
AI 101
Wat is gradiëntafdaling?
Wat is een gradiëntafdaling?
Als je hebt gelezen hoe neurale netwerken worden getraind, ben je vrijwel zeker al eerder de term 'gradiëntafdaling' tegengekomen. Verloop afdaling is de belangrijkste methode om de prestaties van een neuraal netwerk te optimaliseren, waardoor het verlies-/foutpercentage van het netwerk wordt verminderd. Gradiëntdaling kan echter een beetje moeilijk te begrijpen zijn voor degenen die nieuw zijn op het gebied van machinaal leren, en dit artikel zal proberen u een goede intuïtie te geven over hoe gradiëntdaling werkt.
Gradiëntafdaling is een optimalisatie-algoritme. Het wordt gebruikt om de prestaties van een neuraal netwerk te verbeteren door de parameters van het netwerk zodanig aan te passen dat het verschil tussen de voorspellingen van het netwerk en de werkelijke/verwachte waarden van het netwerk (ook wel het verlies genoemd) zo klein mogelijk is. Gradiëntafdaling neemt de beginwaarden van de parameters en gebruikt bewerkingen op basis van calculus om hun waarden aan te passen aan de waarden die het netwerk zo nauwkeurig mogelijk maken. Je hoeft niet veel calculus te kennen om te begrijpen hoe gradiëntafdaling werkt, maar je moet wel verstand hebben van gradiënten.
Wat zijn verlopen?
Stel dat er een grafiek is die de hoeveelheid fouten weergeeft die een neuraal netwerk maakt. De onderkant van de grafiek geeft de punten met de laagste fout weer, terwijl de bovenkant van de grafiek de hoogste fout is. We willen van de bovenkant van de grafiek naar beneden gaan. Een gradiënt is slechts een manier om de relatie tussen fouten en de gewichten van het neurale netwerk te kwantificeren. De relatie tussen deze twee dingen kan worden weergegeven als een helling, met onjuiste gewichten die meer fouten produceren. De steilheid van de helling/helling geeft aan hoe snel het model aan het leren is.
Een steilere helling betekent dat er veel minder fouten worden gemaakt en dat het model snel leert, terwijl als de helling nul is, het model zich op een plateau bevindt en niet leert. We kunnen de helling afdalen naar minder fouten door een gradiënt, een bewegingsrichting (verandering in de parameters van het netwerk) voor ons model te berekenen.
Laten we de metafoor een beetje verschuiven en ons een reeks heuvels en valleien voorstellen. We willen naar de bodem van de heuvel en het deel van de vallei vinden dat het laagste verlies vertegenwoordigt. Als we bovenaan de heuvel beginnen, kunnen we met grote stappen de heuvel af en erop vertrouwen dat we op weg zijn naar het laagste punt in de vallei.
Naarmate we echter dichter bij het laagste punt in de vallei komen, zullen onze stappen kleiner moeten worden, anders kunnen we voorbij het werkelijke laagste punt schieten. Evenzo is het mogelijk dat bij het aanpassen van de gewichten van het netwerk, de aanpassingen het eigenlijk verder weg kunnen brengen van het punt met het laagste verlies, en daarom moeten de aanpassingen in de loop van de tijd kleiner worden. In de context van het afdalen van een heuvel naar een punt met het laagste verlies, is de gradiënt een vector/instructies die het pad beschrijven dat we moeten nemen en hoe groot onze stappen moeten zijn.
Nu we weten dat gradiënten instructies zijn die ons vertellen in welke richting we moeten bewegen (welke coëfficiënten moeten worden bijgewerkt) en hoe groot de stappen zijn die we moeten nemen (hoeveel de coëfficiënten moeten worden bijgewerkt), kunnen we onderzoeken hoe de gradiënt wordt berekend.
Gradiënten en hellingafdaling berekenen
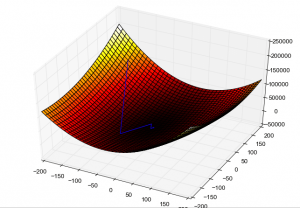
Gradiëntafdaling begint op een plaats met veel verlies en neemt via meerdere iteraties stappen in de richting van het minste verlies, met als doel de optimale gewichtsconfiguratie te vinden. Foto: Роман Сузи via Wikimedia Commons, CCY BY SA 3.0 (https://commons.wikimedia.org/wiki/File:Gradient_descent_method.png)
Om een gradiëntafdaling uit te voeren, moeten eerst de gradiënten worden berekend. In volgorde om de helling te berekenen, moeten we de verlies/kosten-functie kennen. We gebruiken de kostenfunctie om de afgeleide te bepalen. In calculus verwijst de afgeleide alleen naar de helling van een functie op een bepaald punt, dus we berekenen in feite gewoon de helling van de heuvel op basis van de verliesfunctie. We bepalen het verlies door de coëfficiënten door de verliesfunctie te laten lopen. Als we de verliesfunctie weergeven als "f", dan kunnen we stellen dat de vergelijking voor het berekenen van het verlies als volgt is (we voeren alleen de coëfficiënten door de door ons gekozen kostenfunctie):
Verlies = f(coëfficiënt)
Vervolgens berekenen we de afgeleide, ofwel bepalen we de helling. Door de afgeleide van het verlies te krijgen, weten we welke richting de helling op of af is, door ons het juiste teken te geven waarmee we onze coëfficiënten kunnen aanpassen. We zullen de juiste richting weergeven als "delta".
delta = afgeleide_functie(verlies)
We hebben nu bepaald welke richting bergafwaarts is naar het punt met het laagste verlies. Dit betekent dat we de coëfficiënten in de neurale netwerkparameters kunnen bijwerken en hopelijk het verlies kunnen verminderen. We werken de coëfficiënten bij op basis van de vorige coëfficiënten min de juiste verandering in waarde zoals bepaald door de richting (delta) en een argument dat de grootte van de verandering bepaalt (de grootte van onze stap). Het argument dat de grootte van de update bepaalt, wordt de "leersnelheid” en we zullen het vertegenwoordigen als “alpha”.
coëfficiënt = coëfficiënt – (alfa * delta)
Vervolgens herhalen we dit proces totdat het netwerk is geconvergeerd rond het punt met het laagste verlies, dat bijna nul zou moeten zijn.
Het is erg belangrijk om de juiste waarde voor het leertempo (alfa) te kiezen. Het gekozen leertempo mag niet te klein of te groot zijn. Onthoud dat als we het punt met het laagste verlies naderen, onze stappen kleiner moeten worden, anders schieten we door het punt van het laagste verlies heen en eindigen aan de andere kant. Het punt van het kleinste verlies is klein en als onze veranderingssnelheid te groot is, kan de fout uiteindelijk weer toenemen. Als de stapgroottes te groot zijn, zullen de prestaties van het netwerk blijven stuiteren rond het punt met het laagste verlies, waarbij het aan de ene kant en dan aan de andere kant voorbijschiet. Als dit gebeurt, zal het netwerk nooit convergeren naar de echt optimale gewichtsconfiguratie.
Als het leertempo daarentegen te klein is, kan het buitengewoon lang duren voordat het netwerk de optimale gewichten bereikt.
Soorten gradiëntafdaling
Nu we begrijpen hoe gradiëntafdaling in het algemeen werkt, laten we een paar van de verschillende bekijken soorten gradiëntafdaling.
Batchgradiëntafdaling: deze vorm van gradiëntafdaling doorloopt alle trainingsvoorbeelden voordat de coëfficiënten worden bijgewerkt. Dit type gradiëntafdaling is waarschijnlijk de meest rekenkundig efficiënte vorm van gradiëntafdaling, aangezien de gewichten pas worden bijgewerkt nadat de hele batch is verwerkt, wat betekent dat er in totaal minder updates zijn. Als de dataset echter een groot aantal trainingsvoorbeelden bevat, kan het afdalen van de batchgradiënt ervoor zorgen dat de training lang duurt.
Stochastic Gradient Descent: In Stochastic Gradient Descent wordt slechts één trainingsvoorbeeld verwerkt voor elke iteratie van gradiëntafdaling en parameterupdates. Dit gebeurt bij elk trainingsvoorbeeld. Omdat er slechts één trainingsvoorbeeld wordt verwerkt voordat de parameters worden bijgewerkt, convergeert het sneller dan Batch Gradient Descent, omdat updates eerder worden uitgevoerd. Omdat het proces echter op elk item in de trainingsset moet worden uitgevoerd, kan het behoorlijk lang duren om te voltooien als de dataset groot is, dus gebruik indien gewenst een van de andere typen met gradiëntafdaling.
Mini-Batch Gradient Descent: Mini-Batch Gradient Descent werkt door de volledige trainingsdataset op te splitsen in subsecties. Het creëert kleinere mini-batches die door het netwerk worden geleid en wanneer de mini-batch is gebruikt om de fout te berekenen, worden de coëfficiënten bijgewerkt. Mini-batch Gradient Descent is een middenweg tussen Stochastic Gradient Descent en Batch Gradient Descent. Het model wordt vaker bijgewerkt dan in het geval van Batch Gradient Descent, wat een iets snellere en robuustere convergentie van de optimale parameters van het model betekent. Het is ook rekenkundig efficiënter dan Stochastic Gradient Descent














