Sztuczna inteligencja
Andrew Ng krytykuje kulturę przefittingu w machine learning
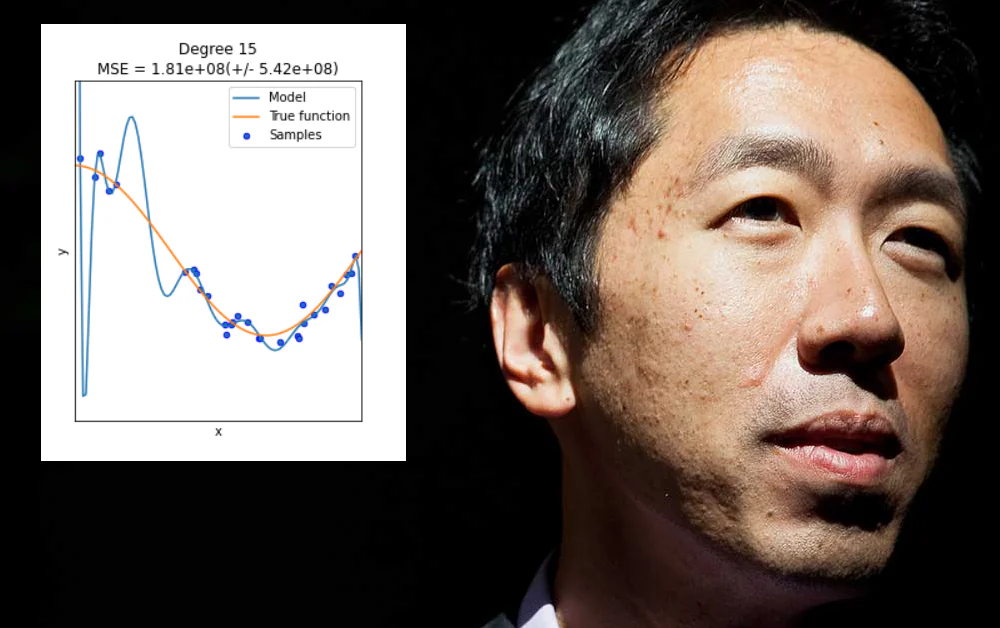
Andrew Ng, jeden z najbardziej wpływowych głosów w machine learning w ciągu ostatniej dekady, obecnie wyraża obawy co do stopnia, w jakim sektor ten kładzie nacisk na innowacje w architekturze modelu ponad dane – i konkretnie, w jakim stopniu pozwala na przedstawianie “przefitowanych” wyników jako uogólnione rozwiązania lub postępy.
Są to daleko idące krytyki obecnej kultury machine learning, pochodzące z jednego z najwyższych autorytetów w tej dziedzinie, i mają wpływ na zaufanie do sektora, który jest naznaczony obawami o trzeci upadek zaufania biznesu do rozwoju AI w ciągu sześćdziesięciu lat.
Ng, profesor na Uniwersytecie Stanforda, jest również jednym z założycieli deeplearning.ai, i w marcu opublikował list na stronie organizacji, który zawierał niedawne przemówienie Ng, które zostało zredukowane do kilku podstawowych rekomendacji:
Po pierwsze, że społeczność badawcza powinna przestać narzekać, że czyszczenie danych stanowi 80% wyzwań w machine learning, i zająć się rozwojem solidnych metodologii i praktyk MLOps.
Po drugie, że powinna odejść od “łatwych zwycięstw”, które można uzyskać przez przefittingowanie danych do modelu machine learning, tak aby model działał dobrze na tym modelu, ale nie był w stanie uogólnić lub wyprodukować szeroko stosowanego modelu.
Akceptacja wyzwania architektury i kuracji danych
“Mój pogląd” – napisał Ng – “jest taki, że jeśli 80 procent naszej pracy to przygotowanie danych, to zapewnienie jakości danych jest ważną pracą zespołu machine learning”.
Dodał:
“Zamiast liczyć na to, że inżynierowie przypadkowo znajdą najlepszy sposób poprawy zbioru danych, mam nadzieję, że możemy rozwinąć narzędzia MLOps, które pomogą uczynić budowanie systemów AI, w tym budowanie wysokiej jakości zbiorów danych, bardziej powtarzalnymi i systematycznymi.
“MLOps to młoda dziedzina, i różni ludzie definiują ją inaczej. Ale uważam, że najważniejszym zasadą organizacyjną zespołów i narzędzi MLOps powinno być zapewnienie stałego i wysokiej jakości przepływu danych we wszystkich etapach projektu. To pomoże wielu projektom przebiec gładziej.”
Mówiąc na Zoom podczas na żywo przesyłanego sesji Q&A na koniec kwietnia, Ng omówił brak zastosowania w systemach analizy radiologicznej machine learning:
“Okazuje się, że gdy zbieramy dane ze szpitala Stanford, a następnie trenujemy i testujemy na danych z tego samego szpitala, rzeczywiście możemy opublikować prace pokazujące, że [algorytmy] są porównywalne z radiologami w wykrywaniu pewnych schorzeń.
“…[Gdy] weźmiemy ten sam model, ten sam system AI, do starszego szpitala na ulicy, z starszą maszyną, a technicy używają nieco innego protokołu obrazowania, dane te ulegają przesunięciu, co powoduje znaczne pogorszenie wyników systemu AI. W przeciwieństwie do tego, każdy radiolog może iść na ulicę do starszego szpitala i wszystko będzie w porządku.”
Niespecyfikacja nie jest rozwiązaniem
Przefittingowanie występuje, gdy model machine learning jest specjalnie zaprojektowany, aby dostosować się do ekcentryczności określonego zbioru danych (lub sposobu, w jaki dane są sformatowane). Może to obejmować na przykład określenie wag, które dadzą dobre wyniki z tego zbioru danych, ale nie “uogólnią” na innych danych.
W wielu przypadkach takie parametry są definiowane na “nie-danych” aspektach zestawu treningowego, takich jak konkretna rozdzielczość zebranych informacji lub inne idiosynkracje, które nie są gwarantowane, aby wystąpić w innych następnych zbiorach danych.
Chociaż byłoby miło, przefittingowanie nie jest problemem, który można rozwiązać, ślepo rozszerzając zakres lub elastyczność architektury danych lub projektu modelu, gdy tym, co jest naprawdę potrzebne, są powszechnie stosowane i wysoko istotne cechy, które będą działać dobrze w różnych środowiskach danych – bardziej kolczasty wyzwanie.
Ogólnie, ten rodzaj “niespecyfikacji” prowadzi tylko do tych samych problemów, które Ng ostatnio opisał, gdzie model machine learning nie działa na niewidocznych danych. Różnica w tym przypadku polega na tym, że model nie działa nie dlatego, że dane lub formatowanie danych są różne od oryginalnego zestawu treningowego, ale dlatego, że model jest zbyt giętki, a nie zbyt kruchy.
Pod koniec 2020 roku praca Underspecification Presents Challenges for Credibility in Modern Machine Learning skrytykowała tę praktykę i nosiła nazwiska aż czterdziestu naukowców i badaczy z Google i MIT, wśród innych instytucji.
Praca krytykuje “szybkie uczenie”, i obserwuje, w jaki sposób niespecyfikowane modele mogą odejść w dzikie tangenty na podstawie punktu losowego, w którym rozpoczyna się trening modelu. Współautorzy obserwują:
‘Zobaczyliśmy, że niespecyfikacja jest wszechobecna w praktycznych pipeline’ach machine learning w wielu dziedzinach. Rzeczywiście, dzięki niespecyfikacji, istotne aspekty decyzji są determinowane przez arbitralne wybory, takie jak losowy punkt startowy użyty do inicjacji parametrów.’
Ekonomiczne konsekwencje zmiany kultury
Pomimo swoich akademickich kwalifikacji, Ng nie jest żadnym lekkomyślnym akademikiem, ale ma głębokie i wysokie doświadczenie w branży jako współzałożyciel Google Brain i Coursera, były główny naukowiec ds. Big Data i AI w Baidu, oraz założyciel Landing AI, który administruje 175 milionów dolarów na nowe startupy w sektorze.
Gdy mówi “Cały AI, a nie tylko opieka zdrowotna, ma lukę między pojęciem a produkcją”, jest to zamierzone jako wezwanie do sektora, którego obecny poziom hossy i plamistej historii coraz bardziej charakteryzuje się jako niepewna długoterminowa inwestycja biznesowa, zmaganą z problemami definicji i zakresu.
Niemniej jednak, własne systemy machine learning, które działają dobrze w miejscu i nie działają w innych środowiskach, reprezentują rodzaj przechwycenia rynku, który mógłby nagrodzić inwestycje przemysłowe. Przedstawianie “problemu przefittingu” w kontekście zawodowego niebezpieczeństwa oferuje nieuczciwy sposób monetyzacji korporacyjnych inwestycji w badania open source, i wytwarzania (skutecznie) własnych systemów, gdzie replikacja przez konkurentów jest możliwa, ale problematyczna.
Czy ten podejście będzie działać w długim terminie, zależy od stopnia, w jakim prawdziwe przełomy w machine learning będą wymagać coraz większych poziomów inwestycji, i czy wszystkie produktywne inicjatywy ostatecznie migrują do FAANG do pewnego stopnia, ze względu na ogromne zasoby niezbędne do hostowania i operacji.












