AI 101
Hva er Bayes’ teorem?
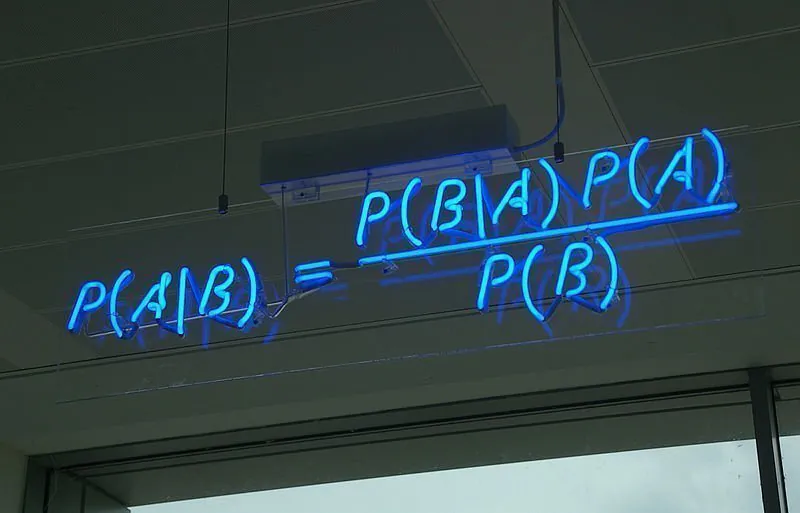
Hvis du har lært om datavitenskap eller maskinlæring, er det sannsynlig at du har hørt uttrykket “Bayes’ teorem” før, eller en “Bayes-klassifikator”. Disse konseptene kan være litt forvirrende, spesielt hvis du ikke er vant til å tenke på sannsynlighet fra et tradisjonelt, frekventistisk statistikkperspektiv. Denne artikkelen vil prøve å forklare prinsippene bak Bayes’ teorem og hvordan det brukes i maskinlæring.
Hva er Bayes’ teorem?
Bayes’ teorem er en metode for å beregne betinget sannsynlighet. Den tradisjonelle metoden for å beregne betinget sannsynlighet (sannsynligheten for at et hendelse skjer gitt at en annen hendelse skjer) er å bruke betinget sannsynlighetsformelen, beregne den felles sannsynligheten for hendelse ett og hendelse to som skjer samtidig, og deretter dividere det med sannsynligheten for at hendelse to skjer. Men, betinget sannsynlighet kan også beregnes på en litt annerledes måte ved å bruke Bayes’ teorem.
Når du beregner betinget sannsynlighet med Bayes’ teorem, følger du disse stegene:
- Bestemm sannsynligheten for at betingelse B er sann, antatt at betingelse A er sann.
- Bestemm sannsynligheten for at hendelse A er sann.
- Multiplicer de to sannsynlighetene sammen.
- Divider med sannsynligheten for at hendelse B skjer.
Dette betyr at formelen for Bayes’ teorem kan uttrykkes slik:
P(A|B) = P(B|A)*P(A) / P(B)
Å beregne betinget sannsynlighet på denne måten er spesielt nyttig når den omvendte betingede sannsynligheten kan beregnes lett, eller når beregning av den felles sannsynligheten ville være for utfordrende.
Eksempel på Bayes’ teorem
Dette kan være lettere å forstå hvis vi ser på et eksempel på hvordan du ville bruke bayesisk resonnering og Bayes’ teorem. La oss anta at du spiller et enkelt spill hvor flere deltakere forteller deg en historie og du må bestemme hvem av deltakerne som lyver til deg. La oss fylle inn ligningen for Bayes’ teorem med variablene i dette hypotetiske scenariot.
Vi prøver å forutsi om hver enkelt deltaker i spillet lyver eller forteller sannheten, så hvis det er tre spillere utenom deg, kan de kategoriske variablene uttrykkes som A1, A2 og A3. Bevisene for deres løgner/sannheter er deres atferd. Som når du spiller poker, ville du se etter bestemte “tegn” som indikerer at en person lyver og bruke disse som bits av informasjon til å informere din gjett. Eller hvis du var tillatt å spørre dem, ville det være noen bevis som deres historie ikke stemmer overens. Vi kan representere bevisene for at en person lyver som B.
For å være tydelig, prøver vi å forutsi Sannsynligheten(A lyver/forteller sannheten|gitt bevisene for deres atferd). For å gjøre dette ville vi ønske å finne ut sannsynligheten for B gitt A, eller sannsynligheten for at deres atferd ville skje gitt at personen faktisk lyver eller forteller sannheten. Du prøver å bestemme under hvilke betingelser atferden du ser ville ha mest mening. Hvis det er tre atferder du observerer, ville du gjøre beregningen for hver atferd. For eksempel, P(B1, B2, B3 * A). Du ville så gjøre dette for hver forekomst av A/for hver person i spillet utenom deg selv. Det er denne delen av ligningen ovenfor:
P(B1, B2, B3,|A) * P|A
Til slutt deler vi bare på sannsynligheten for B.
Hvis vi mottok noen bevis om de faktiske sannsynlighetene i denne ligningen, ville vi rekonstruere vår sannsynlighetsmodell, og ta det nye beviset med i betraktning. Dette kalles å oppdatere dine priorer, da du oppdater dine antakelser om den tidligere sannsynligheten for de observerte hendelsene.
Maskinlæringsapplikasjoner for Bayes’ teorem
Den vanligste bruken av Bayes’ teorem når det kommer til maskinlæring er i form av den naive Bayes-algoritmen.
Naive Bayes brukes til klassifisering av både binære og multi-klassedatasett, Naive Bayes får sitt navn fordi verdiene som er tildelt vitnene/bevisene/attributtene – Bs i P(B1, B2, B3 * A) – antas å være uavhengige av hverandre. Det antas at disse attributtene ikke påvirker hverandre for å forenkle modellen og gjøre beregningene mulige, i stedet for å prøve å beregne forholdet mellom hver av attributtene. Til tross for denne forenklede modellen, tenderer Naive Bayes til å fungere ganske bra som en klassifiseringsalgoritme, selv når dette antagandet sannsynligvis ikke er sant (hvilket er det meste av tiden).
Det finnes også vanlige varianter av den naive Bayes-klassifikatoren, som Multinomial Naive Bayes, Bernoulli Naive Bayes og Gaussian Naive Bayes.
Multinomial Naive Bayes-algoritmer brukes ofte til å klassifisere dokumenter, da det er effektivt til å tolke frekvensen av ord innenfor et dokument.
Bernoulli Naive Bayes fungerer på samme måte som Multinomial Naive Bayes, men forutsigelsene som algoritmen gir er booleske. Dette betyr at når du forutsier en klasse, vil verdiene være binære, nei eller ja. I tekstklassifiseringens domene ville en Bernoulli Naive Bayes-algoritme tildele parameterne et nei eller ja basert på om et ord er funnet innenfor tekst-dokumentet.
Hvis verdien av prediktorer/funksjonene ikke er diskrete, men er kontinuerlige, kan Gaussian Naive Bayes brukes. Det antas at verdiene de kontinuerlige funksjonene er samplet fra en gaussisk distribusjon.












