
AI 101
Wat is overfitting?
Wat is overfitting?
Wanneer je een neuraal netwerk traint, moet je overfitting vermijden. overfitting is een probleem binnen machine learning en statistiek waarbij een model de patronen van een trainingsdataset te goed leert, waardoor de trainingsdataset perfect wordt uitgelegd, maar de voorspellende kracht ervan niet kan worden gegeneraliseerd naar andere datasets.
Met andere woorden, in het geval van een overfitting-model zal het vaak een extreem hoge nauwkeurigheid vertonen op de trainingsdataset, maar een lage nauwkeurigheid op de verzamelde en in de toekomst door het model uitgevoerde gegevens. Dat is een snelle definitie van overfitting, maar laten we het concept van overfitting in meer detail bespreken. Laten we eens kijken hoe overfitting ontstaat en hoe dit kan worden vermeden.
Inzicht in ‘fit’ en ‘underfitting’
Het is nuttig om eens te kijken naar het concept van ondermaats en “geschikt”algemeen als het over overfitting gaat. Wanneer we een model trainen, proberen we een raamwerk te ontwikkelen dat in staat is de aard of klasse van items binnen een dataset te voorspellen, op basis van de kenmerken die die items beschrijven. Een model moet een patroon binnen een dataset kunnen verklaren en de klassen van toekomstige datapunten kunnen voorspellen op basis van dit patroon. Hoe beter het model de relatie tussen de kenmerken van de trainingsset verklaart, hoe ‘fiter’ ons model is.
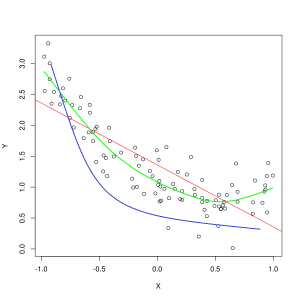
Blauwe lijn vertegenwoordigt voorspellingen door een model dat ondermaats is, terwijl de groene lijn een beter passend model vertegenwoordigt. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Een model dat de relatie tussen de kenmerken van de trainingsgegevens slecht uitlegt en dus toekomstige gegevensvoorbeelden niet nauwkeurig classificeert, is ondermaats de trainingsgegevens. Als u de voorspelde relatie van een ondermaats model zou uitzetten tegen de daadwerkelijke kruising van de kenmerken en labels, zouden de voorspellingen afwijken. Als we een grafiek hadden met de werkelijke waarden van een trainingsset gelabeld, zou een ernstig ondermaats model de meeste gegevenspunten drastisch missen. Een model met een betere pasvorm kan een pad door het midden van de gegevenspunten snijden, waarbij individuele gegevenspunten slechts een klein beetje afwijken van de voorspelde waarden.
Underfitting kan vaak optreden wanneer er onvoldoende gegevens zijn om een nauwkeurig model te maken, of wanneer u probeert een lineair model te ontwerpen met niet-lineaire gegevens. Meer trainingsgegevens of meer functies helpen vaak om underfitting te verminderen.
Dus waarom zouden we niet gewoon een model maken dat elk punt in de trainingsgegevens perfect verklaart? Perfecte nauwkeurigheid is toch wenselijk? Het creëren van een model dat de patronen van de trainingsgegevens te goed heeft geleerd, veroorzaakt overfitting. De trainingsdataset en andere, toekomstige datasets die u door het model laat lopen, zullen niet exact hetzelfde zijn. Ze zullen waarschijnlijk in veel opzichten erg op elkaar lijken, maar ze zullen ook op belangrijke punten verschillen. Daarom betekent het ontwerpen van een model dat de trainingsdataset perfect uitlegt, dat je een theorie krijgt over de relatie tussen kenmerken die niet goed te generaliseren is naar andere datasets.
Overfitting begrijpen
Overfitting vindt plaats wanneer een model de details binnen de trainingsdataset te goed leert, waardoor het model eronder lijdt als er voorspellingen worden gedaan op basis van externe gegevens. Dit kan gebeuren wanneer het model niet alleen de kenmerken van de dataset leert, maar ook willekeurige fluctuaties lawaai binnen de dataset, waarbij belang wordt gehecht aan deze willekeurige/onbelangrijke gebeurtenissen.
Overfitting is waarschijnlijker wanneer niet-lineaire modellen worden gebruikt, omdat ze flexibeler zijn bij het leren van gegevenskenmerken. Niet-parametrische machine learning-algoritmen hebben vaak verschillende parameters en technieken die kunnen worden toegepast om de gevoeligheid van het model voor gegevens te beperken en zo overfitting te verminderen. Als voorbeeld, beslisboom modellen zijn zeer gevoelig voor overfitting, maar een techniek genaamd snoeien kan worden gebruikt om willekeurig een deel van het detail dat het model heeft geleerd te verwijderen.
Als je de voorspellingen van het model op de X- en Y-assen zou uitzetten, zou je een voorspellingslijn hebben die heen en weer zigzagt, wat het feit weerspiegelt dat het model te hard heeft geprobeerd om alle punten in de dataset in te passen. zijn uitleg.
Overfitting beheersen
Wanneer we een model trainen, willen we idealiter dat het model geen fouten maakt. Wanneer de prestaties van het model convergeren naar het maken van correcte voorspellingen voor alle datapunten in de trainingsdataset, wordt de fit steeds beter. Een model met een goede fit kan bijna de hele trainingsdataset verklaren zonder overfitting.
Naarmate een model traint, verbeteren zijn prestaties in de loop van de tijd. Het foutenpercentage van het model zal afnemen naarmate de trainingstijd verstrijkt, maar het neemt slechts tot een bepaald punt af. Het punt waarop de prestaties van het model op de testset weer beginnen te stijgen, is meestal het punt waarop overfitting plaatsvindt. Om de beste pasvorm voor een model te krijgen, willen we stoppen met het trainen van het model op het punt met het laagste verlies op de trainingsset, voordat de fout weer begint toe te nemen. Het optimale stoppunt kan worden bepaald door de prestaties van het model gedurende de trainingstijd in een grafiek weer te geven en de training te stoppen wanneer het verlies het laagst is. Een risico bij deze methode om te controleren op overfitting is echter dat het specificeren van het eindpunt voor de training op basis van testprestaties betekent dat de testgegevens enigszins worden opgenomen in de trainingsprocedure en de status van puur "onaangeroerde" gegevens verliezen.
Er zijn een aantal verschillende manieren om overfitting tegen te gaan. Een methode om overfitting te verminderen, is het gebruik van een resampling-tactiek, die werkt door de nauwkeurigheid van het model te schatten. Je kunt ook een bevestiging dataset naast de testset en plot de trainingsnauwkeurigheid tegen de validatieset in plaats van de testdataset. Hierdoor blijft uw testdataset ongezien. Een populaire resampling-methode is kruisvalidatie met K-vouwen. Met deze techniek kunt u uw gegevens verdelen in subsets waarop het model is getraind, waarna de prestaties van het model op de subsets worden geanalyseerd om te schatten hoe het model zal presteren op externe gegevens.
Gebruikmaken van kruisvalidatie is een van de beste manieren om de nauwkeurigheid van een model op ongeziene gegevens in te schatten, en in combinatie met een validatiegegevensset kan overfitting vaak tot een minimum worden beperkt.










