
AI 101
Wat is lineaire regressie?
Wat is lineaire regressie?
Lineaire regressie is een algoritme dat wordt gebruikt om a relatie tussen twee verschillende kenmerken/variabelen. Bij lineaire regressietaken worden twee soorten variabelen onderzocht: de afhankelijke variabele en de onafhankelijke variabele. De onafhankelijke variabele is de variabele die op zichzelf staat en niet wordt beïnvloed door de andere variabele. Naarmate de onafhankelijke variabele wordt aangepast, zullen de niveaus van de afhankelijke variabele fluctueren. De afhankelijke variabele is de variabele die wordt bestudeerd, en het is wat het regressiemodel oplost/probeert te voorspellen. Bij lineaire regressietaken bestaat elke waarneming/instantie uit zowel de waarde van de afhankelijke variabele als de waarde van de onafhankelijke variabele.
Dat was een korte uitleg van lineaire regressie, maar laten we ervoor zorgen dat we lineaire regressie beter begrijpen door naar een voorbeeld ervan te kijken en de formule die het gebruikt te onderzoeken.
Lineaire regressie begrijpen
Stel dat we een dataset hebben die de grootte van harde schijven en de kosten van die harde schijven dekt.
Laten we aannemen dat de dataset die we hebben uit twee verschillende kenmerken bestaat: de hoeveelheid geheugen en de kosten. Hoe meer geheugen we kopen voor een computer, hoe hoger de aankoopprijs. Als we de individuele gegevenspunten in een spreidingsplot uitzetten, krijgen we misschien een grafiek die er ongeveer zo uitziet:

De exacte verhouding tussen geheugen en kosten kan variëren tussen fabrikanten en modellen van harde schijven, maar over het algemeen is de trend van de gegevens er een die linksonder begint (waar harde schijven zowel goedkoper zijn als een kleinere capaciteit hebben) en zich verplaatst naar rechtsboven (waar de schijven duurder zijn en een hogere capaciteit hebben).
Als we de hoeveelheid geheugen op de X-as hadden en de kosten op de Y-as, zou een lijn die de relatie tussen de X- en Y-variabelen vastlegt, in de linkerbenedenhoek beginnen en naar rechtsboven lopen.
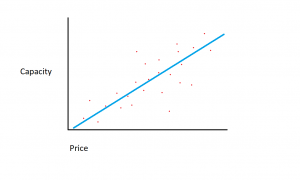
De functie van een regressiemodel is het bepalen van een lineaire functie tussen de X- en Y-variabelen die de relatie tussen de twee variabelen het best beschrijft. Bij lineaire regressie wordt aangenomen dat Y kan worden berekend uit een combinatie van de invoervariabelen. De relatie tussen de invoervariabelen (X) en de doelvariabelen (Y) kan worden weergegeven door een lijn door de punten in de grafiek te trekken. De lijn vertegenwoordigt de functie die de relatie tussen X en Y het beste beschrijft (bijvoorbeeld, elke keer dat X met 3 toeneemt, neemt Y met 2 toe). Het doel is om een optimale "regressielijn" te vinden, of de lijn/functie die het beste bij de gegevens past.
Lijnen worden doorgaans weergegeven door de vergelijking: Y = m*X + b. X verwijst naar de afhankelijke variabele, terwijl Y de onafhankelijke variabele is. Ondertussen is m de helling van de lijn, zoals gedefinieerd door de “stijging” boven de “run”. Beoefenaars van machine learning geven de beroemde hellingslijnvergelijking een beetje anders weer, maar gebruiken in plaats daarvan deze vergelijking:
y(x) = w0 + w1 * x
In de bovenstaande vergelijking is y de doelvariabele, terwijl "w" de parameters van het model zijn en de invoer "x". Dus de vergelijking wordt gelezen als: "De functie die Y geeft, afhankelijk van X, is gelijk aan de parameters van het model vermenigvuldigd met de kenmerken". De parameters van het model worden tijdens de training aangepast om de best passende regressielijn te krijgen.
Meerdere lineaire regressie

Foto: Cbaf via Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Het hierboven beschreven proces is van toepassing op eenvoudige lineaire regressie of regressie op datasets waarbij er slechts één kenmerk/onafhankelijke variabele is. Een regressie kan echter ook met meerdere kenmerken worden uitgevoerd. In het geval van "Meerdere lineaire regressie”, wordt de vergelijking uitgebreid met het aantal gevonden variabelen in de dataset. Met andere woorden, terwijl de vergelijking voor reguliere lineaire regressie y(x) = w0 + w1 * x is, is de vergelijking voor meervoudige lineaire regressie y(x) = w0 + w1x1 plus de gewichten en invoer voor de verschillende kenmerken. Als we het totale aantal gewichten en kenmerken voorstellen als w(n)x(n), dan zouden we de formule als volgt kunnen weergeven:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Nadat de formule voor lineaire regressie is vastgesteld, gebruikt het machine learning-model verschillende waarden voor de gewichten, waardoor verschillende fitlijnen worden getekend. Onthoud dat het doel is om de lijn te vinden die het beste bij de gegevens past om te bepalen welke van de mogelijke gewichtscombinaties (en dus welke mogelijke lijn) het beste bij de gegevens past en om de relatie tussen de variabelen uit te leggen.
Een kostenfunctie wordt gebruikt om te meten hoe dicht de veronderstelde Y-waarden bij de werkelijke Y-waarden liggen bij een bepaalde gewichtswaarde. De kostenfunctie voor lineaire regressie is de gemiddelde kwadratische fout, die gewoon de gemiddelde (kwadratische) fout tussen de voorspelde waarde en de werkelijke waarde voor alle verschillende datapunten in de dataset neemt. De kostenfunctie wordt gebruikt om kosten te berekenen, die het verschil vastleggen tussen de voorspelde doelwaarde en de werkelijke doelwaarde. Als de fit-lijn ver van de gegevenspunten verwijderd is, zullen de kosten hoger zijn, terwijl de kosten kleiner worden naarmate de lijn dichter bij het vastleggen van de ware relaties tussen variabelen komt. De gewichten van het model worden vervolgens aangepast totdat de gewichtsconfiguratie is gevonden die de kleinste hoeveelheid fouten produceert.










