Kunstig intelligens
Er DALL-E 2 bare ‘liming ting sammen’ uten å forstå deres relasjoner?

En ny forskningsrapport fra Harvard University antyder at OpenAI’s overskriftsgrabende tekst-til-bilde-rammeverk DALL-E 2 har betydelige vanskeligheter med å gjengi selv infant-nivå-relasjoner mellom elementene det komponerer inn i syntetiske fotos, til tross for den imponerende sofistikerte utgangen av mye av dens utgang.
Forskerne tok en brukerstudie med 169 crowdsourced deltakere, som ble presentert med DALL-E 2-bilder basert på de mest grunnleggende menneskelige prinsippene for relasjonssemantikk, sammen med tekst-promptene som hadde skapt dem. Når de ble bedt om å si om promptene og bildene var relatert, var mindre enn 22% av bildene oppfattet å være pertinente til deres tilhørende prompter, i forhold til de meget enkle relasjoner som DALL-E 2 ble bedt om å visualisere.

A screen-grab fra prøvene som ble utført for den nye rapporten. Deltakerne ble bedt om å velge alle bildene som matchet prompten. Kilde: https://arxiv.org/pdf/2208.00005.pdf
Resultatene antyder også at DALL-E’s åpenbare evne til å kombinere ulike elementer kan avta når disse elementene blir mindre sannsynlige å ha skjedd i den virkelige verden-treningdata som driver systemet.
For eksempel, bilder for prompten ‘barn som berører en skål’ fikk en 87% enighetssrate (dvs. deltakerne klikket på de fleste bildene som relevante for prompten), mens like fotorealistiske gjengivelser av ‘en ape som berører en leguan’ oppnådde bare 11% enighet:


DALL-E sliter med å avbilde den usannsynlige hendelsen av en ‘ape som berører en leguan’, antagelig fordi det er uvanlig, mer sannsynlig ikke-eksisterende, i treningssettet.
I det andre eksemplet, får DALL-E 2 ofte skalaen og selv arten feil, antagelig på grunn av en mangel på virkelige bilder som avbilder denne hendelsen. I motsetning til dette, er det rimelig å forvente et høyt antall treningsbilder relatert til barn og mat, og at denne sub-domenen/klassen er godt utviklet.
DALL-E’s vanskeligheter med å plassere ulike bilelementer sammen suger at publikum for tiden er så imponert over systemets fotorealistiske og bredt tolkende evner at de ikke har utviklet en kritisk øye for tilfeller hvor systemet har effektivt bare ‘limt’ ett element skarpt på et annet, som i disse eksemplene fra den offisielle DALL-E 2-nettsiden:

Kutt-og-lim-syntese, fra de offisielle eksemplene for DALL-E 2. Kilde: https://openai.com/dall-e-2/
Den nye rapporten sier*:
‘Relasjonell forståelse er en grunnleggende komponent av menneskelig intelligens, som manifesterer seg tidlig i utviklingen, og beregnes raskt og automatisk i persepsjonen.
‘DALL-E 2’s vanskeligheter med selv grunnleggende romlige relasjoner (slik som in, on, under) suger at hva det har lært, har det ikke lært de typene representasjoner som tillater mennesker å så fleksibelt og robust strukturere verden.
‘En direkte tolkning av denne vanskeligheten er at systemer som DALL-E 2 ikke ennå har relasjonell komposisjonalitet.’
Forfatterne foreslår at tekst-guidede bilde-genererings-systemer som DALL-E-serien kunne dra nytte av å utnytte algoritmer som er vanlige i robotikk, som modellerer identiteter og relasjoner samtidig, på grunn av behovet for agenten å faktisk interagere med miljøet i stedet for bare å fabrikkere en blanding av ulike elementer.
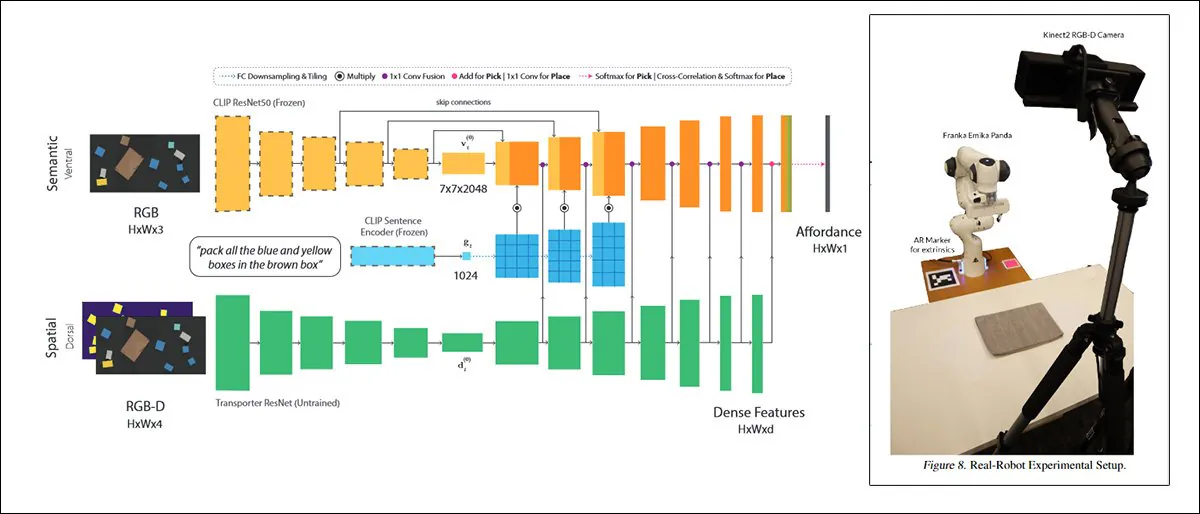
En slik tilnærming, tittelen CLIPort, bruker samme CLIP-mekanisme som tjener som en kvalitetsvurderings-element i DALL-E 2:

CLIPort, et samarbeid mellom University of Washington og NVIDIA i 2021, bruker CLIP i en kontekst så praktisk at systemene trent på det nødvendigvis må utvikle en forståelse av fysiske relasjoner, en motivator som mangler i DALL-E 2 og lignende ‘fantastiske’ bilde-syntese-rammeverk. Kilde: https://arxiv.org/pdf/2109.12098.pdf
Forfatterne foreslår videre at ‘en annen plausibel oppgradering’ kunne være å inkorporere multiplikative effekter i ett enkelt lag av beregning, som tillater beregning av relasjoner på en måte inspirert av informasjonsbehandlingskapasiteter i biologiske systemer.
Den nye rapporten heter Testing Relational Understanding in Text-Guided Image Generation, og kommer fra Colin Conwell og Tomer D. Ullman ved Harvard’s Department of Psychology.
Beyond Early Criticism
Kommentar til ‘sleight of hand’ bak realisme og integritet av DALL-E 2’s utgang, noterer forfatterne tidligere arbeider som har funnet mangler i DALL-E-stil generative bilde-systemer.
I juni dette året, noterte UoC Berkeley vanskelighetene DALL-E har med å håndtere refleksjoner og skygge; samme måned, en studie fra Korea undersøkte ‘uniqueness’ og originalitet av DALL-E 2-stil utgang med en kritisk øye; en preliminær analyse av DALL-E 2-bilder, kort tid etter lansering, fra NYU og University of Texas, fant flere problemer med komposisjonalitet og andre essensielle faktorer i DALL-E 2-bilder; og forrige måned, et felles arbeid mellom University of Illinois og MIT tilbød forslag for arkitektoniske forbedringer til slike systemer i forhold til komposisjonalitet.
Forskerne noterer videre at DALL-E-luminaries som Aditya Ramesh har innrømmet rammeverkets problemer med binding, relativ størrelse, tekst og andre utfordringer.
Utviklerne bak Google’s rival bilde-syntese-system Imagen har også foreslått DrawBench, et nytt sammenligningssystem som måler bilde-nøyaktighet over rammeverk med diverse metrikker.
I stedet foreslår forfatterne av den nye rapporten at en bedre resultater kunne oppnås ved å sette menneskelig estimat – i stedet for intern, algoritmisk metrikker – mot de resulterende bildene, for å etablere hvor svakhetene ligger, og hva som kunne gjøres for å mildne dem.
Studien
For å nå dette, baserer den nye prosjektet sin tilnærming på psykologiske prinsipper, og søker å trekke seg tilbake fra den nåværende bølgen av interesse i prompt-engineering (som i virkeligheten er en innrømmelse av svakhetene i DALL-E 2, eller noen lignende system), for å undersøke og potensielt adresse begrensningene som gjør slike ‘arbeidsomgåelser’ nødvendige.













{kind=link}