로보틱스
로봇이 강화 학습을 통해 걸음을 배우다
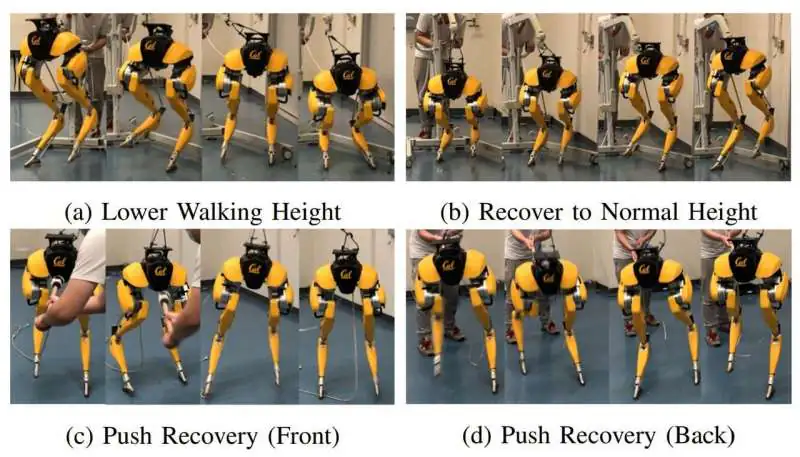
보통 Boston Dynamics와 댄싱 로봇이 주목받는 반면, 뒤에서 진행되는 주요 개발은 충분한 관심을 받지 못한다. 그런 개발 중 하나는 버클리 연구소에서 로봇 Cassie가 강화 학습을 통해 걸음을 배우는 것이었다.
시도와 오류를 거친 후, 로봇의 다리 쌍은 시뮬레이션 환경에서 탐색을 배우기 전에 실제 세계에서 테스트되었다. 처음에 로봇은 모든 방향으로 걸을 수 있는 능력을 보여주었고, 무릎을 구부린 채 걸을 수 있었고, 균형을 잃었을 때 자신을 재배치할 수 있었으며, 다양한 유형의 표면에 적응할 수 있었다.
Cassie 로봇은 강화 학습을 통해 걸음을 성공적으로 배우는 두 발 로봇의 첫 번째 예이다.
댄싱 로봇의 경이
Boston Dynamics와 같은 로봇은 매우 인상적이고 거의 모든 사람이 감탄할 정도지만, 몇 가지 주요 요소가 있다. 가장 주목할 점은 이러한 로봇이 결과를 얻기 위해 수동으로 프로그래밍되고 안무되었지만, 실제 상황에서는 이 방법이 선호되지 않는다.
연구소 밖에서 로봇은 강력하고, 탄력적이며, 유연해야 한다. 또한 예상치 못한 상황을 처리할 수 있어야 하며, 이는 로봇이 스스로 그러한 상황을 처리할 수 있도록 허용함으로써만 가능하다.
Zhongyu Li는 버클리 대학에서 Cassie를 작업하는 팀의 일원이었다.
“이러한 비디오는 일부 사람들에게 이것이 해결되고 쉬운 문제라는 믿음을 줄 수 있다”고 Li는 말했다. “하지만 우리는 인간 환경에서 인간형 로봇이 신뢰성 있게 작동하고 살아갈 수 있도록 하기 위해 아직 멀어야 한다”
https://www.youtube.com/watch?v=goxCjGPQH7U
강화 학습
这样的 로봇을 생성하기 위해 버클리 팀은 강화 학습에 의존했으며, 이는 DeepMind와 같은 회사에서 세계에서 가장 복잡한 게임에서 인간을 이길 수 있는 알고리즘을 훈련하는 데 사용되었다. 강화 학습은 시도와 오류에 기반하며, 로봇은 자신의 실수에서 배우는 것이다.
Cassie 로봇은 시뮬레이션에서 걸음을 배우기 위해 강화 학습을 사용했으며, 이는 처음 사용된 것이 아니다. 그러나 이것은 일반적으로 시뮬레이션 환경을 벗어나 실제 세계로 나가지 않는다. 작은 차이도 로봇이 걸을 수 없게 할 수 있다.
연구자들은 하나가 아닌 두 개의 시뮬레이션을 사용했으며, 첫 번째는 MuJoCo라는 오픈 소스 훈련 환경이었다. 첫 번째 시뮬레이션에서 알고리즘은 가능한 동작 라이브러리에 시도와 학습을 시도했으며, 두 번째 시뮬레이션인 SimMechanics에서 로봇은 더 실제적인 조건에서 그것들을 테스트했다.
두 시뮬레이션에서 개발된 후 알고리즘은 세부적으로 조정할 필요가 없었다. 이미 실제 세계에서 작동할 준비가 되었다. 걸을 수 있을 뿐만 아니라 더 많은 것을 할 수 있었다. 연구자에 따르면 Cassie는 로봇의 무릎에 있는 두 개의 모터가 고장 났음에도 불구하고 회복할 수 있었다.
Cassie는 다른 로봇과 비교했을 때 모든 종류의 기능을 가지고 있지는 않지만, 많은 면에서 훨씬 더 인상적이다. 또한 실제 사용에 관한 기술에 대해 더 큰 의미를 가진다. 그러한 걸음 로봇은 다양한 분야에서 사용될 수 있다.












