
신속한 엔지니어링
ChatGPT 및 고급 프롬프트 엔지니어링: AI 진화 주도

OpenAI는 교육 강화 알고리즘 및 GPT-n 모델을 위해 설계된 OpenAI Gym과 같은 혁신적인 도구를 개발하는 데 중요한 역할을 했습니다. 스포트라이트는 텍스트 입력에서 이미지를 만드는 AI 모델인 DALL-E에도 있습니다. 상당한 주목을 받은 그러한 모델 중 하나는 OpenAI의 ChatGPT, 대규모 언어 모델 영역에서 빛나는 모범입니다.
GPT-4: 신속한 엔지니어링
ChatGPT는 사용자 입력에 대해 인간과 같은 응답을 제공하고 소프트웨어 개발 및 테스트에서 비즈니스 커뮤니케이션, 심지어 시 작성까지 도메인 전반에 걸쳐 애플리케이션을 확장하여 챗봇 환경을 변화시켰습니다.
예를 들어 기업과 개인의 손에서 GPT-4는 수학과 생물학에서 법률 연구에 이르는 다양한 과목에 능숙한 무한한 지식 저장소 역할을 할 수 있습니다. 이러한 정교하고 접근 가능한 AI 모델은 일, 학습 및 창의성의 미래를 재정의할 준비가 되어 있습니다.

GPT-4와 같은 생성 모델은 기존 입력을 기반으로 새로운 데이터를 생성할 수 있습니다. 이 구별되는 속성을 통해 텍스트, 이미지, 음악 및 비디오 생성을 비롯한 다양한 작업을 수행할 수 있습니다.
ChatGPT 및 OpenAI 모델의 맥락에서 프롬프트는 일반적으로 텍스트 형식으로 사용자가 모델에 제공하는 입력입니다. 프롬프트는 이러한 모델에서 생성된 출력을 제어하는 기본 수단으로 사용되므로 성공적이고 관련성 높은 대화에 매우 중요합니다.
신속한 품질의 영향
AI 시스템과 유용하고 의미 있는 대화에 참여하려면 잘 정의된 프롬프트를 사용하는 것이 중요합니다. 잘못 정의된 프롬프트는 사용자에게 도움이 되지 않는 출력 결과를 초래할 수 있으며 심지어 잘못된 콘텐츠로 이어질 수도 있습니다.
프롬프트 품질의 영향을 보여주기 위해 ChatGPT에 제공된 두 가지 다른 프롬프트를 비교해 보겠습니다. 잘못 정의되고 사전 지식이 있다고 가정하는 첫 번째 프롬프트는 잠재적으로 사용자에게 도움이 되지 않는 응답을 생성합니다. 반면에 두 번째 프롬프트는 더 관련성 있고 이해하기 쉬운 응답을 보장하기 위해 더 많은 컨텍스트와 예를 제공합니다.
프롬프트 1: "Convolutional Neural Networks에 대해 알려주세요."
응답 1: “CNN(Convolutional Neural Networks)은 완전히 연결된 계층과 풀링 계층으로 구성된 다중 계층 퍼셉트론 네트워크입니다. 이미지 인식 작업에 일반적으로 사용됩니다. 이 프로세스에는 입력 이미지에 필터를 적용하고 풀링 레이어를 사용하여 축소하는 작업이 포함됩니다.”
프롬프트 2: “컨볼루션 신경망에 대해 배우고 싶지만 인공 신경망에 대한 사전 지식이 없습니다. 초보자에게 친숙한 설명과 CNN이 이미지 인식에 어떻게 사용되는지에 대한 예를 제공해 주실 수 있나요?”
응답 2: “CNN(Convolutional Neural Networks)은 이미지 인식 작업에 주로 사용되는 일종의 신경망입니다. 다른 신경망과 달리 합성곱 계층과 풀링 계층을 활용하여 이미지를 처리합니다. 고양이 이미지가 있다고 상상해보십시오. CNN은 필터를 적용하고 풀링 레이어를 사용하여 이미지를 다운샘플링하여 수염, 귀, 꼬리와 같은 이미지의 다양한 기능을 식별할 수 있습니다. 이 과정을 통해 CNN은 이미지에서 물체를 인식하는 데 매우 효과적입니다.”
두 응답을 비교하면 잘 정의된 프롬프트가 더 적절하고 사용자 친화적인 응답으로 이어진다는 것이 분명합니다. 신속한 설계 및 엔지니어링은 ChatGPT와 같은 AI 모델의 출력 품질을 최적화하는 것을 목표로 하는 분야가 성장하고 있습니다.
이 기사의 다음 섹션에서는 신속한 엔지니어링 기술 및 전술과 같은 LLM(Large Language Model)을 개선하기 위한 고급 방법론의 영역을 탐구합니다. 여기에는 퓨샷 학습, ReAct, 사고 사슬, RAG 등이 포함됩니다.
고급 엔지니어링 기술
진행하기 전에 '환각'이라고 하는 LLM의 주요 문제를 이해하는 것이 중요합니다. LLM의 맥락에서 '환각'은 합리적으로 보일 수 있지만 사실적 현실 또는 주어진 입력 컨텍스트에 뿌리를 두지 않는 출력을 생성하는 이러한 모델의 경향을 의미합니다.
이 문제는 변호인이 사용한 최근 법원 사건에서 극명하게 강조되었습니다. 법률 연구를 위한 ChatGPT. 환각 문제로 인해 흔들리는 AI 도구는 존재하지 않는 법적 사례를 인용했습니다. 이 실수는 중대한 영향을 미쳐 절차 중에 혼란을 야기하고 신뢰도를 떨어뜨렸습니다. 이 사건은 AI 시스템의 '환각' 문제를 해결해야 하는 시급한 필요성을 극명하게 상기시키는 역할을 합니다.
신속한 엔지니어링 기술에 대한 탐구는 LLM의 이러한 측면을 개선하는 것을 목표로 합니다. 효율성과 안전성을 강화하여 정보 추출과 같은 혁신적인 응용 프로그램의 길을 닦습니다. 또한 LLM을 외부 도구 및 데이터 소스와 원활하게 통합하여 잠재적 사용 범위를 넓힐 수 있습니다.
제로 및 퓨샷 학습: 예제를 통한 최적화
GPT-3(Generative Pretrained Transformers)는 Generative AI 모델 개발에 중요한 전환점이 되었습니다.극소수 학습.' 이 방법은 포괄적인 미세 조정 없이 효과적으로 작동할 수 있는 능력으로 인해 게임 체인저였습니다. GPT-3 프레임워크는 “언어 모델은 소수의 샷 학습자입니다.” 여기서 작성자는 사용자 지정 데이터 집합이나 코드가 필요 없이 다양한 사용 사례에서 모델이 어떻게 뛰어난지 보여줍니다.
다양한 사용 사례를 해결하기 위해 지속적인 노력이 필요한 미세 조정과 달리 소수 샷 모델은 더 광범위한 응용 프로그램에 더 쉽게 적응할 수 있음을 보여줍니다. 미세 조정은 경우에 따라 강력한 솔루션을 제공할 수 있지만 규모 면에서 비용이 많이 들 수 있으므로 특히 신속한 엔지니어링과 통합할 때 소수 샷 모델을 사용하는 것이 더 실용적인 접근 방식이 됩니다.
영어를 프랑스어로 번역하려고 한다고 상상해보세요. 퓨샷 학습에서는 "sea otter -> looutre de mer"와 같은 몇 가지 번역 예제를 GPT-3에 제공합니다. 고급 모델인 GPT-3는 계속해서 정확한 번역을 제공할 수 있습니다. 제로샷 학습에서는 예제를 제공하지 않아도 GPT-3는 여전히 영어를 프랑스어로 효과적으로 번역할 수 있습니다.
'퓨샷 학습(few-shot learning)'이라는 용어는 모델에 '학습'할 수 있는 제한된 수의 예제가 제공된다는 생각에서 비롯되었습니다. 이 맥락에서 '학습'은 모델의 매개변수 또는 가중치 업데이트를 포함하지 않고 오히려 모델의 성능에 영향을 미친다는 점에 유의해야 합니다.

GPT-3 논문에서 입증된 몇 가지 샷 학습
제로 샷 학습은 이 개념을 한 단계 더 발전시킵니다. 제로샷 학습에서는 작업 완료의 예가 모델에 제공되지 않습니다. 이 모델은 초기 교육을 기반으로 잘 수행될 것으로 예상되므로 이 방법론은 ChatGPT와 같은 개방형 도메인 질문 응답 시나리오에 이상적입니다.
많은 경우에 제로샷 학습에 능숙한 모델은 퓨샷 또는 싱글샷 예제와 함께 제공될 때 잘 수행할 수 있습니다. 제로, 단일 및 소수 학습 시나리오 사이를 전환하는 이 기능은 대규모 모델의 적응성을 강조하여 다양한 도메인에서 잠재적인 응용 프로그램을 향상시킵니다.
Zero-shot 학습 방법이 점점 보편화되고 있습니다. 이러한 방법은 훈련 중에 보이지 않는 물체를 인식하는 기능이 특징입니다. 다음은 Few-Shot Prompt의 실제 예입니다.
"Translate the following English phrases to French:
'sea otter' translates to 'loutre de mer'
'sky' translates to 'ciel'
'What does 'cloud' translate to in French?'"
모델에 몇 가지 예를 제공한 다음 질문을 함으로써 원하는 출력을 생성하도록 모델을 효과적으로 안내할 수 있습니다. 이 경우 GPT-3는 프랑스어로 'cloud'를 'nuage'로 올바르게 번역할 가능성이 높습니다.
신속한 엔지니어링의 다양한 뉘앙스와 추론 중에 모델 성능을 최적화하는 데 있어 필수적인 역할에 대해 더 깊이 탐구할 것입니다. 또한 광범위한 사용 사례에서 비용 효율적이고 확장 가능한 솔루션을 만드는 데 효과적으로 사용할 수 있는 방법을 살펴봅니다.
GPT 모델에서 신속한 엔지니어링 기술의 복잡성을 자세히 살펴보면서 지난 게시물 'ChatGPT의 신속한 엔지니어링을 위한 필수 가이드'. 이 가이드는 수많은 사용 사례에서 AI 모델을 효과적으로 지시하기 위한 전략에 대한 통찰력을 제공합니다.
이전 논의에서 우리는 제로샷 및 퓨샷 학습과 같은 대규모 언어 모델(LLM)에 대한 기본적인 프롬프트 방법과 명령 프롬프팅에 대해 자세히 살펴보았습니다. 이러한 기술을 마스터하는 것은 여기에서 살펴볼 신속한 엔지니어링의 보다 복잡한 문제를 탐색하는 데 중요합니다.
대부분의 LLM의 제한된 컨텍스트 창으로 인해 퓨샷 학습이 제한될 수 있습니다. 또한 적절한 보호 장치가 없으면 LLM이 잠재적으로 유해한 결과를 제공하도록 오도될 수 있습니다. 또한 많은 모델이 추론 작업이나 다단계 지침을 따르는 데 어려움을 겪고 있습니다.
이러한 제약 조건을 고려할 때 문제는 LLM을 활용하여 복잡한 작업을 처리하는 데 있습니다. 확실한 해결책은 고급 LLM을 개발하거나 기존 LLM을 개선하는 것이지만 상당한 노력이 필요할 수 있습니다. 문제 해결 개선을 위해 현재 모델을 어떻게 최적화할 수 있습니까?
똑같이 매력적인 것은 이 기술이 Unite AI의 'AI 아트 마스터하기: 중간 여정 및 신속한 엔지니어링에 대한 간결한 가이드'는 예술과 AI의 융합이 어떻게 경외심을 불러일으키는 예술로 귀결될 수 있는지 설명합니다.
생각의 연쇄 촉진
사고 사슬 프롬프트는 주어진 시퀀스에서 다음 단어를 예측하는 데 뛰어난 대규모 언어 모델(LLM)의 고유한 자동 회귀 속성을 활용합니다. 모델이 자신의 사고 과정을 설명하도록 유도함으로써 보다 철저하고 체계적인 아이디어 생성을 유도하며, 이는 정확한 정보와 밀접하게 일치하는 경향이 있습니다. 이러한 정렬은 복잡한 개념을 통해 청취자를 안내하는 인간 전문가와 유사하게 사려 깊고 정돈된 방식으로 정보를 처리하고 전달하려는 모델의 성향에서 비롯됩니다. "...을(를) 단계별로 안내해 주세요.
제로샷 사고 사슬 프롬프트
기존의 CoT 프롬프팅에는 시연을 통한 사전 교육이 필요하지만 새로운 영역은 제로 샷 CoT 프롬프팅입니다. 이 접근법은 Kojima et al. (2022)는 기존 프롬프트에 “차근차근 생각해보자”라는 문구를 혁신적으로 추가했다.
ChatGPT가 AI 및 NLP 연구 논문의 주요 내용을 요약하는 고급 프롬프트를 만들어 보겠습니다.
이 데모에서는 학술 텍스트의 복잡한 정보를 이해하고 요약하는 모델의 기능을 사용합니다. 퓨샷 학습 접근 방식을 사용하여 AI 및 NLP 연구 논문의 주요 결과를 요약하도록 ChatGPT를 교육해 보겠습니다.
1. Paper Title: "Attention Is All You Need"
Key Takeaway: Introduced the transformer model, emphasizing the importance of attention mechanisms over recurrent layers for sequence transduction tasks.
2. Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks.
Now, with the context of these examples, summarize the key findings from the following paper:
Paper Title: "Prompt Engineering in Large Language Models: An Examination"
이 프롬프트는 명확한 사고 사슬을 유지할 뿐만 아니라 모델을 안내하기 위해 몇 번의 학습 접근 방식을 사용합니다. AI 및 NLP 도메인에 중점을 두고 특히 ChatGPT가 신속한 엔지니어링과 관련된 복잡한 작업(연구 논문 요약)을 수행하도록 함으로써 우리의 키워드와 연결됩니다.
반응 프롬프트
React 또는 "Reason and Act"는 Google이 "논문"에서 소개했습니다.ReAct: 언어 모델에서 추론과 행동의 시너지 효과", 그리고 언어 모델이 작업과 상호 작용하는 방식을 혁신하여 모델이 언어적 추론 추적과 작업별 작업을 모두 동적으로 생성하도록 유도했습니다.
주방에 있는 인간 요리사를 상상해 보십시오. 그들은 일련의 행동(야채 자르기, 물 끓이기, 재료 섞기)을 수행할 뿐만 아니라 언어적 추론이나 내면의 말(“이제 야채를 잘랐으니 냄비를 올려야 합니다. 스토브"). 이 지속적인 정신적 대화는 프로세스를 전략화하고 갑작스러운 변화에 적응하고(“올리브 오일이 부족합니다. 대신 버터를 사용하겠습니다.”) 작업 순서를 기억하는 데 도움이 됩니다. React는 이러한 인간의 능력을 모방하여 인간이 새롭거나 불확실한 상황에서 하듯이 모델이 새로운 작업을 빠르게 배우고 강력한 결정을 내릴 수 있도록 합니다.
React는 CoT(Chain-of-Thought) 시스템의 일반적인 문제인 환각을 해결할 수 있습니다. CoT는 효과적인 기술이지만 외부 세계와 상호 작용할 수 있는 능력이 부족하여 잠재적으로 사실 환각 및 오류 전파로 이어질 수 있습니다. 그러나 React는 외부 정보 소스와 인터페이스하여 이를 보완합니다. 이 상호 작용을 통해 시스템은 추론을 검증할 뿐만 아니라 외부 세계의 최신 정보를 기반으로 지식을 업데이트할 수 있습니다.
React의 기본 작업은 고차 추론이 필요한 작업인 HotpotQA의 인스턴스를 통해 설명할 수 있습니다. 질문을 받으면 React 모델은 질문을 관리 가능한 부분으로 나누고 행동 계획을 만듭니다. 모델은 추론 추적(생각)을 생성하고 관련 작업을 식별합니다. Wikipedia(동작)와 같은 외부 소스에서 Apple Remote에 대한 정보를 조회하고 획득한 정보(관찰)를 기반으로 이해를 업데이트하기로 결정할 수 있습니다. 여러 생각-행동-관찰 단계를 통해 ReAct는 추론을 지원하는 정보를 검색하는 동시에 다음에 검색해야 하는 것을 정제할 수 있습니다.
참고 :
핫팟 QA 질문에 답하려면 여러 문서에 대한 추론이 필요하기 때문에 복잡한 추론에서 AI 시스템을 교육하도록 설계된 113k 질문-답변 쌍으로 구성된 Wikipedia에서 파생된 데이터 세트입니다. 반면에, 상식QA 게임화를 통해 구성된 2.0에는 14,343개의 예/아니오 질문이 포함되어 있으며 질문이 AI 모델을 오도하도록 의도적으로 만들어졌기 때문에 상식에 대한 AI의 이해에 도전하도록 설계되었습니다.
프로세스는 다음과 같을 수 있습니다.
- 생각: "Apple Remote와 호환 장치를 검색해야 합니다."
- 동작: 외부 소스에서 "Apple Remote 호환 장치"를 검색합니다.
- 관찰: 검색 결과에서 Apple Remote와 호환되는 장치 목록을 가져옵니다.
- 생각: "검색 결과에 따르면 Apple Remote 외에도 여러 장치에서 원래 상호 작용하도록 설계된 프로그램을 제어할 수 있습니다."
그 결과 상호 작용하는 정보를 기반으로 진화할 수 있는 역동적인 추론 기반 프로세스가 생성되어 보다 정확하고 신뢰할 수 있는 응답으로 이어집니다.

HotpotQA 및 AlfWorld(https://arxiv.org/pdf/2210.03629.pdf)를 해결하는 네 가지 프롬프트 방법(Standard, Chain-of-Thought, Act-Only 및 ReAct)의 비교 시각화
React 에이전트 설계는 복잡한 목표를 달성할 수 있는 능력을 감안할 때 전문화된 작업입니다. 예를 들어 기본 React 모델을 기반으로 구축된 대화형 에이전트는 대화형 메모리를 통합하여 더 풍부한 상호 작용을 제공합니다. 그러나 이 작업의 복잡성은 이러한 에이전트 설계의 표준이 된 Langchain과 같은 도구로 간소화됩니다.
상황에 맞는 프롬프트
종이 '대규모 언어 모델을 위한 상황에 맞는 프롬프트'는 LLM이 지식 기반 NLP 작업에서 상당한 성공을 거두었지만 매개 변수 지식에 대한 과도한 의존으로 상황에 맞는 작업에서 길을 잃을 수 있음을 강조합니다. 예를 들어, 언어 모델이 오래된 사실에 대해 학습될 때 문맥상의 단서를 간과하면 잘못된 답변을 생성할 수 있습니다.
이 문제는 컨텍스트가 LLM의 기존 지식과 다른 사실을 포함하는 지식 충돌의 경우에 명백합니다. 2022년 월드컵 이전의 데이터로 준비된 LLM(Large Language Model)에 프랑스가 토너먼트에서 우승했음을 나타내는 컨텍스트가 제공된 경우를 생각해 보십시오. 그러나 사전 훈련된 지식에 의존하는 LLM은 이전 승자, 즉 2018년 월드컵에서 우승한 팀이 여전히 군림하는 챔피언이라고 계속 주장합니다. 이것은 '지식 충돌'의 전형적인 사례를 보여줍니다.
본질적으로 LLM의 지식 충돌은 컨텍스트에서 제공된 새로운 정보가 모델이 훈련된 기존 지식과 모순될 때 발생합니다. 새로 제공된 컨텍스트가 아닌 이전 교육에 의존하는 모델의 경향으로 인해 잘못된 출력이 발생할 수 있습니다. 반면에 LLM의 환각은 그럴듯해 보이지만 모델의 교육 데이터 또는 제공된 컨텍스트에 뿌리를 두지 않는 반응의 생성입니다.
제공된 컨텍스트에 질문에 정확하게 대답할 수 있는 충분한 정보가 포함되어 있지 않은 경우 또 다른 문제가 발생합니다. 기권으로 예측. 예를 들어 LLM이 이 정보를 제공하지 않는 컨텍스트를 기반으로 Microsoft 설립자에 대해 묻는 경우 이상적으로는 추측을 삼가야 합니다.
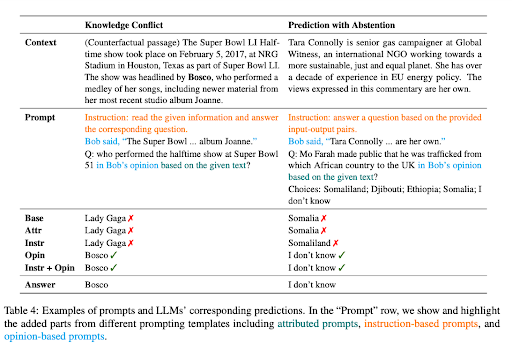
더 많은 지식 갈등과 기권의 힘 예
이러한 시나리오에서 LLM의 상황에 맞는 충실도를 개선하기 위해 연구자들은 다양한 촉진 전략을 제안했습니다. 이러한 전략은 LLM의 응답이 인코딩된 지식에 의존하기보다 상황에 더 잘 맞도록 만드는 것을 목표로 합니다.
이러한 전략 중 하나는 프롬프트를 의견 기반 질문으로 구성하는 것입니다. 여기서 컨텍스트는 내레이터의 진술로 해석되고 질문은 이 내레이터의 의견과 관련됩니다. 이 접근 방식은 LLM의 기존 지식에 의존하지 않고 제시된 컨텍스트에 다시 집중합니다.
프롬프트에 반사실 시연을 추가하는 것도 지식 충돌의 경우 충실도를 높이는 효과적인 방법으로 확인되었습니다. 이러한 시연은 정확한 응답을 제공하기 위해 모델이 상황에 더 주의를 기울이도록 안내하는 잘못된 사실이 있는 시나리오를 제시합니다.
명령어 미세 조정
명령 미세 조정은 "일출과 일몰의 차이를 설명하십시오."와 같은 특정 지침을 모델에 제공하는 것을 활용하는 지도 학습 단계입니다. 지침은 "일출은 아침에 태양이 지평선 너머로 나타나는 순간을 말하며, 일몰은 저녁에 태양이 수평선 아래로 사라지는 지점을 표시합니다."와 같은 적절한 답변과 짝을 이룹니다. 이 방법을 통해 모델은 본질적으로 지침을 준수하고 실행하는 방법을 학습합니다.
이 접근 방식은 LLM을 프롬프트하는 프로세스에 상당한 영향을 미치므로 프롬프트 스타일에 급격한 변화를 가져옵니다. 명령이 미세 조정된 LLM은 제로 샷 작업을 즉시 실행하여 원활한 작업 성능을 제공합니다. LLM이 아직 미세 조정되지 않은 경우 몇 가지 예를 프롬프트에 통합하여 원하는 응답으로 모델을 안내하는 몇 가지 학습 접근 방식이 필요할 수 있습니다.
"GPT-4′로 명령어 튜닝 GPT-4를 사용하여 LLM을 미세 조정하기 위해 명령을 따르는 데이터를 생성하려는 시도에 대해 설명합니다. 그들은 영어와 중국어로 된 52,000개의 고유한 지침 따르기 항목으로 구성된 풍부한 데이터 세트를 사용했습니다.
데이터 세트는 명령어 튜닝에서 중추적인 역할을 합니다. 라마 모델, LLM의 오픈 소스 시리즈로, 새로운 작업에서 향상된 제로샷 성능을 제공합니다. 다음과 같은 주목할만한 프로젝트 스탠포드 알파카 고급 교육 조정 교사 모델에서 생성된 데이터를 활용하여 LLM을 인간의 의도에 맞추는 효율적인 방법인 Self-Instruct 튜닝을 효과적으로 사용했습니다.

명령어 튜닝 연구의 주요 목표는 LLM의 제로 및 소수 샷 일반화 능력을 향상시키는 것입니다. 추가 데이터 및 모델 확장은 귀중한 통찰력을 제공할 수 있습니다. 현재 GPT-4 데이터 크기가 52K이고 기본 LLaMA 모델 크기가 7억 매개변수인 경우 더 많은 GPT-4 명령을 따르는 데이터를 수집하고 이를 다른 데이터 소스와 결합하여 더 큰 LLaMA 모델을 교육할 수 있는 엄청난 잠재력이 있습니다. 우수한 성능을 위해.
STAR: 추론을 통한 부트스트래핑 추론
LLM의 잠재력은 수학이나 상식적인 질문 답변과 같은 복잡한 추론 작업에서 특히 눈에 띕니다. 그러나 일련의 단계별 정당화 또는 "사고 사슬"과 같은 근거를 생성하기 위해 언어 모델을 유도하는 프로세스에는 일련의 문제가 있습니다. 소수 샷 추론에만 의존하기 때문에 큰 근거 데이터 세트를 구성하거나 정확성을 희생해야 하는 경우가 많습니다.
"독학으로 추론하는 사람"(별)는 이러한 문제에 대한 혁신적인 솔루션을 제공합니다. 간단한 루프를 활용하여 모델의 추론 능력을 지속적으로 향상시킵니다. 이 반복 프로세스는 몇 가지 합리적인 예를 사용하여 여러 질문에 답하기 위한 근거를 생성하는 것으로 시작합니다. 생성된 답변이 올바르지 않으면 모델은 다시 근거를 생성하려고 시도하며 이번에는 정답을 제공합니다. 그런 다음 정답을 도출한 모든 근거에 따라 모델을 미세 조정하고 프로세스를 반복합니다.

STaR 방법론, CommonsenseQA 데이터세트(https://arxiv.org/pdf/2203.14465.pdf)에 대한 미세 조정 루프 및 샘플 이론적 근거 생성 시연
실용적인 예를 통해 이를 설명하기 위해 "작은 개를 운반하는 데 사용할 수 있는 것은 무엇입니까?"라는 질문을 고려하십시오. 수영장에서 바구니에 이르기까지 다양한 답을 선택할 수 있습니다. STAR 모델은 답변이 작은 개를 태울 수 있는 것이어야 함을 식별하고 물건을 담도록 설계된 바구니가 정답이라는 결론에 도달하는 이론적 근거를 생성합니다.
STaR의 접근 방식은 언어 모델의 기존 추론 능력을 활용한다는 점에서 독특합니다. 그것은 모델의 추론 기능을 반복적으로 부트스트래핑하면서 이론적 근거의 자체 생성 및 개선 프로세스를 사용합니다. 그러나 STAR의 루프에는 한계가 있습니다. 모델이 해결하지 못한 문제에 대한 직접적인 훈련 신호를 받지 못하기 때문에 훈련 세트의 새로운 문제를 해결하지 못할 수 있습니다. 이 문제를 해결하기 위해 STaR은 합리화를 도입했습니다. 모델이 올바르게 대답하지 못하는 각 문제에 대해 모델이 거꾸로 추론할 수 있도록 모델에 정답을 제공하여 새로운 근거를 생성합니다.
따라서 STaR은 모델이 자신의 근거를 생성하는 방법을 배우면서 점점 더 어려워지는 문제를 해결하는 방법을 배울 수 있는 확장 가능한 부트스트래핑 방법입니다. STaR의 적용은 산술, 수학 단어 문제 및 상식 추론과 관련된 작업에서 유망한 결과를 보여주었습니다. CommonsenseQA에서 STaR은 답을 직접 예측하기 위해 미세 조정된 몇 샷 기준선과 기준선 모두에서 개선되었으며 30배 더 큰 모델과 유사하게 수행되었습니다.
태그가 지정된 컨텍스트 프롬프트
'라는 개념태그가 지정된 컨텍스트 프롬프트'는 입력 내 특정 정보에 태그를 지정하여 AI 모델에 추가 컨텍스트 계층을 제공하는 것을 중심으로 합니다. 이러한 태그는 기본적으로 AI의 이정표 역할을 하여 컨텍스트를 정확하게 해석하고 관련성 있고 사실에 입각한 응답을 생성하는 방법을 안내합니다.
특정 주제에 대해 친구와 대화를 나누고 있다고 상상해보십시오. '체스'라고합시다. 진술을 한 다음 '(출처: Wikipedia)'와 같은 참조로 태그를 지정합니다. 이제 이 경우 AI 모델인 당신의 친구는 당신의 정보가 어디에서 오는지 정확히 알고 있습니다. 이 접근 방식은 환각의 위험이나 잘못된 사실 생성을 줄여 AI의 응답을 보다 안정적으로 만드는 것을 목표로 합니다.
태그가 있는 컨텍스트 프롬프트의 고유한 측면은 AI 모델의 '컨텍스트 인텔리전스'를 개선할 수 있는 잠재력입니다. 예를 들어, 이 논문은 최근 출판된 책의 다양한 주제 및 섹션에 대한 요약된 Wikipedia 기사와 같은 여러 출처에서 추출된 다양한 질문 세트를 사용하여 이를 입증합니다. 질문에 태그가 지정되어 AI 모델에 정보 소스에 대한 추가 컨텍스트를 제공합니다.
이 추가 컨텍스트 레이어는 정확할 뿐만 아니라 제공된 컨텍스트를 준수하는 응답을 생성하여 AI의 출력을 보다 안정적이고 신뢰할 수 있게 만드는 데 매우 유용할 수 있습니다.
결론: 유망한 기술과 향후 방향에 대한 고찰
OpenAI의 ChatGPT는 복잡한 작업을 놀라운 효율성으로 처리하는 데 있어 LLM(대형 언어 모델)의 미지의 잠재력을 보여줍니다. 퓨샷 학습, ReAct 프롬프팅, 사고 사슬, STaR과 같은 고급 기술을 통해 수많은 애플리케이션에서 이러한 잠재력을 활용할 수 있습니다. 이러한 방법론의 뉘앙스를 더 깊이 파고 들면서 인간과 기계 간의 보다 풍부하고 안전한 상호 작용을 제공하면서 AI의 환경을 어떻게 형성하고 있는지 발견합니다.
지식 충돌, 파라메트릭 지식에 대한 지나친 의존, 환각 가능성과 같은 문제에도 불구하고 이러한 AI 모델은 적절한 신속한 엔지니어링을 통해 혁신적인 도구임이 입증되었습니다. 지침 미세 조정, 상황에 맞는 충실한 프롬프트 및 외부 데이터 소스와의 통합은 추론, 학습 및 적응 능력을 더욱 증폭시킵니다.















