Kunstig intelligens
AudioSep : Separer Alt Du Beskriver
LASS eller Language-queried Audio Source Separation er det nye paradigmet for CASA eller Computational Auditory Scene Analysis som har som mål å separere en mållyd fra en gitt blanding av lyd ved hjelp av en naturlig språklig forespørsel som gir en naturlig, men skalerbar grensesnitt for digitale lydoppgaver og -applikasjoner. Selv om LASS-rammeverkene har gjort betydelige fremgang i de siste årene når det gjelder å oppnå ønsket ytelse på bestemte lydkilder som musikkinstrumenter, er de ikke i stand til å separere mållyden i åpen domene.
AudioSep, er et grunnleggende modell som har som mål å løse de nåværende begrensningene i LASS-rammeverkene ved å aktivere mållydseparasjon ved hjelp av naturlige språkforespørsler. Utviklerne av AudioSep-rammeverket har trent modellen omfattende på en stor mengde store multimodale datasett, og har evaluert ytelsen til rammeverket på en rekke lydoppgaver, inkludert separasjon av musikkinstrumenter, lydhendelsesseparasjon og forbedring av tale blant mange andre. Den innledende ytelsen til AudioSep tilfredsstiller benchmarkene, da den viser imponerende nullskuddlæringsmuligheter og leverer sterk lydseparasjonsytelse.
I denne artikkelen vil vi gå dypere inn i hvordan AudioSep-rammeverket fungerer, da vi vil evaluere arkitekturen til modellen, datasettene som ble brukt til trening og evaluering, og de essensielle konseptene som er involvert i AudioSep-modellens funksjon. La oss begynne med en grunnleggende introduksjon til CASA-rammeverket.
CASA, USS, QSS, LASS-rammeverk : Grunnlaget for AudioSep
CASA eller Computational Auditory Scene Analysis-rammeverket er et rammeverk som brukes av utviklere til å designe maskinlyttingssystemer som har evnen til å oppfatte komplekse lydmiljøer på en måte som ligner på hvordan mennesker oppfatter lyd ved hjelp av deres auditoriske systemer. Lydseparasjon, med særlig fokus på mållydseparasjon, er et grunnleggende forskningsområde innenfor CASA-rammeverket, og det har som mål å løse “cocktail party-problemet” eller å separere virkelige lydopptak fra enkeltlydkilder eller -filer. Viktigheten av lydseparasjon kan tilskrives hovedsakelig dens vidstrakte anvendelser, inkludert musikklydseparasjon, lydkilde-separasjon, taleforbedring, mållydidentifikasjon og mye mer.
Det meste av arbeidet med lydseparasjon som er gjort i fortiden dreier seg hovedsakelig om separasjon av en eller flere lydkilder, som musikkseparasjon eller taleseparasjon. En ny modell som kalles USS eller Universal Sound Separation har som mål å separere vilkårlige lyder i virkelige lydopptak. Imidlertid er det en utfordrende og begrensende oppgave å separere hver lydkilde fra en lydblanding, hovedsakelig på grunn av den store mengden forskjellige lydkilder som eksisterer i verden, som er den viktigste grunnen til at USS-metoden ikke er gjennomførbar for virkelige anvendelser som fungerer i sanntid.
En gjennomførbar alternativ til USS-metoden er QSS eller Query-based Sound Separation-metoden som har som mål å separere en enkelt eller mållydkilde fra lydblandingen basert på en bestemt sett med forespørsler. Takket være dette, tillater QSS-rammeverket utviklere og brukere å trekke ut de ønskede lydkildene fra blandingen basert på deres krav, noe som gjør QSS-metoden til en mer praktisk løsning for digitale virkelige anvendelser som multimediaredigering eller lydredigering.
Videre har utviklere nylig foreslått en utvidelse av QSS-rammeverket, LASS-rammeverket eller Language-queried Audio Source Separation-rammeverket som har som mål å separere vilkårlige lydkilder fra en lydblanding ved å bruke naturlige språkbeskrivelser av mållydkilden. Da LASS-rammeverket tillater brukere å trekke ut mållydkildene ved hjelp av en sett med naturlige språkforespørsler, kan det bli et kraftig verktøy med vidstrakte anvendelser i digitale lydanvendelser. Når det sammenlignes med tradisjonelle lyd- eller visuelt forespørte metoder, tilbyr bruk av naturlige språkforespørsler for lydseparasjon en større grad av fordeler, da det legger til fleksibilitet og gjør innhenting av forespørselsinformasjon mye enklere og mer praktisk. Videre, når det sammenlignes med etikett-forespørsel-basert lydseparasjonsrammeverk som bruker en forhåndsdefinert sett med instruksjoner eller forespørsler, begrenser ikke LASS-rammeverket antallet innputtforespørsler, og har fleksibiliteten til å generaliseres til åpen domene uten problemer.
Opprinnelig baserer LASS-rammeverket seg på overvåket læring, hvor modellen blir trent på en sett med merket lyd-tekst-par-data. Imidlertid er hovedproblemet med denne tilnærmingen den begrensede tilgjengeligheten av annotert og merket lyd-tekst-data. For å redusere avhengigheten av LASS-rammeverket til annotert lyd-tekst-merket data, blir modellene trent ved hjelp av multimodal overvåket læringstilnærming. Hovedmålet bak å bruke en multimodal overvåket tilnærming er å bruke multimodal kontrastiv forhånds-trening-modeller som CLIP eller Contrastive Language Image Pre-training-modellen som forespørselskoderen for rammeverket. Da CLIP-rammeverket har evnen til å justere tekst-utbedringer med andre modaliteter som lyd eller visuell, tillater det utviklere å trene LASS-modellene ved hjelp av data-rike modaliteter, og tillater interferensen med tekstdata i en nullskudd-innstilling. De nåværende LASS-rammeverkene bruker imidlertid små-skala-datasett for trening, og anvendelser av LASS-rammeverket på hundrevis av potensielle domener er ennå ikke utforsket.
For å løse de nåværende begrensningene som LASS-rammeverkene møter, har utviklere introdusert AudioSep, et grunnleggende modell som har som mål å separere lyd fra en lydblanding ved hjelp av naturlige språkbeskrivelser. Fokus for AudioSep er nå å utvikle en forhånds-trent lydseparasjonsmodell som utnytter eksisterende store multimodale datasett for å aktivere generalisering av LASS-modeller i åpen-domene-anvendelser. For å sammenfatte, er AudioSep-modellen: “En grunnleggende modell for universell lydseparasjon i åpen domene ved hjelp av naturlige språkforespørsler eller beskrivelser trent på store multimodale datasett”.
AudioSep : Nøkkelkomponenter og Arkitektur
Arkitekturen til AudioSep-rammeverket består av to nøkkelkomponenter: en tekstkoderer og en separasjonsmodell.
Tekstkodereren
AudioSep-rammeverket bruker en tekstkoderer fra CLIP eller Contrastive Language Image Pre-training-modellen eller CLAP eller Contrastive Language Audio Pre-training-modellen for å trekke ut tekst-utbedringer fra en naturlig språkforespørsel. Inndata-tekstforespørselen består av en sekvens av “N” token som blir prosessert av tekstkodereren for å trekke ut tekst-utbedringer for den gitte inndata-språkforespørselen. Tekstkodereren bruker en stabel av transformer-blokker for å kode inndata-teksttoken, og utgangsrepresentasjonene blir aggregert etter at de blir sendt gjennom transformer-lagene som resulterer i utviklingen av en D-dimensjonal vektorrepresentasjon med fast lengde, hvor D korresponderer til dimensjonene til CLAP eller CLIP-modellene, mens tekstkodereren er frozen under trening.
CLIP-modellen er forhånds-trent på et stort datasett av bilde-tekst-par-data ved hjelp av kontrastiv læring, som er hovedgrunnen til at dens tekstkoderer lærer å kartlegge tekstbeskrivelser på det semantiske rommet som også deles av visuelle representasjoner. Fordelen AudioSep får ved å bruke CLIPs tekstkoderer er at den kan nå skaleres opp eller trenes fra ubrukte lyd-visuelle data ved hjelp av visuelle utbedringer som en alternativ, noe som aktiverer trening av LASS-modeller uten krav til annotert eller merket lyd-tekst-data.
CLAP-modellen fungerer likt CLIP-modellen og bruker en tekst- og en lydkoderer for å koble lyd og språk, noe som bringer tekst- og lyd-beskrivelser på et lyd-tekst-latent rom sammen.
Separasjonsmodell
AudioSep-rammeverket bruker en frekvens-domene ResUNet-modell som blir matet med en blanding av lydklipp som separasjonsryggraden for rammeverket. Rammeverket fungerer ved å først bruke en STFT eller en Short-Time Fourier Transform på bølgeformen for å trekke ut et komplekst spektrogram, et magnitude-spektrogram og fasen til X. Modellen følger deretter samme innstilling og konstruerer en encoder-decoder-nettverk for å prosessere magnitude-spektrogrammet.
ResUNet-encoder-decoder-nettverket består av 6 residual-blokker, 6 decoder-blokker og 4 flaskehalse-blokker. Spektrogrammet i hver encoder-blokk bruker 4 residual-konvolusjonsblokker for å nedsample seg selv til en flaskehalse-egenskap, mens decoder-blokkene bruker 4 residual-dekonvolusjonsblokker for å få separasjonskomponenter ved å oppsample egenskapene. Etter dette etablerer hver av encoder-blokkene og deres korresponderende decoder-blokker en hoppeforbindelse som opererer på samme oppsamplings- eller nedsamplingsrate. Residual-blokkene i rammeverket består av 2 Leaky-ReLU-aktiveringslag, 2 batch-normaliseringslag og 2 CNN-lag, og videre introduserer rammeverket en ekstra residual-gjennomgang som kobler inndata og utdata av hver enkelt residual-blokk. ResUNet-modellen tar det komplekse spektrogrammet X som inndata og produserer magnitude-masken M som utdata med faseresiduum som er betinget av tekst-utbedringer som kontrollerer størrelsen på skala og rotasjon av vinkelen til spektrogrammet. Det separerte komplekse spektrogrammet kan deretter trekkes ut ved å multiplisere den predikerte magnitude-masken og faseresiduum med STFT (Short-Time Fourier Transform) til blandingen.

I sitt rammeverk bruker AudioSep en FiLm eller Feature-wise Linearly modulert lag for å koble separasjonsmodellen og tekstkodereren etter deployeringen av konvolusjonsblokkene i ResUNet.
Trening og Tap
Under treningen av AudioSep-modellen, bruker utviklerne støyforsterkningsmetoden og trener AudioSep-rammeverket fra ende til ende ved hjelp av en L1-tap-funksjon mellom grunn-sannheten og den predikerte bølgeformen.
Datasett og Benchmark
Som nevnt i tidligere avsnitt, er AudioSep et grunnleggende modell som har som mål å løse den nåværende avhengigheten av LASS-modeller til annotert lyd-tekst-par-data. AudioSep-modellen blir trent på en rekke datasett for å utstyre den med multimodale læringsmuligheter, og her er en detaljert beskrivelse av datasettet og benchmarkene som blir brukt av utviklerne til å trene AudioSep-rammeverket.
AudioSet
AudioSet er et svakt-merket stort datasett som består av over 2 millioner 10-sekunders lydklipp som er trukket direkte fra YouTube. Hver lydklipp i AudioSet-datasett er kategorisert av fraværet eller nærværet av lydklasser uten de spesifikke tidspunktene for lydhendelsene. AudioSet-datasett har over 500 distinkte lydklasser, inkludert naturlige lyder, menneskelige lyder, kjøretøylyder og mye mer.
VGGSound
VGGSound-datasett er et stort visuelt-lyd-datasett som, likt AudioSet, er trukket direkte fra YouTube, og det inneholder over 200 000 video-klipper, hver av dem med en varighet på 10 sekunder. VGGSound-datasett er kategorisert i over 300 lydklasser, inkludert menneskelige lyder, naturlige lyder, fuglelyder og mye mer. Bruken av VGGSound-datasett sikrer at objektet som er ansvarlig for å produsere mållyden også er beskrivelig i den korresponderende visuelle klippet.
AudioCaps
AudioCaps er det største offentlig tilgjengelige lyd-beskrivelsesdatasettet, og det består av over 50 000 10-sekunders lydklipp som er trukket fra AudioSet-datasett. Dataene i AudioCaps er delt inn i tre kategorier: treningdata, testdata og valideringsdata, og lydklippene er menneskelige-annotert med naturlige språkbeskrivelser ved hjelp av Amazon Mechanical Turk-plattformen. Det er verdt å merke seg at hver lydklipp i treningssettet har en enkelt beskrivelse, mens dataene i test- og valideringsettene hver har 5 grunn-sannhets-beskrivelser.
ClothoV2
ClothoV2 er et lyd-beskrivelsesdatasett som består av klipp trukket fra FreeSound-plattformen, og likt AudioCaps, er hver lydklipp menneskelige-annotert med naturlige språkbeskrivelser ved hjelp av Amazon Mechanical Turk-plattformen.
WavCaps
Likt AudioSet, er WavCaps et svakt-merket stort lyd-datasett som består av over 400 000 lydklipp med beskrivelser, og en total kjøretid som nærmer seg 7568 timer med treningdata. Lydklippene i WavCaps-datasett er trukket fra en rekke lydkilder, inkludert BBC Sound Effects, AudioSet, FreeSound, SoundBible og mye mer.

Treningdetaljer
Under treningfasen, tilfeldig sampler AudioSep-modellen to lydsegmenter trukket fra to forskjellige lydklipp fra treningdatasett, og deretter blander dem sammen for å skape en treningssammenblanding hvor lengden av hver lydsegment er omtrent 5 sekunder. Modellen trekker deretter det komplekse spektrogrammet fra bølgeformssignalet ved hjelp av et Hann-vindu på størrelse 1024 med en hoppe-størrelse på 320.
Modellen bruker deretter tekstkodereren til CLIP/CLAP-modellene for å trekke ut tekst-utbedringer med tekst-overvåking som standardkonfigurasjon for AudioSep. For separasjonsmodellen, bruker AudioSep-rammeverket en ResUNet-lag bestående av 30 lag, 6 encoder-blokker og 6 decoder-blokker som ligner på arkitekturen som følges i universell lydseparasjon-rammeverket. Videre har hver encoder-blokk to konvolusjonslag med en 3×3 kernel-størrelse, med antallet utgangs-egenskapskarter i encoder-blokkene som er 32, 64, 128, 256, 512 og 1024 henholdsvis. Decoder-blokkene deler symmetri med encoder-blokkene, og utviklerne bruker Adam-optimizer for å trene AudioSep-modellen med en batch-størrelse på 96.
Evalueringresultater
På sett datasett
Følgende figur sammenligner ytelsen til AudioSep-rammeverket på sett datasett under treningfasen, inkludert treningdatasettene. Den nedenfor figur representerer benchmark-evalueringresultatene til AudioSep-rammeverket når sammenlignet mot basissystemer, inkludert taleforbedringsmodeller, LASS og CLIP. AudioSep-modellen med CLIP-tekstkoderer er representert som AudioSep-CLIP, mens AudioSep-modellen med CLAP-tekstkoderer er representert som AudioSep-CLAP.

Som det kan ses i figuren, fungerer AudioSep-rammeverket godt når det bruker lyd-beskrivelser eller tekst-etiketter som inndata-forespørsler, og resultatene indikerer den overlegne ytelsen til AudioSep-rammeverket når sammenlignet mot tidligere benchmark LASS og lyd-forespørslet lydseparasjonsmodeller.
På usett datasett
For å vurdere ytelsen til AudioSep i en nullskudd-innstilling, fortsatte utviklerne å evaluere ytelsen på usett datasett, og AudioSep-rammeverket leverer imponerende separasjonsytelse i en nullskudd-innstilling, og resultatene vises i figuren nedenfor.

Videre viser bildet nedenfor resultatene av å evaluere AudioSep-modellen mot Voicebank-Demand taleforbedring.

Evalueringen av AudioSep-rammeverket indikerer en sterk og ønsket ytelse på usett datasett i en nullskudd-innstilling, og åpner dermed for å utføre lydoperasjonsoppgaver på nye datafordelinger.
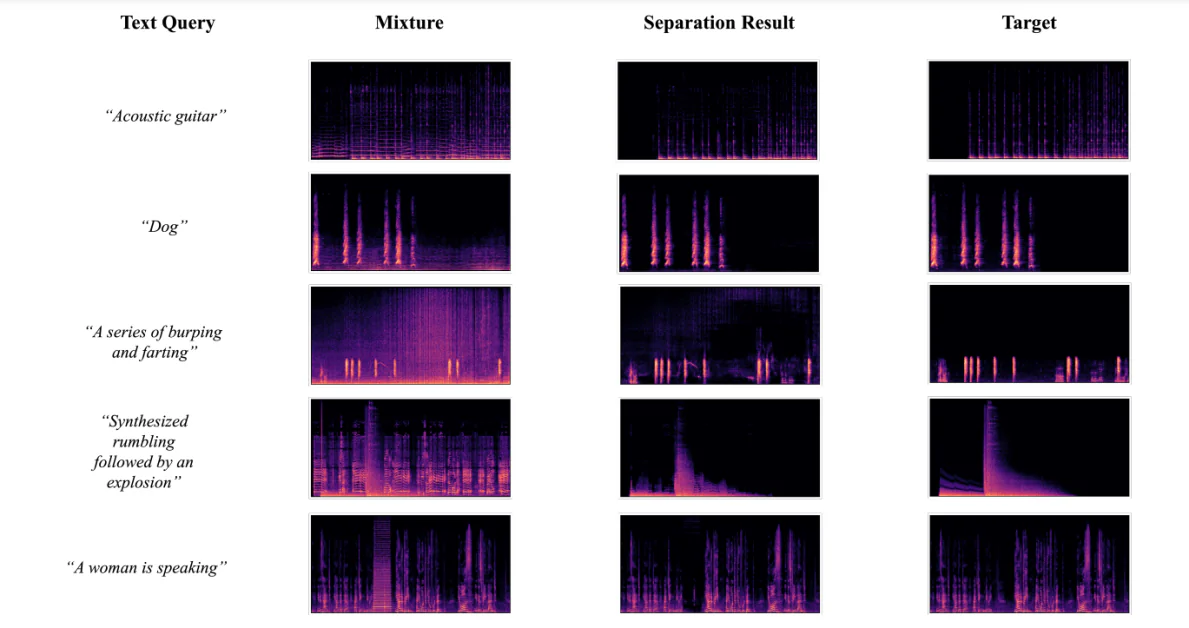
Visualisering av separasjonsresultater
Figuren nedenfor viser resultatene som blir fått når utviklerne bruker AudioSep-CLAP-rammeverket for å utføre visualiseringer av spektrogrammer for grunn-sannhets-mållydkilder, lydblandinger og separerte lydkilder ved hjelp av tekst-forespørsler av diverse lyder eller lyder. Resultatene tillot utviklerne å observere at separert kilde-mønster i spektrogrammet er nær kilde til grunn-sannheten, noe som støtter de objektive resultatene som ble funnet under eksperimentene.
Sammenligning av tekst-forespørsler
Utviklerne evaluerer ytelsen til AudioSep-CLAP og AudioSep-CLIP på AudioCaps Mini, og utviklerne bruker AudioSet-hendelses-etiketter, AudioCaps-beskrivelser og re-annoterte naturlige språkbeskrivelser for å undersøke effektene av forskjellige forespørsler, og figuren nedenfor viser et eksempel på AudioCaps Mini i aksjon.

Konklusjon
AudioSep er et grunnleggende modell som er utviklet med målet om å være et åpen-domene universelt lydseparasjonsrammeverk som bruker naturlige språkbeskrivelser for lydseparasjon. Som observert under evalueringen, er AudioSep-rammeverket i stand til å utføre nullskudd- og uovervåket læring uten problemer ved hjelp av lyd-beskrivelser eller tekst-etiketter som forespørsler. Resultatene og evalueringen av AudioSep indikerer en sterk ytelse som overgår nåværende tilstand av kunstig intelligens-lydseparasjonsrammeverk som LASS, og det kan være i stand til å løse de nåværende begrensningene til populære lydseparasjonsrammeverk.












