
AI 101
Wat is dimensionaliteitsreductie?
Wat is dimensionaliteitsreductie?
Dimensionaliteitsreductie is een proces dat wordt gebruikt om de dimensionaliteit van een dataset te verminderen, waarbij veel kenmerken worden genomen en ze als minder kenmerken worden weergegeven. Dimensionaliteitsreductie kan bijvoorbeeld worden gebruikt om een dataset van twintig kenmerken terug te brengen tot slechts enkele kenmerken. Dimensionaliteitsreductie wordt vaak gebruikt in zonder toezicht leren taken om automatisch klassen te maken uit vele functies. Om beter te begrijpen waarom en hoe dimensionaliteitsreductie wordt gebruikt, zullen we de problemen bekijken die verband houden met hoog-dimensionale gegevens en de meest populaire methoden om dimensionaliteit te verminderen.
Meer dimensies leiden tot overfitting
Dimensionaliteit verwijst naar het aantal kenmerken/kolommen binnen een dataset.
Er wordt vaak aangenomen dat bij machinaal leren meer functies beter zijn, omdat hierdoor een nauwkeuriger model ontstaat. Meer functies vertalen zich echter niet noodzakelijkerwijs in een beter model.
De kenmerken van een dataset kunnen sterk variëren in termen van hoe nuttig ze zijn voor het model, waarbij veel kenmerken van weinig belang zijn. Bovendien, hoe meer kenmerken de dataset bevat, hoe meer steekproeven er nodig zijn om ervoor te zorgen dat de verschillende combinaties van kenmerken goed worden weergegeven in de gegevens. Daarom neemt het aantal monsters evenredig toe met het aantal kenmerken. Meer voorbeelden en meer kenmerken betekenen dat het model complexer moet zijn, en naarmate modellen complexer worden, worden ze gevoeliger voor overfitting. Het model leert de patronen in de trainingsgegevens te goed en kan niet generaliseren naar de voorbeeldgegevens.
Het verminderen van de dimensionaliteit van een dataset heeft verschillende voordelen. Zoals eerder vermeld, zijn eenvoudigere modellen minder vatbaar voor overfitting, omdat het model minder aannames hoeft te doen over hoe kenmerken aan elkaar gerelateerd zijn. Bovendien betekent minder dimensies dat er minder rekenkracht nodig is om de algoritmen te trainen. Evenzo is er minder opslagruimte nodig voor een dataset met een kleinere dimensionaliteit. Door de dimensionaliteit van een dataset te verminderen, kunt u ook algoritmen gebruiken die niet geschikt zijn voor datasets met veel functies.
Gemeenschappelijke Dimensionaliteit Reductie Methoden
Dimensionaliteitsreductie kan zijn door feature-selectie of feature-engineering. Functieselectie is waar de ingenieur de meest relevante kenmerken van de dataset identificeert, terwijl functie-engineering is het proces van het creëren van nieuwe functies door andere functies te combineren of te transformeren.
Functieselectie en engineering kunnen programmatisch of handmatig worden gedaan. Bij het handmatig selecteren en engineeren van features is het gebruikelijk om de data te visualiseren om correlaties tussen features en klassen te ontdekken. Het op deze manier uitvoeren van dimensionaliteitsreductie kan behoorlijk tijdrovend zijn en daarom zijn enkele van de meest gebruikelijke manieren om dimensionaliteit te verminderen het gebruik van algoritmen die beschikbaar zijn in bibliotheken zoals Scikit-learn voor Python. Deze algemene algoritmen voor het verminderen van dimensionaliteit omvatten: Principal Component Analysis (PCA), Singular Value Decomposition (SVD) en Linear Discriminant Analysis (LDA).
De algoritmen die worden gebruikt bij dimensionaliteitsreductie voor leertaken zonder toezicht zijn doorgaans PCA en SVD, terwijl de algoritmen die worden gebruikt voor dimensionaliteitsreductie onder toezicht doorgaans LDA en PCA zijn. In het geval van modellen voor begeleid leren worden de nieuw gegenereerde functies gewoon in de machine learning-classificator ingevoerd. Houd er rekening mee dat de hier beschreven toepassingen slechts algemene gebruiksscenario's zijn en niet de enige omstandigheden waarin deze technieken kunnen worden gebruikt. De hierboven beschreven algoritmen voor dimensionaliteitsreductie zijn eenvoudigweg statistische methoden en worden buiten machine learning-modellen gebruikt.
Hoofdcomponentenanalyse

Foto: Matrix met geïdentificeerde hoofdcomponenten
Hoofdcomponentenanalyse (PCA) is een statistische methode die de kenmerken/kenmerken van een dataset analyseert en de kenmerken samenvat die het meest invloedrijk zijn. De kenmerken van de gegevensset worden gecombineerd tot representaties die de meeste kenmerken van de gegevens behouden, maar zijn verspreid over minder dimensies. U kunt dit zien als het "verpletteren" van de gegevens van een weergave met een hogere dimensie naar een weergave met slechts een paar dimensies.
Denk als voorbeeld van een situatie waarin PCA nuttig zou kunnen zijn na over de verschillende manieren waarop men wijn zou kunnen omschrijven. Hoewel het mogelijk is om wijn te beschrijven met behulp van veel zeer specifieke kenmerken, zoals CO2-niveaus, beluchtingsniveaus, enz., Kunnen dergelijke specifieke kenmerken relatief nutteloos zijn bij het identificeren van een specifiek type wijn. In plaats daarvan zou het verstandiger zijn om het type te identificeren op basis van meer algemene kenmerken zoals smaak, kleur en leeftijd. PCA kan worden gebruikt om meer specifieke functies te combineren en functies te creëren die algemener en nuttiger zijn en minder snel overfitting veroorzaken.
PCA wordt uitgevoerd door te bepalen hoe de invoerkenmerken ten opzichte van elkaar verschillen van het gemiddelde, door te bepalen of er relaties bestaan tussen de kenmerken. Om dit te doen, wordt een covariante matrix gemaakt, die een matrix vormt die is samengesteld uit de covarianties met betrekking tot de mogelijke paren van de kenmerken van de dataset. Dit wordt gebruikt om correlaties tussen de variabelen te bepalen, waarbij een negatieve covariantie een omgekeerde correlatie aangeeft en een positieve correlatie een positieve correlatie.
De belangrijkste (meest invloedrijke) componenten van de dataset worden gemaakt door lineaire combinaties van de beginvariabelen te maken, wat wordt gedaan met behulp van lineaire algebra-concepten genaamd eigenwaarden en eigenvectoren. De combinaties worden zo gemaakt dat de hoofdcomponenten niet met elkaar gecorreleerd zijn. De meeste informatie in de initiële variabelen is gecomprimeerd tot de eerste paar hoofdcomponenten, wat betekent dat er nieuwe kenmerken (de hoofdcomponenten) zijn gemaakt die de informatie van de originele dataset in een kleinere dimensionale ruimte bevatten.
Singuliere waarden ontbinding
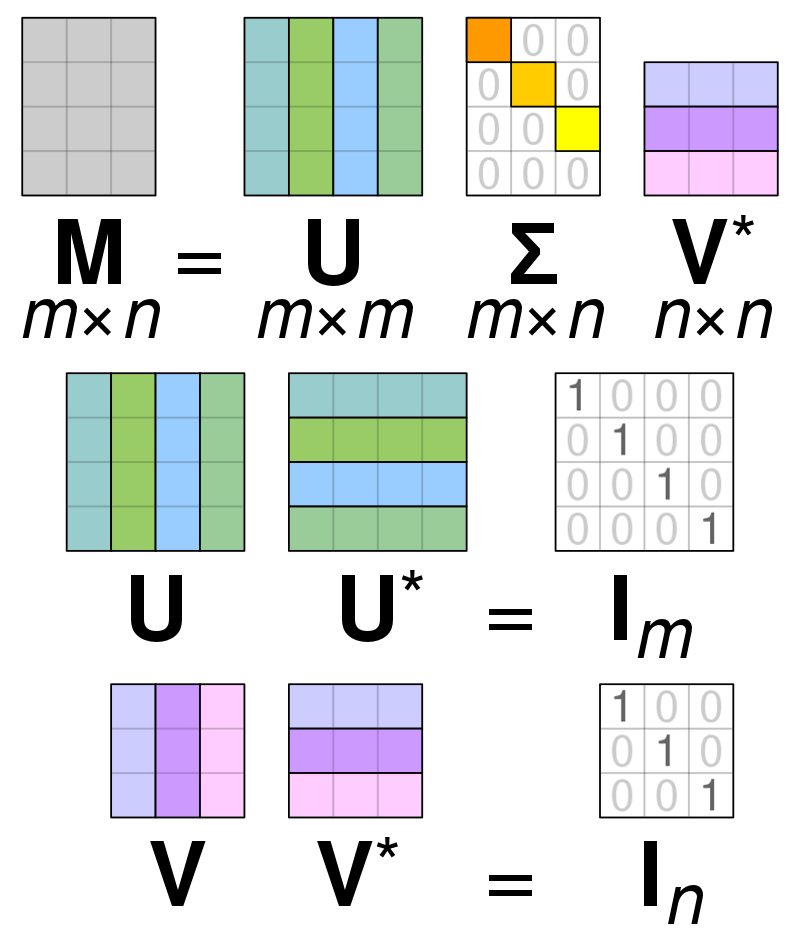
Foto: Door Cmglee – Eigen werk, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Singuliere Waarde Decompositie (SVD) is gebruikt om de waarden binnen een matrix te vereenvoudigen, waardoor de matrix wordt teruggebracht tot de samenstellende delen en berekeningen met die matrix eenvoudiger worden. SVD kan worden gebruikt voor zowel reële waarde als complexe matrices, maar voor de doeleinden van deze uitleg zal worden onderzocht hoe een matrix van reële waarden kan worden ontbonden.
Stel dat we een matrix hebben die is samengesteld uit gegevens met reële waarde en dat ons doel is om het aantal kolommen/functies binnen de matrix te verminderen, vergelijkbaar met het doel van PCA. Net als PCA zal SVD de dimensionaliteit van de matrix comprimeren terwijl zoveel mogelijk van de variabiliteit van de matrix behouden blijft. Als we willen werken met matrix A, kunnen we matrix A voorstellen als drie andere matrices genaamd U, D en V. Matrix A bestaat uit de oorspronkelijke x * y-elementen, terwijl matrix U bestaat uit elementen X * X (het is een orthogonale matrix). Matrix V is een andere orthogonale matrix die y * y elementen bevat. Matrix D bevat de elementen x * y en is een diagonale matrix.
Om de waarden voor matrix A te ontleden, moeten we de oorspronkelijke singuliere matrixwaarden converteren naar de diagonale waarden die in een nieuwe matrix zijn gevonden. Bij het werken met orthogonale matrices veranderen hun eigenschappen niet als ze worden vermenigvuldigd met andere getallen. Daarom kunnen we matrix A benaderen door gebruik te maken van deze eigenschap. Wanneer we de orthogonale matrices vermenigvuldigen met een transpositie van Matrix V, is het resultaat een equivalente matrix voor onze originele A.
Wanneer matrix a wordt ontleed in matrices U, D en V, bevatten ze de gegevens die in matrix A worden gevonden. De meest linkse kolommen van de matrices bevatten echter het grootste deel van de gegevens. We kunnen alleen deze eerste paar kolommen nemen en een representatie van Matrix A hebben die veel minder dimensies heeft en de meeste gegevens binnen A.
Lineaire discriminerende analyse

Links: matrix voor LDA, rechts: as na LDA, nu scheidbaar
Lineaire discriminatieanalyse (LDA) is een proces dat gegevens uit een multidimensionale grafiek haalt en projecteert het opnieuw op een lineaire grafiek. Je kunt je dit voorstellen door te denken aan een tweedimensionale grafiek gevuld met gegevenspunten die tot twee verschillende klassen behoren. Neem aan dat de punten zo verspreid liggen dat er geen lijn getrokken kan worden die de twee verschillende klassen netjes van elkaar scheidt. Om met deze situatie om te gaan, kunnen de gevonden punten in de 2D-grafiek worden gereduceerd tot een 1D-grafiek (een lijn). Op deze lijn zijn alle gegevenspunten verdeeld en hopelijk kan deze worden verdeeld in twee secties die de best mogelijke scheiding van de gegevens vertegenwoordigen.
Bij het uitvoeren van LDA zijn er twee hoofddoelen. Het eerste doel is het minimaliseren van de variantie voor de klassen, terwijl het tweede doel het maximaliseren van de afstand tussen de gemiddelden van de twee klassen is. Deze doelen worden bereikt door een nieuwe as te maken die in de 2D-grafiek zal bestaan. De nieuw gecreëerde as werkt om de twee klassen te scheiden op basis van de eerder beschreven doelen. Nadat de as is gemaakt, worden de gevonden punten in de 2D-grafiek langs de as geplaatst.
Er zijn drie stappen nodig om de oorspronkelijke punten naar een nieuwe positie langs de nieuwe as te verplaatsen. In de eerste stap wordt de afstand tussen de individuele klassengemiddelden (de variantie tussen klassen) gebruikt om de scheidbaarheid van de klassen te berekenen. In de tweede stap wordt de variantie binnen de verschillende klassen berekend door de afstand tussen de steekproef en het gemiddelde van de betreffende klasse te bepalen. In de laatste stap wordt de lager-dimensionale ruimte gecreëerd die de variantie tussen klassen maximaliseert.
De LDA-techniek bereikt de beste resultaten wanneer de middelen voor de doelklassen ver uit elkaar liggen. LDA kan de klassen niet effectief scheiden met een lineaire as als de middelen voor de verdelingen elkaar overlappen.










