AI 101
Wat is Versterking Learning?
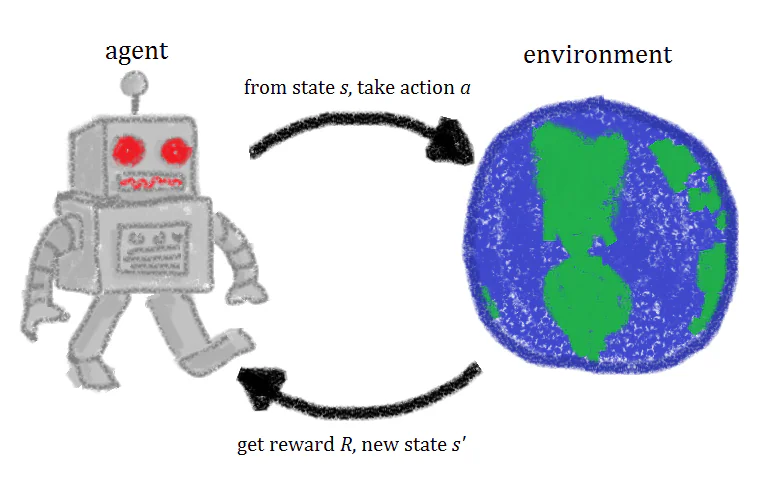
Wat is Versterking Learning?
Kort samengevat is versterking learning een machine learning-techniek die bestaat uit het trainen van een kunstmatige intelligentie-agent door middel van herhaling van acties en geassocieerde beloningen. Een versterking learning-agent experimenteert in een omgeving, neemt acties en wordt beloond wanneer de juiste acties worden genomen. Na verloop van tijd leert de agent om de acties te nemen die zijn beloning maximaliseren. Dat is een korte definitie van versterking learning, maar een nadere blik op de concepten achter versterking learning zal u helpen om een beter, intuïtiever begrip van het onderwerp te krijgen.
Het begrip “versterking learning” is afgeleid van het concept van versterking in de psychologie. Om die reden nemen we even de tijd om het psychologische concept van versterking te begrijpen. In de psychologische zin verwijst versterking naar iets dat de kans vergroot dat een bepaalde reactie/actie zal optreden. Dit concept van versterking is een centraal idee van de theorie van operant conditioning, oorspronkelijk voorgesteld door de psycholoog B.F. Skinner. In deze context is versterking alles wat de frequentie van een bepaald gedrag doet toenemen. Als we denken aan mogelijke versterking voor mensen, kunnen dit dingen zijn zoals lof, een salarisverhoging op het werk, snoep en leuke activiteiten.
In de traditionele, psychologische zin zijn er twee soorten versterking. Er is positieve versterking en negatieve versterking. Positieve versterking is het toevoegen van iets om een gedrag te verhogen, zoals het geven van een treat aan uw hond als hij zich goed gedraagt. Negatieve versterking houdt het verwijderen van een stimulus in om een gedrag te veroorzaken, zoals het uitschakelen van harde geluiden om een schuw kat naar buiten te lokken.
Positieve en Negatieve Versterking
Positieve versterking verhoogt de frequentie van een gedrag, terwijl negatieve versterking de frequentie verlaagt. In het algemeen is positieve versterking het meest voorkomende type versterking dat in versterking learning wordt gebruikt, omdat het modellen helpt om de prestaties op een bepaalde taak te maximaliseren. Niet alleen dat, maar positieve versterking leidt ook tot duurzame veranderingen, veranderingen die consistent kunnen worden en lang kunnen duren.
In tegenstelling tot positieve versterking maakt negatieve versterking een gedrag ook waarschijnlijker, maar wordt het gebruikt om een minimumprestatieniveau te handhaven in plaats van een model zijn maximale prestatie te bereiken. Negatieve versterking in versterking learning kan helpen ervoor zorgen dat een model wordt afgehouden van ongewenste acties, maar kan een model niet echt aanzetten tot het verkennen van gewenste acties.
Trainen van een Versterking Agent
Wanneer een versterking learning-agent wordt getraind, zijn er vier verschillende ingrediënten of staten die in de training worden gebruikt: initiële staten (State 0), nieuwe staat (State 1), acties en beloningen.
Stel dat we een versterking agent trainen om een platformspel te spelen waarin het doel van de AI is om het einde van het niveau te bereiken door naar rechts over het scherm te bewegen. De initiële staat van het spel wordt uit de omgeving getrokken, wat betekent dat de eerste frame van het spel wordt geanalyseerd en aan het model wordt gegeven. Op basis van deze informatie moet het model een actie kiezen.
Tijdens de initiële fasen van de training zijn deze acties willekeurig, maar naarmate het model wordt versterkt, worden bepaalde acties vaker. Nadat de actie is genomen, wordt de omgeving van het spel bijgewerkt en wordt een nieuwe staat of frame gemaakt. Als de actie die door de agent is genomen een gewenst resultaat opleverde, laten we zeggen in dit geval dat de agent nog steeds leeft en niet door een vijand is geraakt, wordt een beloning aan de agent gegeven en wordt het waarschijnlijker dat hij in de toekomst hetzelfde doet.
Dit basis systeem wordt constant herhaald, gebeurt keer op keer, en elke keer probeert de agent een beetje meer te leren en zijn beloning te maximaliseren.
Episodische vs Continue Taken
Versterking learning-taken kunnen typisch in een van twee verschillende categorieën worden onderverdeeld: episodische taken en continue taken.
Episodische taken voeren de leer-/trainingslus uit en verbeteren hun prestaties totdat een bepaalde eindcriteria zijn bereikt en de training wordt beëindigd. In een spel kan dit het bereiken van het einde van het niveau zijn of in een valkuil zoals spikes terechtkomen. In tegenstelling tot episodische taken hebben continue taken geen beëindigingscriteria, ze trainen in wezen voor altijd totdat de ingenieur besluit de training te beëindigen.
Monte Carlo vs Temporaal Verschil
Er zijn twee primaire manieren om een versterking learning-agent te trainen. In de Monte Carlo-benadering worden beloningen alleen aan het einde van de trainingsepisode aan de agent gegeven (de score van de agent wordt bijgewerkt). Om het anders te zeggen, alleen wanneer de beëindigingsconditie wordt bereikt, leert het model hoe goed het heeft gepresteerd. Het kan deze informatie dan gebruiken om bij te werken en wanneer de volgende trainingsronde wordt gestart, zal het reageren volgens de nieuwe informatie.
De temporaal verschil methode verschilt van de Monte Carlo-methode doordat de waardebepaling, of de schatting van de score, tijdens de trainingsepisode wordt bijgewerkt. Zodra het model naar de volgende tijdstap gaat, worden de waarden bijgewerkt.
Verkenning vs Exploitatie
Het trainen van een versterking learning-agent is een evenwichtsoefening, waarbij twee verschillende metrieken in evenwicht moeten worden gehouden: verkenning en exploitatie.
Verkenning is het verzamelen van meer informatie over de omgeving, terwijl exploitatie het gebruik van de reeds bekende informatie over de omgeving is om beloningspunten te verdienen. Als een agent alleen verkenning doet en nooit exploiteert, zullen de gewenste acties nooit worden uitgevoerd. Aan de andere kant, als de agent alleen exploiteert en nooit verkenning doet, zal de agent alleen leren om één actie uit te voeren en zal hij geen andere mogelijke strategieën ontdekken om beloningen te verdienen. Daarom is het in evenwicht brengen van verkenning en exploitatie cruciaal bij het creëren van een versterking learning-agent.
Gebruiksvoorbeelden voor Versterking Learning
Versterking learning kan op een breed scala aan gebieden worden toegepast en is het beste geschikt voor toepassingen waar taken geautomatiseerd moeten worden.
De automatisering van taken die door industriële robots moeten worden uitgevoerd, is een gebied waar versterking learning nuttig is. Versterking learning kan ook worden gebruikt voor problemen zoals tekst mining, waarbij modellen worden gemaakt die lange teksten kunnen samenvatten. Onderzoekers experimenteren ook met het gebruik van versterking learning in de gezondheidszorg, waar versterking agents taken zoals het optimaliseren van behandelingsrichtlijnen uitvoeren. Versterking learning kan ook worden gebruikt om onderwijsmateriaal voor studenten aan te passen.
Samenvatting van Versterking Learning
Versterking learning is een krachtige methode om AI-agents te construeren die indrukwekkende en soms verrassende resultaten kunnen opleveren. Het trainen van een agent door middel van versterking learning kan complex en moeilijk zijn, omdat het veel trainingsiteraties en een delicate balans van de verkenning/exploitatie dichotomie vereist. Echter, als het succesvol is, kan een agent die met versterking learning is gemaakt complexe taken onder een breed scala aan verschillende omgevingen uitvoeren.








