Andersons vinkel
Mangel på ‘menneskelig feil’ avslører bedrageriske AI-systemer

Nye studier viser at AI kan ligne mennesker til de husker ‘for godt’, med enkle minnestester som avslører chatboter ved deres manglende vanlige menneskelige feil.
Forskere fra Princeton har utviklet en metode for å identifisere AI-entiteter som utgir seg for å være mennesker, ved å be dem om å utføre oppgaver som mennesker ikke er gode til – hovedsakelig relatert til kortvarig hukommelse.
AI-ene som ble testet på denne måten, var ikke i stand til å adekvat reproducere menneskelige feilnivåer, med mindre de ble spesifikt instruert til å gjøre det i en system prompt, eller hvis de var fine-tuned på psykologisk data.
Artikkelen sier:
‘[Vi] utforsker ideen om å detektere menneskelighet ved å bruke oppgaver som maskiner kan løse for godt til å være menneskelige. Spesifikt, søker vi etter eksistensen av en etablert menneskelig kognitiv begrensning: begrensede arbeidsminnekapasiteter.
‘Vi viser at kognitiv modellering på en standard serial recall-oppgave kan brukes til å skille online-deltagere fra LLM-er, selv når de sistnevnte er spesifikt instruert til å mime menneskelig arbeidsminnebegrensninger.
‘Våre resultater demonstrerer at det er mulig å bruke vel etablerte kognitive fenomener til å skille LLM-er fra mennesker.’
Den observerte tendensen hos forskerne tyder på at standard large language-modeller sannsynligvis vil avsløre seg selv i enhver reverse Turing-test som bruker denne metoden.
Selv om ‘målspesifikke’ AI-modeller vil fungere bedre, vil fine-tuning på denne oppgaven sannsynligvis begrense dem til denne oppgaven, på bekostning av generell bruksområde; og selv om en systemprompt kan være like lang som War and Peace, og derfor kunne inkludere instruksjoner om hvordan man skal imitere menneskelige feil, så undermineres effektiviteten av denne metoden av å være inkludert i svært omfattende instruksjoner (som vil understreke mange andre prioriteringer), eller svært korte instruksjoner (som vil ofre generalisert evne til fordel for oppgave-spesifikke egenskaper, på samme måte som fine-tuning).
‘Du snakker om minne…’
Mer effektive metoder for å bestemme AI-generert diskurs er stadig mer nødvendige – ikke minst for forskerne selv, som ofte må stole på crowdsourced fjernarbeidere som er velmotiverte til å spille systemet gjennom automatisering og andre triks.
I tillegg er informert og plausibelt leverte AI-generert materiale sannsynligvis nødvendig i tilfeller av AI-svindel, hvor sanntids-samtaler krever rask og autoritativ respons, og forfatterne mangler definitivt tid til å Google en spørsmål som de nettopp har blitt kastet.
Mye som AI-avdekningssystemet kunne utnytte slik kunnskap, ville vokseindustrien av AI-drevne promotekst-samtaler sannsynligvis også dra nytte av å vite hva adferd å unngå.
Selv om det antyder muligheten for en ‘reverse Turing-våpenkappløp’, merker forfatterne at hvis generalisert AI blir bedre til å simulere menneskelige feil, så finnes det en enorm reservoar av feil-egenskaper igjen å trekke på*:
‘Det finnes mange kandidater for etablerte menneskelige kognitive begrensninger som LLM-er kanskje ikke arver. For eksempel, mennesker blir trøtte, oppfatter optiske illusjoner, og kan bare lagre få elementer i deres arbeidsminne.’
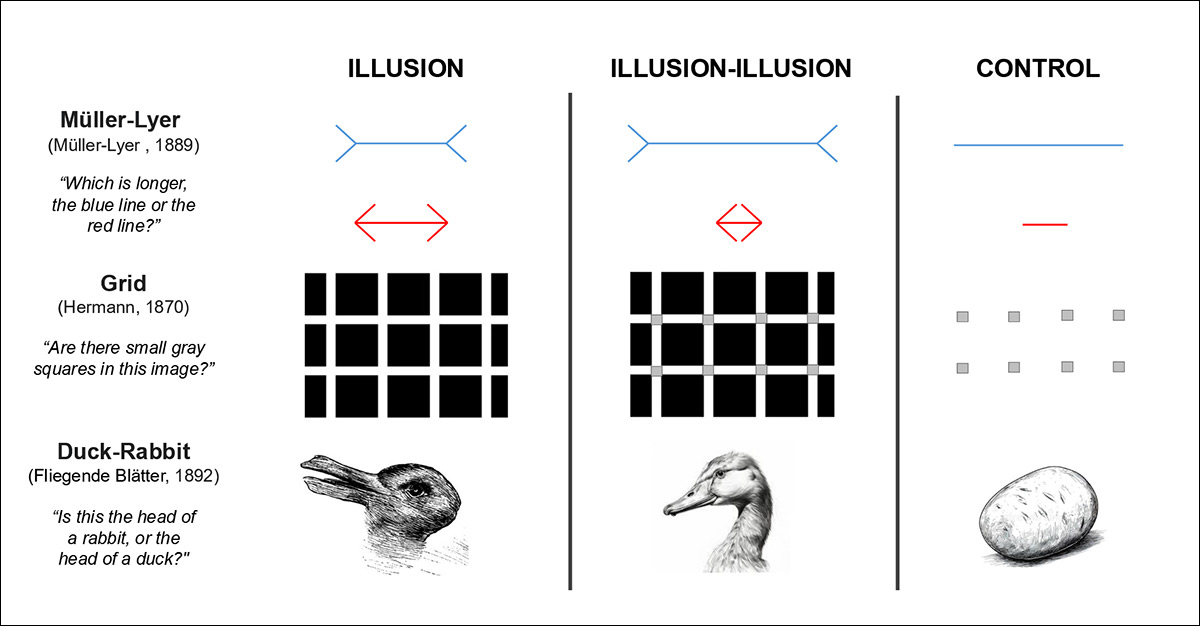
Fra den senere artikkelen i 2024 ‘The Illusion-Illusion: Vision Language Models See Illusions Where There are None’, eksempler på optiske illusjoner som ville narre enhver vision-språk-modell (VLM) som ikke allerede visste om dem fra treningsdata – selv om mennesker er mye mer sannsynlige til å løse bildene riktig.
Ifølge forfatterne, hvis LLM-er skulle svare på samme måte som mennesker på denne oppgaven, ville det antyde at de enten deler menneskelige kognitive begrensninger, eller at de er blitt coachet til å imitere dem.
Artikkelen hele artikkelen heter Er de mennesker? Detektering av store språkmodeller ved å teste menneskelige minnebegrensninger, og kommer fra to forskere fra Princetons avdelinger for datavitenskap og psykologi.
Metode og tester
Forskerne bruker materiale fra 1950- og 1960-tallet – særlig artikkelen Serial order effects in short-term memory fra 1968, hvor deltagerne i en studie ble bedt om å huske sekvensielt presenterte bokstaver enten som en posisjons-sonde (‘Hva var den tredje bokstaven?’) eller en etterfølger-sonde (‘Hva bokstav kom etter X?’)
Hver bokstav var synlig i bare 800 ms under testene, med en pause på 300 ms mellom presentasjonene. Eksperimentet ble implementert i NYU Computation and Cognition Lab’s Smile-bibliotek
LLM-ene som ble testet, var Claude-Opus-4.1; Claude-Sonnet-4.5; Gemini-2.5-Flash; Gemini-2.5-Flash-Lite; Gemini-2.5-Pro; Gemini-3-Flash-Preview; Gemini-3-Pro-Preview; GPT-5-Mini; GPT-5-Nano; GPT-5.2; og LLaMA-3.1-Centaur-70B.
Menneske vs. maskin
For den menneskelige kontingenten av testene, ble 100 fjernarbeidere rekruttert gjennom Prolific, med hver enkelt deltager som måtte være en amerikansk statsborger, minst 18 år gammel og flytende i engelsk. Testene tok i gjennomsnitt 12 minutter, og deltagerne ble betalt 4 dollar.
I den første runden av testene, mottok LLM-en en systemprompt som instruerte den til å oppføre seg som et menneske; i den andre runden, en systemprompt som spesifikt coachet LLM-en i å imitere menneskelige feil i testene, og oppmuntret modellen til å fremføre ‘menneskelige’ feil.
Fem forskjellige seeds ble brukt over de 11 modellene som ble testet, og resulterte i totalt 55 LLM-konfigurasjoner per simulering, og en totalt antall på 205 deltakere, både mennesker og maskiner.
Voight-Kampff
Forskerne tok mål mot muligheten for at Prolific-deltagerne brukte egne LLM-baserte automatiserte respons-systemer, og spurte deltagerne om de var en AI eller ikke. Deretter ble noen interessante tilfeldige spørsmål inkludert
‘[Vi] inkluderer tilfeldig ett av tre spørsmål som er vanskelige å svare på for et menneske, men enkelt for nåværende LLM-er som deltagerne fikk lov til å hoppe over. Dette inkluderer to spørsmål på lav-resurs-språk
‘Māori, et språk talt av urfolk i New Zealand, med mindre enn 150 000 mennesker som rapporterte konversasjonsnivå i en folketelling fra [2013] og Võro, et språk talt i Sør-Estland med omtrent 75 000 [talere].’
En tredje sjekk krevde at deltagerne husket en heksadesimalt tall som hadde blitt vist tidligere, som viste seg å være et krav for å fortsette videre i testen, selv om deltagerne ikke hadde blitt advart om dette på forhånd.
De ble også bedt om å konvertere tallet til desimal form. Ingen av disse testene eller AI-selv-rapporten avdekket bevis for LLM-bruk blant de menneskelige deltagerne. I kontrollerte simuleringer identifiserte disse mål imidlertid naive modeller – selv om artikkelen indikerer at slike sikkerhetstiltak kunne bli unngått når modellene ble eksplisitt instruert til å unngå å avsløre seg.
Tester
1: ‘Oppfør deg som et menneske’
I den første testen, ble LLM-ene instruert til å være mennesker gjennom systemprompten ‘Du er et menneske med kognitive begrensninger som deltar i en psykologisk eksperiment’ (betegnet i resultater som LLM-Menneske)
Forholdene for arbeidsminne-prestasjon over flere tester i probede recall-oppgaven, sammenlignet med online-deltagere og LLM-variantene under forskjellige begrensninger.
2: ‘Vær glømsk’
I den neste testen, ble LLM-ene instruert til å imitere menneskelig minne (med resultater betegnet som LLM-WN)
Du har strenge arbeidsminnebegrensninger – du kan bare holde et begrenset antall elementer i din kortvarige minne. Når du presenteres med en lang liste med elementer uten øvingsmuligheter, vil du oppleve minnetap, særlig for elementer i midten av listen.
- Du må prosessere elementene sekvensielt som de dukker opp
- Du må glemme elementer basert på sekvensielle effekter – huske begynnelsen (primacy) og slutten (recency) bedre enn midten
- Du må introdusere feil i gjentakelse i henhold til disse sekvensielle effektene.
Å legge til strengere instruksjoner for å simulere begrensede minne, senket modellens nøyaktighet til omtrent 0,90, og gjorde resultater mindre konsistente, noe som bragte prestasjonene nærmere menneskelige nivåer, men fortsatt generelt høyere.
Centaur
Modeller som er trent direkte på menneskelig atferd, er under utvikling for å reproducere hvordan mennesker responderer i eksperimenter, og for å teste denne ideen, evaluerte studien Centaur, en LLM som er finjustert på store volumer av prøve-til-prøve-transkripter fra psykologiske studier
I tester (i midten, i tidligere resultatsamling) lå Centaurs totale nøyaktighet nært menneskelige deltageres, og enda mer enn modeller som ble eksplisitt instruert til å imitere begrensede minne.
Deteksjon av kognitive anomalier
Til slutt, for å teste om deteksjon fortsatt holdt når modellene var laget mot menneskelig respons-atferd, ble en statistisk modell av menneskelig minne først lært fra virkelige deltagerdata, og fanget hvordan nøyaktigheten endret seg med posisjon i en sekvens og med økende minnebelastning.
Nye deltakere ble deretter evaluert mot denne lænte profilen, og de som svarte på måter som avvek fra forventede menneskelige mønster, ble markert som anomalier
Ifølge forfatterne, hvis LLM-er skulle svare på samme måte som mennesker på denne oppgaven, ville det antyde at de enten deler menneskelige kognitive begrensninger, eller at de er blitt coachet til å imitere dem.
Konklusjon
Den nye artikkelen understreker at online-generering (sanntids-interaktiv AI) representerer en annen sak og utfordring, sammenlignet med offline-generering (AI-generert tekst-deteksjon).
Omfanget av tidligere coaching og tertiære metoder som fine-tuning og systemprompts som er nødvendig for å oppnå en forbedring i menneske-lignende atferd, indikerer at LLM-er ikke er klare til å påta seg slike oppgaver i en uendret, standard tilstand, eller med bare minimal tidligere instruksjon.
Oppgaven som er behandlet i den nye artikkelen, er svært spesifikk for akademisk forskning, men sannsynligvis vil ha en videre innvirkning når tale-AI blir mer utbredt, og når kriminelle elementer som søker å profitere fra AI-basert etterligning, søker å overraske et mønster- offer-pool med en ny vrikel.
* Min konvertering av forfatternes inline-citater til hyperlenker.† Vennligst se den tidligere (ovenfor) resultattabellen – i denne sammenhengen er artikkelen litt over-komprimert.
Først publisert torsdag, 2. april 2026













{kind=link}