Kunstig intelligens
Endring av Emosjoner i Videofiler med AI

Forskere fra Hellas og Storbritannia har utviklet en ny dyp læringsteknikk for å endre uttrykk og åpenbar stemning hos mennesker i videofiler, samtidig som de bevare trofastheten til deres leppebevegelser i forhold til den opprinnelige lyden på en måte som tidligere forsøk ikke har kunnet matche.

Fra videoen som følger med artikkelen (innbetatt i slutten av denne artikkelen), en kort klipp av skuespiller Al Pacino som får sitt uttrykk subtant endret av NED, basert på høynivåsemantiske konsepter som definerer enkeltansiktuttrykk, og deres assosierte emosjon. ‘Reference-Driven’-metoden til høyre tar den tolkede emosjonen fra en kildevideo og anvender den på hele en videosekvens. Kilde: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Dette spesifikke felt hører inn under den voksende kategorien deepfaked emotions, hvor identiteten til den opprinnelige taleren bevares, men deres uttrykk og mikro-uttrykk endres. Ettersom denne spesifikke AI-teknologien modnes, åpner den muligheter for film- og TV-produksjoner å gjøre subtile endringer i skuespilleres uttrykk – men åpner også opp en ganske ny kategori av ’emosjonsendrede’ video deepfakes.
Endring av Ansikter
Ansiktsuttrykk for offentlige personer, som politikere, er nøye kuratert; i 2016 kom Hillary Clintons ansiktsuttrykk under intens mediegransking for deres potensielle negative innvirkning på hennes valgmuligheter; ansiktsuttrykk, det viser seg, er også et emne av interesse for FBI; og de er en kritisk indikator i jobintervjuer, gjør det (fjerne) perspektivet av en live ‘uttrykkskontrollfilter’ en ønskelig utvikling for jobbsøkere som prøver å bestå en forhåndsvisning på Zoom.
En studie fra 2005 fra Storbritannia hevdet at ansiktsutseende påvirker valgavgjørelser, mens en artikkel i Washington Post fra 2019 undersøkte bruk av ‘uten sammenheng’ video klippdeling, som for øyeblikket er det nærmeste man kommer til å kunne endre hvordan en offentlig person ser ut til å oppføre seg, reagere eller føle.
Mot Neuralt Uttrykksmanipulasjon
For øyeblikket er tilstanden for å manipulere ansiktsuttrykk ganske rudimentær, siden det innebærer å takle disentanglement av høynivåkonsepter (slik som ledig, sinna, glad, smil) fra faktisk videoinnhold. Selv om tradisjonelle deepfake-arkitekturer ser ut til å oppnå denne disentanglementen ganske bra, krever speiling av emosjoner over forskjellige identiteter at to treningsansiktsett inneholder matchende uttrykk for hver identitet.

Typiske eksempler på ansiktsbilder i datasett brukt til å trene deepfakes. For øyeblikket kan du bare manipulere en persons ansiktsuttrykk ved å opprette ID-spesifikke uttrykk-til-uttrykk-veier i en deepfake neuralt nettverk. 2017-æras deepfake-programvare har ingen intrinsisk, semantisk forståelse av et ‘smil’ – det kartlegger og matcher bare oppfattede endringer i ansiktsgeometri over de to subjektene.
Hva som er ønskelig, og som ikke har blitt fullt oppnådd, er å gjenkjenne hvordan subjekt B (for eksempel) smiler, og bare opprette en ‘smil’-bryter i arkitekturen, uten å måtte kartlegge det til en ekvivalent bilde av subjekt A som smiler.
Den nye artikkelen har tittelen Neuralt Emosjonsdirektør: Tale-bevarende semantisk kontroll av ansiktsuttrykk i “i-feltet” videoer, og kommer fra forskere ved Skolen for elektroteknikk og datateknikk ved Det nasjonale tekniske universitet i Athen, Institutt for datateknikk ved Foundation for Research and Technology Hellas (FORTH), og College of Engineering, Mathematics and Physical Sciences ved University of Exeter i Storbritannia.
Teamet har utviklet en ramme kalt Neuralt Emosjonsdirektør (NED), som inkorporerer et 3D-basert emosjonsoversettelsesnettverk, 3D-basert Emosjonsmanipulator.
NED tar en mottatt sekvens av uttrykksparametere og oversetter dem til et målområde. Det er trent på uparallelt data, noe som betyr at det ikke er nødvendig å trene på datasett hvor hver identitet har tilsvarende ansiktsuttrykk.
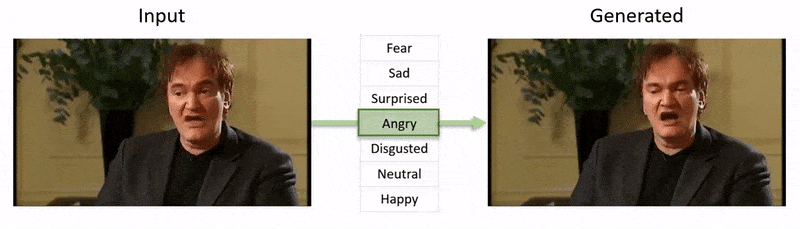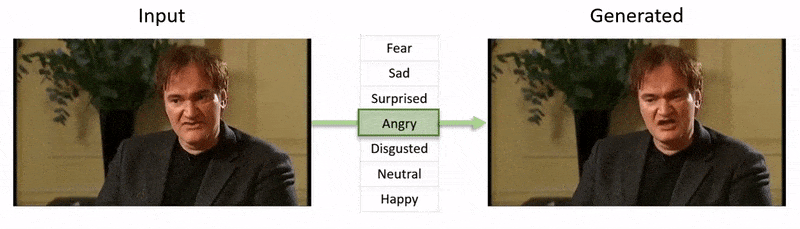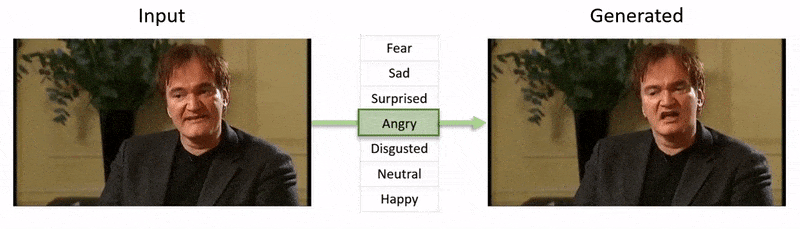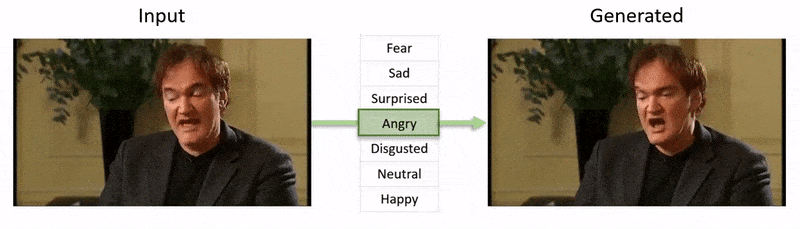
Videoen, vist i slutten av denne artikkelen, går gjennom en rekke tester hvor NED påfører en åpenbar emosjonal tilstand på videoer fra YouTube-datasettet.
Forfatterne hevder at NED er den første video-baserte metoden for ‘instruksjon’ av skuespillere i tilfeldige og uforutsigbare situasjoner, og har gjort koden tilgjengelig på NEDs prosjektside.
Metode og Arkitektur
Systemet er trent på to store videodatasett som har blitt annotert med ’emosjon’-etiketter.
Utdataene aktiveres av en videoansiktsrenderer som renderer den ønskede emosjonen til video ved hjelp av tradisjonelle ansiktsbildesynthese-teknikker, inkludert ansiktssegmentering, ansiktslandmerkejustering og blanding, hvor bare ansiktsområdet syntetiseres, og deretter påføres den opprinnelige filmen.

Arkitekturen for pipeline til Neuralt Emosjonsdetektor (NED). Kilde: https://arxiv.org/pdf/2112.00585.pdf
Først får systemet 3D-ansiktsrekonstruksjon og påfører ansiktslandmerkejusteringer på inndata-rammene for å identifisere uttrykket. Etter dette blir de gjenvunne uttrykksparametrene overført til 3D-basert Emosjonsmanipulator, og en stilvektor beregnes ved hjelp av enten en semantisk etikett (slik som ‘glad’) eller ved en referansefil.
En referansefil er en video som fremstiller en bestemt gjenkjent uttrykk/emosjon, som deretter påføres hele målvideoen, og bytter ut det opprinnelige uttrykket.

Stadier i emosjons-overføringspipeline, med ulike skuespillere sampet fra YouTube-videofiler.
Den endelige genererte 3D-ansiktsformen blir deretter konkatenerert med Normalisert Gjennomsnittlig Ansiktskoordinat (NMFC) og øye-bildene (de røde prikkene i bildet over), og overført til neuralt renderer, som utfører den endelige manipulasjonen.
Resultater
Forskerne utførte omfattende studier, inkludert bruker- og ablasjonsstudier, for å evaluere effektiviteten av metoden mot tidligere arbeid, og fant at i de fleste kategorier, NED overgår den nåværende tilstanden for kunst i denne undersektoren av neuralt ansiktsmanipulasjon.

Artikkelforfatterne forestiller seg at senere implementeringer av dette arbeidet, og verktøy av en lignende natur, vil være nyttige primært i TV- og filmindustrien, og uttaler:
‘Vår metode åpner en mengde nye muligheter for nyttige anvendelser av neurale rendringsteknologier, fra film-postproduksjon og videospill til fotorealistiske emosjonelle avatarer.’
Dette er et tidlig arbeid på feltet, men ett av de første som forsøker å gjøre ansikts-gjenoppbygging med video i stedet for stillbilder. Selv om videoer i virkeligheten er mange stillbilder som løper sammen svært raskt, er det temporale overveielser som gjør tidligere anvendelser av emosjons-overføring mindre effektive. I den medfølgende videoen og eksemplene i artikkelen, inkluderer forfatterne visuelle sammenligninger av NEDs utdata mot andre sammenlignbare metoder.

Mer detaljerte sammenligninger, og mange flere eksempler på NED, kan finnes i den fulle videoen nedenfor:
3. desember 2021, 18:30 GMT+2 – Ved forespørsel fra en av artikkelforfatterne, ble korreksjoner gjort med hensyn til ‘referansefilen’, som jeg feilaktig bemerket var et stillbilde (når det i virkeligheten er en video klipp). Også en korreksjon av navnet på Institutt for datateknikk ved Foundation for Research and Technology.
3. desember 2021, 20:50 GMT+2 – En andre forespørsel fra en av artikkelforfatterne for en ytterligere korreksjon av navnet på ovennevnte institusjon.












