Kunstig intelligens
AI hjelper nervøse talere til å ‘lese rommet’ under videokonferanser

I 2013 bestemte en undersøkelse om vanlige fobier at utsikten til offentlig tale var verre enn utsikten til død for de fleste respondentene. Syndromet er kjent som glossofobi.
Den COVID-drevne migrasjonen fra ‘personlige’ møter til online Zoom-konferanser på plattformer som Zoom og Google Spaces har, overraskende nok, ikke forbedret situasjonen. Når møtet inneholder et stort antall deltakere, blir våre naturlige trusselvurderingsferdigheter hemmet av de lavoppløste radene og ikonene til deltakerne, og vanskeligheten med å lese subtile visuelle signaler fra ansiktsuttrykk og kroppsspråk. Skype, for eksempel, er blitt funnet å være en dårlig plattform for å formidle ikke-verbale signaler.
Effekten av offentlig taleprestasjon på oppfattet interesse og respons er godt dokumentert nå, og intuitivt åpenbart for de fleste av oss. Uklar publikumsrespons kan få talerne til å nøle og falle tilbake til fyllespråk, uvitende om hvorvidt deres argumenter møter med enighet, forakt eller likegyldighet, ofte gjør det til en ubehagelig opplevelse for både taleren og deres tilhørere.
Under press fra den uventede skiftet mot online videokonferanser inspirert av COVID-begrensninger og forsiktighetsmessige tiltak, er problemet arguabelt blir verre, og en rekke lindrende publikumsresponsordninger har blitt foreslått i datavisnings- og affektforskningsmiljøene de siste par årene.
Maskinvare-fokuserte løsninger
De fleste av disse, imidlertid, involverer ekstra utstyr eller kompleks programvare som kan reise privatlivs- eller logistiske problemer – relativt høykostnads- eller ressursbegrensede tilnærmingssmetter som forhåndsgår pandemien. I 2001 foreslo MIT Galvactivator, en håndbårent enhet som sluttrer den emosjonelle tilstanden til publikum, testet under en dagslang symposium.

Fra 2001, MITs Galvactivator, som målte hudledningssvar i et forsøk på å forstå publikums mening og engasjement. Kilde: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
En stor del akademisk energi har også blitt viet til den mulige utplasseringen av ‘klikkere’ som et Publikumsresponsystem (ARS), en måte å øke aktiv deltakelse fra publikum (som automatisk øker engasjement, siden det tvinger seeren inn i rollen som en aktiv tilbakemeldingsknute), men som også har blitt forestilt som en måte å oppmuntre talere.
Andre forsøk på å ‘koble’ taler og publikum har inkludert hjerte-ratemåling, bruk av kompleks kropps-båret utstyr for å utnytte elektroensefalografi, ‘jubel-mål’, datavisjons-basert emosjons-gjenkjenning for skrivebords-arbeidere, og bruk av publikum-sendte emotikoner under talerens tale.

Fra 2017, EngageMeter, et felles akademisk forskningsprosjekt fra LMU München og Universitetet i Stuttgart. Kilde: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Som en under-etablering av det lukrative området publikumsanalyse, har den private sektoren tatt en særlig interesse i blikkestimering og -sporings-systemer – systemer hvor hvert publikum-medlem (som måtte til slutt selv måtte tale), er underlagt okulær sporings som en indeks for engasjement og godkjenning.
Alle disse metodene er ganske høy-friksjons. Mange av dem krever ekstra utstyr, laboratoriemiljøer, spesialiserte og tilpassede programvare-rammeverk, og abonnement på dyre kommersielle API-er – eller noen kombinasjon av disse begrensede faktorene.
Derfor har utviklingen av minimalistiske systemer basert på lite mer enn vanlige verktøy for videokonferanser blitt av interesse de siste 18 månedene.
Rapportering av publikums godkjenning diskret
Til dette formålet, tilbyr et nytt forsknings-samarbeid mellom Universitetet i Tokyo og Carnegie Mellon Universitet et nytt system som kan piggy-backe på standard videokonferanse-verktøy (som Zoom) ved å bruke bare en web-kamera-aktivert nettside hvor lett gaze- og pose-estimerings-programvare kjører. På denne måten unngås også behovet for lokale nettleser-utvidelser.
Brukerens nikking og estimerte øye-oppmerksomhet oversettes til representativ data som visualiseres tilbake til taleren, og tillater en ‘live’ lakmus-test av hvorvidt innholdet engasjrer publikum – og også minst en vag indikator for perioder av diskurs hvor taleren kan tape publikums interesse.
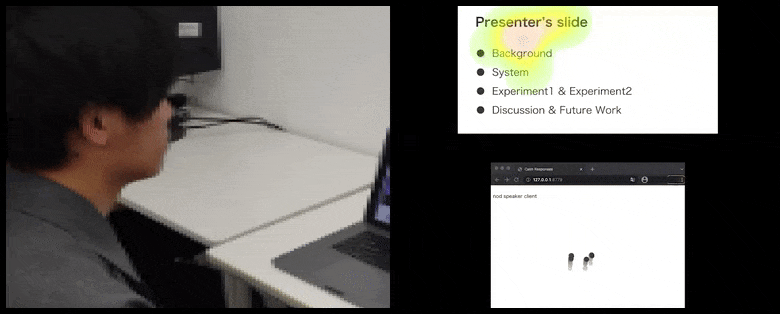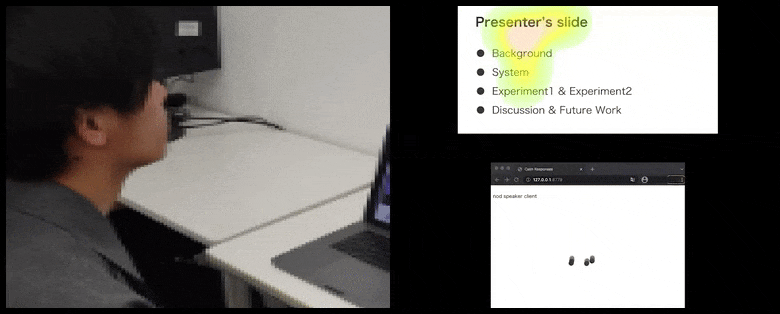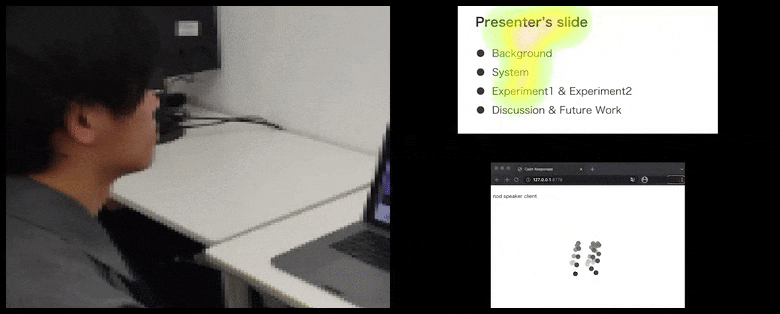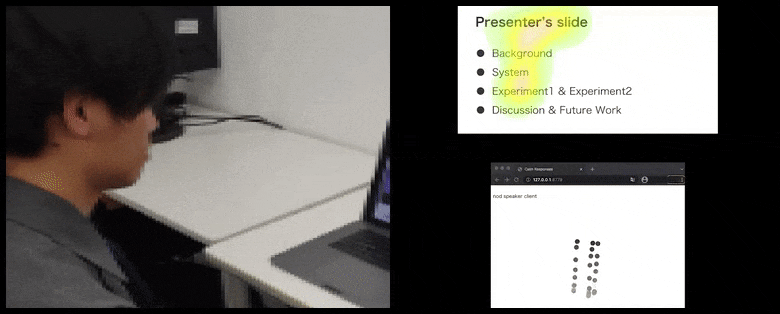
Med CalmResponses, legges bruker-oppmerksomhet og nikking til en pool av publikums-tilbakemelding og oversettes til en visuell representasjon som kan være til nytte for taleren. Se innlejret video på slutten av artikkelen for mer detalj og eksempler. Kilde: https://www.youtube.com/watch?v=J_PhB4FCzk0
I mange akademiske situasjoner, som online-forelesninger, kan studentene være helt usynlige for taleren, siden de ikke har slått på kameraene sine på grunn av selvbevissthet omkring bakgrunnen eller nåværende utseende. CalmResponses kan håndtere denne ellers tornefulle hindring for taler-tilbakemelding ved å rapportere hva det vet om hvordan taleren ser på innholdet, og om de nikker, uten noen behov for seeren å aktivere kameraet.
Den artikkelen er tittel CalmResponses: Visning av kollektive publikums-reaksjoner i fjernkommunikasjon, og er et felles arbeid mellom to forskere fra UoT og en fra Carnegie Mellon.
Forfatterne tilbyr en live web-basert demo, og har sluppet kildekoden på GitHub.
CalmResponses-rammeverket
CalmResponses’ interesse for nikking, i motsetning til andre mulige disposisjoner av hodet, er basert på forskning (noen av det går tilbake til Darwin-æraen) som indikerer at mer enn 80% av alle lytteres hodebevegelser består av nikking (selv når de uttrykker uenighet). Samtidig har øye-bevegelser blitt vist over mange studier å være en pålitelig indeks for interesse eller engasjement.
CalmResponses er implementert med HTML, CSS og JavaScript, og består av tre undersystemer: en publikums-klient, en taler-klient og en server. Publikums-klienten sender øye-gaze- eller hodebevegelsesdata fra brukerens webkamera via WebSockets over sky-plattformen Heroku.

Publikums-nikking visualisert på høyre side i en animert bevegelse under CalmResponses. I dette tilfelle er bevegelses-visualiseringen tilgjengelig ikke bare for taleren, men for hele publikum. Kilde: https://arxiv.org/pdf/2204.02308.pdf
For øye-sporings-delen av prosjektet, brukte forskerne WebGazer, et lettvekt, JavaScript-basert nettleser-basert øye-sporings-rammeverk som kan kjøre med lav forsinkelse direkte fra en nettside (se link ovenfor for forskernes egen web-basert implementering).
Ettersom behovet for enkel implementering og grov, aggregert respons-gjenkjenning veier tyngre enn behovet for høy nøyaktighet i gaze- og pose-estimering, glattes inndata-pose-data i henhold til gjennomsnittsverdier før de blir vurdert for den samlede respons-estimeringen.
Nikke-handlingen blir vurdert via JavaScript-biblioteket clmtrackr, som passer ansiktsmodeller til detekterte ansikter i bilder eller videoer gjennom regulert landmerke-gjennomsnitt. For formål av økonomi og lav-forsinkelse, overvåkes bare det detekterte landmerket for nesen aktivt i forfatternes implementering, siden dette er nok til å spore nikke-handlinger.
Bevegelsen av brukerens nese-spiss-posisjon skaper en spor som bidrar til puljen av publikums-tilbakemelding relatert til nikking, visualisert på en aggregert måte for alle deltakere.
Varmekart
Mens nikke-aktiviteten representeres av dynamiske bevegelser (se bilder ovenfor og video på slutten), rapporteres visuell oppmerksomhet i form av et varmekart som viser taleren og publikum hvor den generelle lokus av oppmerksomhet er fokusert på den delte presentasjonsskjermen eller video-konferanse-miljøet.

Alle deltakere kan se hvor generell bruker-oppmerksomhet er fokusert. Artikkelen nevner ikke om denne funksjonaliteten er tilgjengelig når brukeren kan se en ‘galleri’ av andre deltakere, som kunne avsløre tvilsom fokus på en bestemt deltaker, av ulike årsaker.
Tester
To test-miljøer ble formulert for CalmResponses i form av en underforstått ablasjon-studie, med tre varierende sett av omstendigheter: i ‘Betingelse B’ (basis), repliserte forfatterne en typisk online-student-forelesning, hvor de fleste studenter holder webkameraene sine slått av, og taleren har ingen mulighet til å se ansiktene til publikum; i ‘Betingelse CR-E’, kunne taleren se gaze-tilbakemelding (varmekart); i ‘Betingelse CR-N’, kunne taleren se både nikke- og gaze-aktivitet fra publikum.
Det første eksperiment-scenariet bestod av betingelse B og betingelse CR-E; det andre bestod av betingelse B og betingelse CR-N. Tilbakemelding ble mottatt fra både talerne og publikum.
I hvert eksperiment, ble tre faktorer evaluert: objektiv og subjektiv evaluering av presentasjonen (inkludert en selv-rapportert spørreskjema fra taleren om hvordan presentasjonen gikk); antall hendelser av ‘fyllespråk’, som er et tegn på midlertidig usikkerhet og tøven; og kvalitative kommentarer. Disse kriteriene er vanlige estimatoren av talekvalitet og taler-angst.
Test-puljen bestod av 38 personer i alderen 19-44, bestående av 29 menn og ni kvinner med en gjennomsnittsalder på 24,7, alle japanske eller kinesiske, og alle flytende i japansk. De ble tilfeldig delt inn i fem grupper på 6-7 deltakere, og ingen av subjektene kjente hverandre personlig.
Testene ble utført på Zoom, med fem talere som holdt presentasjoner i det første eksperimentet og seks i det andre.

Fyllespråk-betingelser merket som oransje bokser. Generelt, fyllespråk-innhold falt i rimelig proporsjon til økt publikums-tilbakemelding fra systemet.
Forskerne bemerker at en av talernes fyllespråk reduerte merkbar, og at i ‘Betingelse CR-N’, taleren sjelden uttalte fyllespråk. Se artikkelen for de meget detaljerte og granulerte resultater som rapporteres; imidlertid, de mest merkede resultater var i subjektiv evaluering fra talerne og publikums-deltakerne.
Kommentarer fra publikum inkluderte:
‘Jeg følte at jeg var involvert i presentasjonene” [AN2], “Jeg var ikke sikker på om talernes taler var forbedret, men jeg følte en følelse av enhet fra andres hodebevegelser-visualisering.’ [AN6]
‘Jeg var ikke sikker på om talernes taler var forbedret, men jeg følte en følelse av enhet fra andres hodebevegelser-visualisering.’
Forskerne bemerker at systemet introduserer en ny type kunstig pause i talerens presentasjon, siden taleren er tilbøyelig til å referere til det visuelle systemet for å vurdere publikums-tilbakemelding før de fortsetter videre.
De bemerker også en type ‘hvit-kåt-effekt’, vanskelig å unngå i eksperimentelle omstendigheter, hvor noen deltakere følte seg begrensede av de mulige sikkerhets-implikasjonene av å bli overvåket for biometriske data.
Konklusjon
En merkbart fordel i et system som dette er at alle de ikke-standard-tilleggs-teknologiene som trengs for en slik tilnærming forsvinner helt etter at de er brukt. Det er ingen residual nettleser-utvidelser som må avinstalleres, eller som kan vekke tvil i deltakernes sinn om hvorvidt de skal forbli på deres respektive systemer; og det er ingen behov for å guide brukerne gjennom prosessen med installasjon (selv om web-basert-rammeverket krever en minutt eller to med initial kalibrering fra brukeren), eller å navigere muligheten for at brukerne ikke har tilstrekkelig tillatelse til å installere lokal programvare, inkludert nettleser-basert-utvidelser og -tillegg.
Selv om de vurderede ansikts- og øye-bevegelsene ikke er like nøyaktige som de kunne være i omstendigheter hvor dedikerte lokale maskinlærings-rammeverk (som YOLO-serien) kunne brukes, tilbyr denne nesten friksjonsløse tilnærmingen til publikums-vurdering tilstrekkelig nøyaktighet for bred mening og holdning-analyse i typiske video-konferanse-scenarier. Over alt annet, er det veldig billig.
Se den tilknyttede prosjekt-videoen nedenfor for mer detalj og eksempler.
Først publisert 11. april 2022.












