
AI 101
Wat is een verwarringsmatrix?
Een van de krachtigste analytische tools in machine learning en data science in de verwarringsmatrix. De verwarringsmatrix kan de onderzoekers gedetailleerde informatie geven over hoe een machine learning-classificator heeft gepresteerd met betrekking tot de doelklassen in de dataset. Een verwarringsmatrix zal voorbeelden demonstreren die op de juiste manier zijn geclassificeerd ten opzichte van verkeerd geclassificeerde voorbeelden. Laten we eens dieper kijken naar hoe een verwarringsmatrix is gestructureerd en hoe deze kan worden geïnterpreteerd.
Wat is een verwarringsmatrix?
Laten we beginnen met een eenvoudige definitie van een verwarringsmatrix. Een verwarringsmatrix is een hulpmiddel voor voorspellende analyse. Het is met name een tabel die werkelijke waarden weergeeft en vergelijkt met de voorspelde waarden van het model. Binnen de context van machine learning wordt een verwarringsmatrix gebruikt als maatstaf om te analyseren hoe een machine learning-classificatie presteerde op een dataset. Een verwarringsmatrix genereert een visualisatie van metrische gegevens zoals precisie, nauwkeurigheid, specificiteit en herinnering.
De reden dat de verwarringsmatrix bijzonder nuttig is, is dat de verwarringsmatrix, in tegenstelling tot andere soorten classificatiestatistieken zoals eenvoudige nauwkeurigheid, een vollediger beeld geeft van hoe een model presteerde. Alleen het gebruik van een metriek zoals nauwkeurigheid kan leiden tot een situatie waarin het model een klasse volledig en consequent verkeerd identificeert, maar het blijft onopgemerkt omdat de prestaties gemiddeld goed zijn. Ondertussen de verwarringsmatrix geeft een vergelijking van verschillende waarden zoals valse negatieven, echte negatieven, valse positieven en echte positieven.
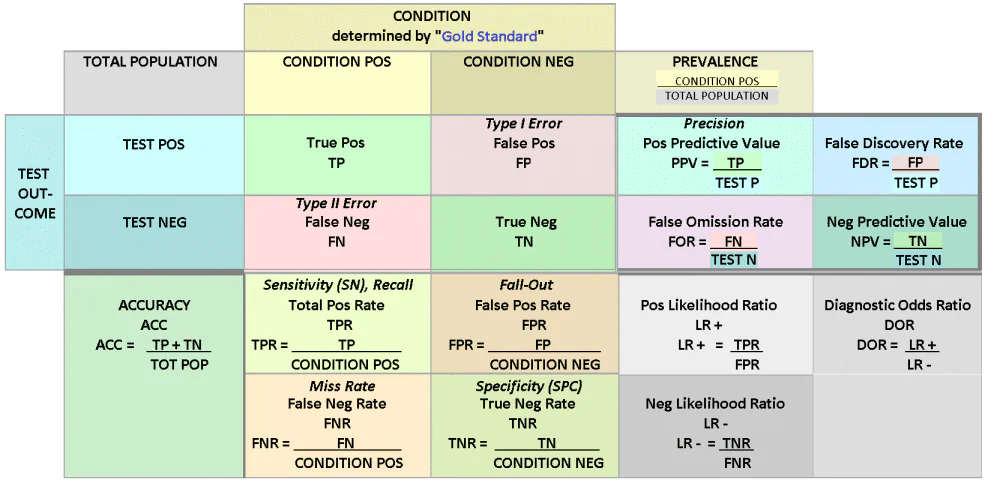
Laten we de verschillende statistieken definiëren die een verwarringsmatrix vertegenwoordigt.
Terugroepen in een verwarringsmatrix
Recall is het aantal echt positieve voorbeelden gedeeld door het aantal fout-negatieve voorbeelden en totaal positieve voorbeelden. Met andere woorden, recall is representatief voor het aandeel echt positieve voorbeelden dat een machine learning-model heeft geclassificeerd. Recall wordt gegeven als het percentage positieve voorbeelden dat het model kon classificeren uit alle positieve voorbeelden in de dataset. Deze waarde wordt ook wel de "hit rate" genoemd en een gerelateerde waarde is "gevoeligheid”, die de waarschijnlijkheid van terugroeping beschrijft, of het aantal echt positieve voorspellingen.
precisie in een verwarringsmatrix
Net als recall is precisie een waarde die de prestaties van een model bijhoudt in termen van positieve voorbeeldclassificatie. In tegenstelling tot herinneren, gaat precisie echter over hoeveel van de voorbeelden die het model als positief bestempelde echt positief waren. Om dit te berekenen, wordt het aantal terecht-positieve voorbeelden gedeeld door het aantal fout-positieven plus terecht-positieven.
Om het onderscheid tussen te maken herinneren en precisie duidelijker, richt precisie zich op het berekenen van het percentage van alle als positief bestempelde voorbeelden dat echt positief was, terwijl recall het percentage van alle echt positieve voorbeelden bijhoudt dat het model kon herkennen.
specificiteit in een verwarringsmatrix
Hoewel terugroepen en precisie waarden zijn die positieve voorbeelden en het werkelijke positieve percentage volgen, specificiteit kwantificeert het echt negatieve percentage of het aantal voorbeelden dat het model als negatief heeft gedefinieerd en dat echt negatief was. Dit wordt berekend door het aantal als negatief geclassificeerde voorbeelden te nemen en deze te delen door het aantal fout-positieve voorbeelden gecombineerd met de echt negatieve voorbeelden.
Betekenis van de verwarringsmatrix

Foto: Jackverr via Wikimedia Commons, (https://commons.wikimedia.org/wiki/File:ConfusionMatrix.png), CC BY SA 3.0
Voorbeeld van een verwarringsmatrix
Na het definiëren van noodzakelijke termen zoals precisie, herinnering, gevoeligheid en specificiteit, kunnen we onderzoeken hoe deze verschillende waarden worden weergegeven in een verwarringsmatrix. Bij classificatie wordt een verwarringsmatrix gegenereerd, die van toepassing is wanneer er twee of meer klassen zijn. De gegenereerde verwarringsmatrix kan zo hoog en breed zijn als nodig is en kan elk gewenst aantal klassen bevatten, maar voor de eenvoud zullen we een 2 x 2 verwarringsmatrix onderzoeken voor een binaire classificatietaak.
Stel bijvoorbeeld dat een classificatie wordt gebruikt om te bepalen of een patiënt al dan niet een ziekte heeft. De kenmerken worden in de classificator ingevoerd en de classificator retourneert een van de twee verschillende classificaties: de patiënt heeft de ziekte niet of zij hebben de ziekte.
Laten we beginnen met de linkerkant van de matrix. De linkerkant van de verwarringsmatrix vertegenwoordigt de voorspellingen die de classificator voor de individuele klassen heeft gedaan. Een binaire classificatietaak heeft hier twee rijen. Wat betreft het bovenste gedeelte van de matrix, het volgt de werkelijke waarden, de daadwerkelijke klassenlabels, van de gegevensinstanties.
Het interpreteren van een verwarringsmatrix kan worden gedaan door te onderzoeken waar de rijen en kolommen elkaar kruisen. Vergelijk de voorspellingen van het model met de echte labels van het model. In dit geval bevinden de True Positives-waarden, het aantal juiste positieve voorspellingen, zich in de linkerbovenhoek. De fout-positieven zijn te vinden in de rechterbovenhoek, waar de voorbeelden eigenlijk negatief zijn, maar de classificator het als positief heeft gemarkeerd.
In de linkerbenedenhoek van het raster worden instanties weergegeven die de classificator als negatief heeft aangemerkt, maar die echt positief waren. Ten slotte is de rechter benedenhoek van de verwarringsmatrix waar de True Negative-waarden worden gevonden, of waar de echt valse voorbeelden zijn.
Als de dataset meer dan twee klassen bevat, groeit de matrix met dat aantal klassen. Als er bijvoorbeeld drie klassen zijn, is de matrix een 3 x 3 matrix. Ongeacht de grootte van de verwarringsmatrix, de methode om ze te interpreteren is precies hetzelfde. De linkerkant bevat de voorspelde waarden en de werkelijke klassenlabels lopen over de bovenkant. De instanties die de classifier correct heeft voorspeld, lopen diagonaal van linksboven naar rechtsonder. Door naar de matrix te kijken, kunt u de vier hierboven besproken voorspellende statistieken onderscheiden.
U kunt bijvoorbeeld de terugroepactie berekenen door de terecht-positieven en fout-negatieven te nemen, ze bij elkaar op te tellen en ze te delen door het aantal echt-positieve voorbeelden. Ondertussen kan de precisie worden berekend door de fout-positieven te combineren met de echt-positieven en vervolgens de waarde te delen door het totale aantal echt-positieven.
Hoewel men tijd zou kunnen besteden aan het handmatig berekenen van statistieken zoals precisie, herinnering en specificiteit, worden deze statistieken zo vaak gebruikt dat de meeste machine learning-bibliotheken methoden hebben om ze weer te geven. Scikit-learn voor Python heeft bijvoorbeeld een functie die een verwarringsmatrix genereert.










