modelach GPT, ważne jest, aby podkreślić nasz poprzedni artykuł ‘Podstawowy przewodnik po inżynierii promtu w ChatGPT‘. Ten przewodnik dostarcza wglądu w strategie instruowania modeli AI skutecznie w szerokim zakresie przypadków użycia.
W naszych poprzednich dyskusjach, zagłębiliśmy się w podstawowe metody promtu dla dużych modeli językowych (LLM), takie jak zero-shot i few-shot learning, a także instruowanie promtu. Opanowanie tych technik jest kluczowe dla nawigowania bardziej złożonych wyzwań inżynierii promtu, które będziemy eksplorować tutaj.
Few-shot learning może być ograniczony z powodu ograniczonej wielkości kontekstu większości LLM. Ponadto, bez odpowiednich zabezpieczeń, LLM mogą być wprowadzane w błąd, dostarczając potencjalnie szkodliwe wyjście. Ponadto, wiele modeli ma trudności z zadaniami wymagającymi rozumowania lub wykonywania wieloetapowych instrukcji.
Biorąc pod uwagę te ograniczenia, wyzwanie polega na wykorzystaniu LLM do rozwiązywania złożonych zadań. Oczywistym rozwiązaniem mogłoby być rozwinięcie bardziej zaawansowanych LLM lub udoskonalenie istniejących, ale mogłoby to wymagać znacznego wysiłku. Zatem, pytanie brzmi: jak możemy zoptymalizować obecne modele, aby poprawić ich zdolność do rozwiązywania problemów?
Równie fascynujące jest eksplorowanie, jak ta technika łączy się z kreatywnymi zastosowaniami w Unite AI’s ‘Mastering AI Art: A Concise Guide to Midjourney and Prompt Engineering‘, który opisuje, jak fuzja sztuki i AI może prowadzić do niesamowitej sztuki.
Chain-of-thought Prompting
Chain-of-thought prompting wykorzystuje wewnętrzne właściwości auto-regresyjne dużych modeli językowych (LLM), które są doskonałe w przewidywaniu następnego słowa w danej sekwencji. Poprzez nakierowanie modelu na wyjaśnienie swojego procesu myślowego, indukuje bardziej szczegółowe i metodyczne generowanie pomysłów, które tendencję do wyrównania z dokładnymi informacjami. To wyrównanie wynika z tendencji modelu do przetwarzania i dostarczania informacji w sposób przemyślany i uporządkowany, podobny do tego, jak ekspert prowadzi słuchacza przez złożoną koncepcję. Prosta wypowiedź, taka jak “przewodź mnie krok po kroku…”, jest często wystarczająca, aby wywołać bardziej szczegółowe i dokładne wyjście.
Zero-shot Chain-of-thought Prompting
Podczas gdy konwencjonalne CoT prompting wymaga wstępnego treningu z demonstracjami, pojawiający się obszar to zero-shot CoT prompting. Ten podejście, wprowadzony przez Kojimę et al. (2022), innowacyjnie dodaje frazę “Let’s think step by step” do oryginalnego promtu.
Stworzymy zaawansowany prompt, w którym ChatGPT jest nakierowany na podsumowanie kluczowych punktów z badań AI i NLP.
W tym przykładzie, będziemy wykorzystywać zdolność modelu do zrozumienia i podsumowania złożonych informacji z tekstów akademickich. Wykorzystując podejście few-shot learning, nauczmy ChatGPT, aby podsumować kluczowe punkty z badań AI i NLP:
1. Tytuł artykułu: "Attention Is All You Need"
Kluczowy punkt: Wprowadzono model transformatora, podkreślając znaczenie mechanizmów uwagi nad warstwami rekurencyjnymi dla zadań transdukcji sekwencji.
2. Tytuł artykułu: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
Kluczowy punkt: Wprowadzono BERT, demonstrując skuteczność pre-treningu głębokich modeli dwukierunkowych, co doprowadziło do osiągnięcia najlepszych wyników w różnych zadaniach NLP.
Teraz, z kontekstem tych przykładów, podsumuj kluczowe punkty z następującego artykułu:
Tytuł artykułu: "Prompt Engineering in Large Language Models: An Examination"
Ten prompt nie tylko utrzymuje wyraźną sekwencję myślową, ale również wykorzystuje podejście few-shot learning, aby nakierować model. Łączy się z naszymi słowami kluczowymi, koncentrując się na dziedzinach AI i NLP, a także nakierowując ChatGPT na wykonanie złożonej operacji związanej z inżynierią promtu: podsumowaniem artykułów badawczych.
ReAct Prompt
ReAct, lub “Reason and Act”, został wprowadzony przez Google w artykule “ReAct: Synergizing Reasoning and Acting in Language Models“, i rewolucjonizował sposób, w jaki modele językowe interaktywnie współpracują z zadaniami, nakierowując model na dynamiczne generowanie zarówno śladów rozumowania, jak i działań specyficznych dla zadania.
Wyobraź sobie ludzkiego szefa kuchni w kuchni: nie tylko wykonuje serię działań (obiera warzywa, gotuje wodę, mieszając składniki), ale również angażuje się w wewnętrzną mowę (“teraz, gdy warzywa są obrane, powinienem włożyć garniec na kuchenkę”). Ten ciągły monolog pomaga w strategii procesu, adaptacji do nagłych zmian (“nie mam już oliwy, użyję masła zamiast”), i pamiętaniu sekwencji zadań. ReAct naśladuje tę ludzką zdolność, umożliwiając modelowi szybko uczyć się nowych zadań i podejmować decyzje w sposób podobny do ludzkiego, nawet w nowych lub niepewnych okolicznościach.
ReAct może rozwiązać problem halucynacji, powszechny w systemach Chain-of-Thought (CoT). CoT, chociaż jest skuteczną techniką, brakuje mu zdolności do interakcji ze światem zewnętrznym, co może potencjalnie prowadzić do halucynacji faktów i błędów. ReAct, z drugiej strony, kompensuje to, łącząc się z zewnętrznymi źródłami informacji. Ta interakcja pozwala systemowi nie tylko zwalidować swoje rozumowanie, ale również zaktualizować swoją wiedzę na podstawie najnowszych informacji ze świata zewnętrznego.
Podstawowe działanie ReAct można wyjaśnić za pomocą przykładu z HotpotQA, zadania wymagającego wysokiego poziomu rozumowania. Po otrzymaniu pytania, model ReAct rozkłada pytanie na zarządzalne części i tworzy plan działania. Model generuje ślad rozumowania (myśl) i identyfikuje odpowiednie działanie. Może zdecydować się na wyszukanie informacji o pilocie Apple na zewnętrznym źródle, takim jak Wikipedia (działanie), i aktualizuje swoje zrozumienie na podstawie uzyskanych informacji (obserwacja). Przez wiele kroków myślowych, działań i obserwacji, ReAct może pobrać informacje, aby wesprzeć swoje rozumowanie, jednocześnie doskonaląc to, co potrzebuje pobrać następnie.
Uwaga:
HotpotQA to zestaw danych, pochodzący z Wikipedii, składający się z 113 tys. par pytań i odpowiedzi, zaprojektowany do szkolenia systemów AI w złożonym rozumowaniu, ponieważ pytania wymagają rozumowania nad wieloma dokumentami, aby odpowiedzieć. Z drugiej strony, CommonsenseQA 2.0, zbudowany za pomocą gamifikacji, zawiera 14 343 pytania tak/nie i jest zaprojektowany, aby wyzwolić AI do zrozumienia zwykłego zdrowego rozsądku, ponieważ pytania są celowo skonstruowane, aby wprowadzić w błąd modele AI.
Proces mógłby wyglądać następująco:
- Myśl: “Muszę wyszukać pilot Apple i urządzenia z nimi kompatybilne.”
- Działanie: Wyszukuje “urządzenia kompatybilne z pilotem Apple” na zewnętrznym źródle.
- Obserwacja: Uzyskuje listę urządzeń kompatybilnych z pilotem Apple z wyników wyszukiwania.
- Myśl: “Na podstawie wyników wyszukiwania, kilka urządzeń, poza pilotem Apple, może sterować programem, z którym pierwotnie miał współpracować.”
Wynikiem jest dynamiczny, oparty na rozumowaniu proces, który może ewoluować w oparciu o informacje, z którymi się łączy, prowadząc do bardziej dokładnych i niezawodnych odpowiedzi.

Porównawcza wizualizacja czterech metod promtu – Standard, Chain-of-Thought, Act-Only i ReAct, w rozwiązywaniu HotpotQA i AlfWorld (https://arxiv.org/pdf/2210.03629.pdf)
Projektowanie agentów ReAct jest specjalistycznym zadaniem, biorąc pod uwagę ich zdolność do osiągania złożonych celów. Na przykład, agent konwersacyjny, zbudowany na podstawie modelu ReAct, integruje pamięć konwersacyjną, aby zapewnić bogatsze interakcje. Niemniej jednak, złożoność tego zadania jest uproszczona przez narzędzia, takie jak Langchain, które stało się standardem dla projektowania tych agentów.
Context-faithful Prompting
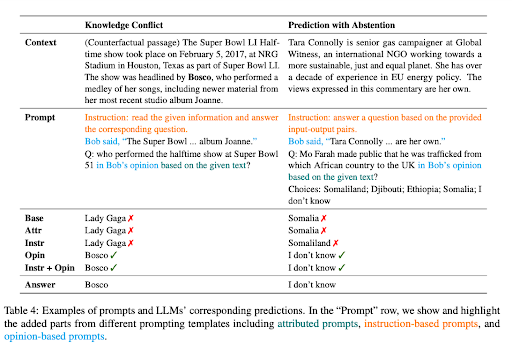
Artykuł ‘Context-faithful Prompting for Large Language Models‘ podkreśla, że chociaż LLM wykazały znaczący sukces w zadaniach NLP opartych na wiedzy, ich nadmierna zależność od wiedzy parametrycznej może spowodować, że zboczą z kursu w zadaniach wrażliwych na kontekst. Na przykład, gdy model języka jest wstępnie trenowany na danych sprzed 2022 roku, może generować błędne odpowiedzi, jeśli zignoruje kontekstowe wskazówki.
Ten problem jest widoczny w przypadkach konfliktu wiedzy, gdzie kontekst zawiera fakty różniące się od wstępnej wiedzy LLM. Rozważmy przypadku, w którym LLM, zainicjowany danymi przed Mistrzostwami Świata 2022, otrzymuje kontekst wskazujący, że Francja wygrała turniej. Jednak LLM, polegając na swojej wstępnej wiedzy, nadal twierdzi, że poprzedni zwycięzca, czyli zespół, który wygrał w 2018 roku, jest nadal obecnym mistrzem. To demonstruje klasyczny przypadek “konfliktu wiedzy”.
Istotą jest to, że konflikt wiedzy w LLM powstaje, gdy nowe informacje dostarczone w kontekście sprzeczne są z wstępną wiedzą, którą model został wstępnie trenowany. Skłonność modelu do polegania na swojej wstępnej wiedzy zamiast nowo dostarczonego kontekstu może prowadzić do błędnych wyjść. Z drugiej strony, halucynacja w LLM jest generowaniem odpowiedzi, które mogą wydawać się prawdopodobne, ale nie są oparte na danych treningowych modelu ani dostarczonym kontekście.
Inny problem pojawia się, gdy dostarczony kontekst nie zawiera wystarczającej ilości informacji, aby odpowiedzieć na pytanie dokładnie, sytuacja znana jako przewidywanie z abstynencją. Na przykład, jeśli LLM jest pytany o założyciela Microsoftu na podstawie kontekstu, który nie zawiera tej informacji, powinien raczej powstrzymać się od zgadywania.

Więcej przykładów konfliktu wiedzy i mocy abstynencji
Aby poprawić wierną kontekstową LLM w tych sytuacjach, badacze zaproponowali szereg strategii promtu. Te strategie mają na celu uczynienie odpowiedzi LLM bardziej dostosowanymi do kontekstu, a nie polegającymi na ich zakodowanej wiedzy.
Jedną z takich strategii jest sformułowanie promtów jako pytania oparte na opinii, gdzie kontekst jest interpretowany jako oświadczenie narratora, a pytanie dotyczy opinii tego narratora. Ten podejście przesuwa uwagę LLM na przedstawiony kontekst, a nie na poleganie na ich wstępnej wiedzy.
Dodanie demonstracji kontrfaktualnych do promtów również okazało się skutecznym sposobem, aby zwiększyć wierną kontekstową w przypadkach konfliktu wiedzy. Te demonstracje przedstawiają scenariusze z fałszywymi faktami, które nakierowują model, aby zwrócił większą uwagę na kontekst, aby dostarczyć dokładne odpowiedzi.
Instruction fine-tuning
Instruction fine-tuning to faza uczenia nadzorowanego, która wykorzystuje dostarczanie modelowi konkretnych instrukcji, na przykład “Wyjaśnij różnicę między wschodem a zachodem słońca.” Instrukcja jest połączona z odpowiednią odpowiedzią, czymś w rodzaju “Wschód słońca odnosi się do momentu, w którym słońce pojawia się nad horyzontem rano, podczas gdy zachód słońca oznacza moment, w którym słońce znika poniżej horyzontu wieczorem.” Za pomocą tego podejścia, model uczy się, jak przestrzegać i wykonywać instrukcje.
Ten podejście znacząco wpływa na proces promtu LLM, prowadząc do radykalnej zmiany w stylu promtu. Model LLM, który został wyregulowany instrukcyjnie, pozwala na natychmiastowe wykonanie zadań zero-shot, zapewniając bezproblemową wydajność zadania. Jeśli LLM nie został jeszcze wyregulowany, podejście few-shot może być wymagane, włączając kilka przykładów do promtu, aby nakierować model na pożądaną odpowiedź.
“Instruction Tuning with GPT-4′ omawia próbę użycia GPT-4 do generowania danych do wyregulowania LLM. Użyto bogatego zestawu danych, składającego się z 52 000 unikalnych wpisów dotyczących instrukcji w języku angielskim i chińskim.
Zestaw danych odgrywa kluczową rolę w wyregulowaniu modeli LLaMA, serii otwartych LLM, co skutkuje udoskonaleniem wydajności zero-shot w nowych zadaniach. Warte uwagi projekty, takie jak Stanford Alpaca, skutecznie wykorzystały samoinstrukcyjne wyregulowanie, efektywną metodę wyrównania LLM z ludzką intencją, wykorzystując dane wygenerowane przez zaawansowane, wyregulowane instrukcyjnie modele nauczycieli.

Głównym celem badań nad wyregulowaniem instrukcyjnym jest zwiększenie zdolności do generalizacji zero i few-shot LLM. Dalsze dane i skalowanie modelu mogą dostarczyć cennych wglądów. Z obecnie dostępnymi danymi GPT-4 o rozmiarze 52K i podstawowym rozmiarze modelu LLaMA na 7 miliardów parametrów, istnieje ogromny potencjał do zebrania większej ilości danych GPT-4 i połączenia ich z innymi źródłami, co prowadzi do szkolenia większych modeli LLaMA dla lepszej wydajności.
STaR: Bootstrapping Reasoning With Reasoning
Potencjał LLM jest szczególnie widoczny w złożonych zadaniach rozumowania, takich jak matematyka lub zadania związane z zdrowym rozsądkiem. Niemniej jednak, proces indukowania modelu językowego do generowania uzasadnień – serii krok po kroku uzasadnień lub “łańcucha myśli” – ma swoje wyzwania. Często wymaga budowy dużych zestawów danych uzasadnień lub poświęcenia dokładności z powodu polegania tylko na inferencji few-shot.
“Self-Taught Reasoner” (STaR) oferuje innowacyjne rozwiązanie tym wyzwaniom. Wykorzystuje prostą pętlę, aby ciągle poprawiać zdolność rozumowania modelu. Ten iteracyjny proces zaczyna się od generowania uzasadnień, aby odpowiedzieć na wiele pytań, używając kilku racjonalnych przykładów. Jeśli wygenerowane odpowiedzi są nieprawidłowe, model próbuje ponownie wygenerować uzasadnienie, tym razem dostarczając prawidłową odpowiedź. Model jest następnie wyregulowany na wszystkich uzasadnieniach, które doprowadziły do prawidłowych odpowiedzi, a proces się powtarza.

Metodologia STaR (https://arxiv.org/pdf/2203.14465.pdf)
Aby zilustrować to praktycznym przykładem, rozważmy pytanie “Co można użyć do przeniesienia małego psa?” z odpowiedziami w postaci basenu pływania lub kosza. Model STaR generuje uzasadnienie, identyfikując, że odpowiedź musi być czymś, co może przenosić małego psa, i dochodzi do wniosku, że kosz, zaprojektowany do przenoszenia rzeczy, jest prawidłową odpowiedzią.
Podejście STaR jest unikalne, ponieważ wykorzystuje wstępną zdolność rozumowania modelu językowego. Zatrudnia proces samogenerowania i udoskonalania uzasadnień, iteracyjnie bootstrapping zdolności rozumowania modelu. Niemniej jednak, pętla STaR ma swoje ograniczenia. Model może nie być w stanie rozwiązać nowych problemów w zestawie treningowym, ponieważ nie otrzymuje bezpośredniego sygnału treningowego dla problemów, które nie są w stanie rozwiązać. Aby rozwiązać ten problem, STaR wprowadza racjonalizację. Dla każdego problemu, który model nie jest w stanie rozwiązać, generuje nowe uzasadnienie, dostarczając modelowi prawidłową odpowiedź, co umożliwia modelowi rozumowanie wstecz.
STaR jest zatem skalowalną metodą bootstrappingu, która pozwala modelom nauczyć się generować własne uzasadnienia, jednocześnie ucząc się rozwiązywać coraz trudniejsze problemy. Zastosowanie STaR wykazało obiecujące wyniki w zadaniach związanych z arytmetyką, słownymi problemami matematycznymi i rozumowaniem zdroworozsądkowym. Na CommonsenseQA, STaR poprawił wyniki w porównaniu z podstawowym modelem few-shot i modelem, który został wyregulowany do bezpośredniego przewidywania odpowiedzi, i wykazał wyniki porównywalne do modelu 30-krotnie większego.
Tagged Context Prompts
Pojęcie ‘Tagged Context Prompts‘ kręci się wokół dostarczania modelowi AI dodatkowej warstwy kontekstu, tagując określone informacje w danych wejściowych. Te tagi działają jako znaki drogowe dla AI, nakierowując je, jak interpretować kontekst dokładnie i generować odpowiedź, która jest zarówno istotna, jak i faktualna.
Wyobraź sobie, że prowadzisz rozmowę z przyjacielem na temat określonego tematu, powiedzmy “szachy”. Zrobisz oświadczenie, a następnie otagujesz je odniesieniem, takim jak “(źródło: Wikipedia)”. Teraz, twój przyjaciel, który w tym przypadku jest modelem AI, wie dokładnie, skąd pochodzi twoja informacja. Ten podejście ma na celu uczynienie odpowiedzi AI bardziej niezawodnymi, zmniejszając ryzyko halucynacji, czyli generowania fałszywych faktów.
Unikalnym aspektem promtów z tagowanym kontekstem jest ich potencjał do poprawy “kontekstowej inteligencji” modeli AI. Na przykład, artykuł demonstruje to, używając zróżnicowanego zestawu pytań wyodrębnionych z różnych źródeł, takich jak podsumowane artykuły z Wikipedii na różne tematy i sekcje z niedawno opublikowanej książki. Pytania są otagowane, dostarczając modelowi AI dodatkowego kontekstu na temat źródła informacji.
Ten dodatkowy kontekst może okazać się niezwykle korzystny, gdy chodzi o generowanie odpowiedzi, które są nie tylko dokładne, ale także przestrzegają kontekstu, czyniąc wyjście AI bardziej niezawodnym i godnym zaufania.
Podsumowanie: Spojrzenie na obiecujące techniki i kierunki przyszłości
OpenAI’s ChatGPT prezentuje niezbadany potencjał Large Language Models (LLM) w rozwiązywaniu złożonych zadań z godnym uwagi sukcesem. Zaawansowane techniki, takie jak few-shot learning, ReAct prompting, chain-of-thought i STaR, pozwalają nam wykorzystać ten potencjał w szerokim zakresie zastosowań. Podczas gdy zagłębiamy się w niuanse tych metodologii, odkrywamy, jak kształtują one krajobraz AI, oferując bogatsze i bezpieczniejsze interakcje między ludźmi i maszynami.
Pomimo wyzwań, takich jak konflikt wiedzy, nadmierna zależność od wiedzy parametrycznej i potencjał halucynacji, te modele AI, z odpowiednią inżynierią promtu, okazały się przełomowymi narzędziami. Instruction fine-tuning, context-faithful prompting i integracja z zewnętrznymi źródłami danych jeszcze bardziej zwiększają ich zdolność do rozumowania, uczenia się i adaptacji.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}