
인공 지능
Deepfake 비디오의 충실도 대 현실감

모든 딥페이크 실무자가 동일한 목표를 공유하는 것은 아닙니다. 어도비 벽돌, NVIDIA 및 페이스북 – 기계 학습 기술이 궁극적으로 가장 까다로운 조건에서 고해상도로 인간 활동을 재현하거나 합성할 수 있도록 최첨단 기술을 발전시키는 것입니다(충실도).
대조적으로, 딥페이크 기술을 사용하여 허위 정보를 퍼뜨리려는 사람들의 목표는 단순히 딥페이크된 얼굴의 진실성이 아닌 다른 많은 방법으로 실제 사람의 그럴듯한 시뮬레이션을 만드는 것입니다. 이 시나리오에서 맥락 및 타당성과 같은 부가적인 요소는 얼굴을 시뮬레이션하는 비디오의 잠재력과 거의 동일합니다. (실재론).
이 '손놀림' 접근 방식은 딥페이크 비디오의 최종 이미지 품질 저하까지 확장되어 전체 비디오(딥페이크 얼굴로 표현되는 기만적인 부분뿐만 아니라)가 정확하고 응집력 있는 '룩'을 갖게 합니다. 매체에 대한 예상 품질.
'결합력'이 '좋음'을 의미할 필요는 없습니다. 품질이 원본과 삽입된 변조된 콘텐츠에서 일관되고 기대에 부합하는 것으로 충분합니다. Skype 및 Zoom과 같은 플랫폼의 VOIP 스트리밍 출력 측면에서 끊김, 비디오 끊김, 잠재적인 압축 아티팩트의 전체 범위, 그리고 그 효과를 줄이기 위해 설계된 '스무딩' 알고리즘으로 인해 막대가 현저히 낮을 수 있습니다. 그 자체로 우리가 라이브 스트리밍의 제약과 편심에 대한 결과로 받아들인 '진짜가 아닌' 효과의 추가 범위를 구성합니다.
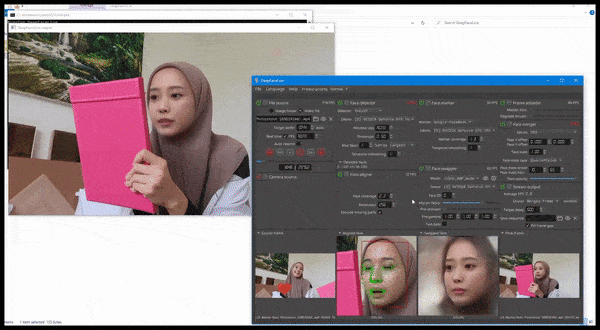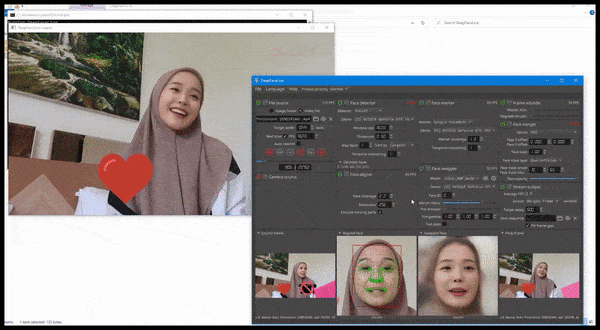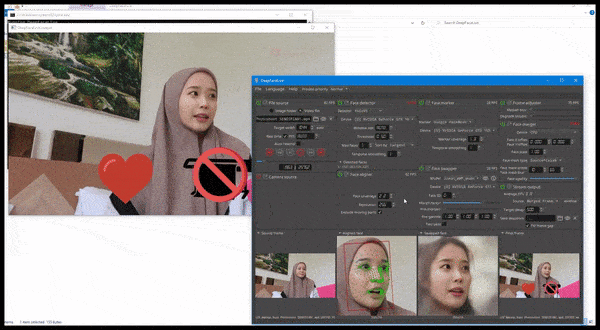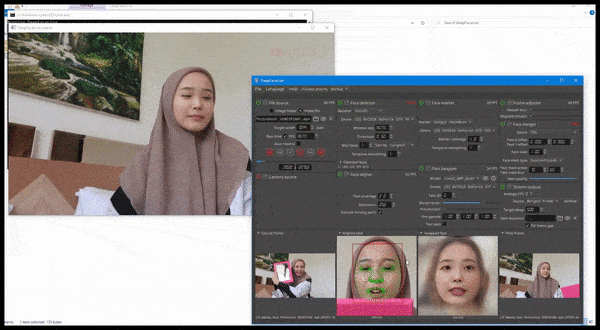
DeepFaceLive 실행: 프리미어 딥페이크 소프트웨어 DeepFaceLab의 이 스트리밍 버전은 재생 문제 및 기타 반복적인 연결 아티팩트가 있는 제한된 비디오 품질의 맥락에서 가짜를 제시함으로써 상황에 맞는 사실감을 제공할 수 있습니다. 출처: https://www.youtube.com/watch?v=IL517EgYH8U
내장된 저하
실제로 가장 인기 있는 딥페이크 패키지 두 개(둘 다 논란의 여지가 있는 2017년 소스 코드에서 파생됨)에는 생성된 얼굴을 저하시켜 딥페이크된 얼굴을 '역사적' 또는 저품질 비디오의 맥락에 통합하기 위한 구성 요소가 포함되어 있습니다. ~ 안에 딥페이스랩Walk Through California 프로그램, bicubic_degrade_power 매개변수는 이를 수행하고 페이스 스왑, Ffmpeg 구성의 '그레인' 설정도 마찬가지로 인코딩 중에 그레인을 보존하여 가짜 얼굴의 통합을 돕습니다*.

FaceSwap의 '그레인' 설정은 비HQ 비디오 콘텐츠와 요즘 상대적으로 드문 필름 그레인 효과를 특징으로 할 수 있는 레거시 콘텐츠로의 진정한 통합을 돕습니다.
종종 완전하고 통합된 딥페이크 비디오 대신, 딥페이커는 알파 채널이 있는 일련의 격리된 PNG 파일을 출력합니다. 각 이미지는 합성 얼굴 출력만 보여줌으로써 이미지 스트림을 보다 정교한 '플랫폼에서 비디오로 변환할 수 있습니다.저하 효과 기능, Adobe After Effects와 같은 가짜 요소와 실제 요소가 최종 비디오를 위해 함께 결합되기 전에.
이러한 의도적인 저하 외에도 딥페이크 작업의 콘텐츠는 YouTube 및 Facebook과 같은 플랫폼에서 알고리즘(소셜 미디어 플랫폼이 사용자 업로드의 더 가벼운 버전을 생성하여 대역폭을 절약하려는 경우) 또는 원본 작업을 다음으로 재처리하여 자주 재압축됩니다. 애니메이션 GIF, 세부 섹션 또는 원본 릴리스를 시작점으로 취급하고 이후에 추가 압축을 도입하는 기타 다양하게 동기 부여된 워크플로.
현실적인 Deepfake 탐지 컨텍스트
이를 염두에 두고 스위스의 새로운 논문은 딥페이크 콘텐츠가 의도적으로 저하된 상황에서 표시될 때 딥페이크 콘텐츠의 특성을 학습하도록 탐지 시스템을 교육함으로써 딥페이크 탐지 접근 방식의 방법론을 개편할 것을 제안했습니다.

가우시안 노이즈, 감마 보정, 가우시안 블러, JPEG 압축의 아티팩트를 특징으로 하는 새로운 논문에 사용된 데이터 세트 중 하나에 적용된 확률적 데이터 증대. 출처 : https://arxiv.org/pdf/2203.11807.pdf
새 논문에서 연구원들은 뱅가드 딥페이크 탐지 패키지가 적용하는 메트릭의 맥락에서 비현실적인 벤치마크 조건에 의존하고 있으며, '저하된' 딥페이크 출력은 탐지를 위한 최소 품질 임계값 아래로 떨어질 수 있다고 주장합니다. '지저분한' 콘텐츠는 맥락에 대한 올바른 주의로 인해 시청자를 속일 수 있습니다.
연구자들은 '깨끗한' 데이터로 얻은 원래 탐지율의 정확도를 약간만 손실하면서 선도적인 딥페이크 탐지기의 일반화 가능성을 개선하는 데 성공한 새로운 '실제' 데이터 저하 프로세스를 도입했습니다. 또한 광범위한 절제 연구로 지원되는 실제 조건에서 딥페이크 탐지기의 견고성을 평가할 수 있는 새로운 평가 프레임워크를 제공합니다.
XNUMXD덴탈의 종이 제목이 현실적인 조건에서 학습 기반 Deepfake 탐지를 개선하기 위한 새로운 접근 방식, MMSPG(Multimedia Signal Processing Group) 및 EPFL(Ecole Polytechnique Federale de Lausanne)의 연구원들이 제공하며 둘 다 로잔에 기반을 두고 있습니다.
유용한 혼란
저하된 출력을 딥페이크 탐지 방식에 통합하려는 이전 노력에는 다음이 포함됩니다. 혼합 신경망, MIT 및 FAIR의 2018년 제안 및 AugMix, DeepMind와 Google 간의 2020년 공동 작업으로 일반화에 도움이 되는 방식으로 교육 자료를 '혼란'시키려는 데이터 증대 방법입니다.
새로운 작업의 연구원들은 또한 주목합니다. 이전에 연구 파생된 기능과 포함된 노이즈 사이의 관계 경계를 설정하기 위해 훈련 데이터에 가우시안 노이즈 및 압축 아티팩트를 적용했습니다.
새로운 연구는 이미징 및 압축을 위한 획득 프로세스의 손상된 조건과 배포 프로세스에서 이미지 출력을 더욱 저하시킬 수 있는 다양한 기타 알고리즘을 시뮬레이션하는 파이프라인을 제공합니다. 이 실제 워크플로를 평가 프레임워크에 통합하면 아티팩트에 더 강한 딥페이크 탐지기를 위한 교육 데이터를 생성할 수 있습니다.

새로운 접근 방식에 대한 개념적 논리 및 작업 흐름.
성능 저하 프로세스는 딥페이크 탐지에 사용되는 두 가지 인기 있고 성공적인 데이터 세트에 적용되었습니다. FaceForensics ++ 및 Celeb-DFv2. 또한 선도적인 딥페이크 탐지기 프레임워크 캡슐 법의학 및 XceptionNet 두 데이터 세트의 불량 버전에 대해 교육을 받았습니다.
검출기는 Adam 옵티마이저로 각각 25세대와 10세대 동안 학습되었습니다. 데이터 세트 변환을 위해 각 교육 비디오에서 100개의 프레임을 무작위로 샘플링했으며, 성능 저하 프로세스를 추가하기 전에 테스트를 위해 32개의 프레임을 추출했습니다.
작업 흐름에 대해 고려된 왜곡은 소음여기서 제로 평균 가우시안 노이즈는 XNUMX가지 다양한 레벨에서 적용되었습니다. 크기 조정, 일반적인 야외 푸티지의 감소된 해상도를 시뮬레이트합니다. 일반적으로 영향을 미칩니다 검출기; 압축, 여기서 다양한 JPEG 압축 수준이 데이터에 적용되었습니다. 다듬기, 여기서 '노이즈 제거'에 사용되는 세 가지 일반적인 스무딩 필터가 프레임워크에 대해 평가됩니다. 상승, 여기서 대비와 밝기가 조정되었습니다. 그리고 조합, 위에서 언급한 세 가지 방법의 혼합이 단일 이미지에 동시에 적용되었습니다.
테스트 및 결과
데이터를 테스트하면서 연구자들은 세 가지 메트릭을 채택했습니다. 정확도(ACC); 수신기 작동 특성 곡선 아래 영역(AUC); 과 F1 점수.
연구원들은 변조된 데이터에 대해 두 가지 딥페이크 탐지기의 표준 훈련 버전을 테스트했으며 다음과 같은 결함이 있음을 발견했습니다.
'일반적으로 대부분의 사실적인 왜곡과 처리는 정상적으로 훈련된 학습 기반 딥페이크 탐지기에 매우 해롭습니다. 예를 들어 Capsule-Forensics 방법은 각각의 데이터 세트에 대한 교육 후 압축되지 않은 FFpp 및 Celeb-DFv2 테스트 세트 모두에서 매우 높은 AUC 점수를 나타내지만 평가 프레임워크에서 수정된 데이터에 대한 급격한 성능 저하를 겪습니다. 유사한 경향이 XceptionNet 감지기로 관찰되었습니다.'
대조적으로 두 탐지기의 성능은 변환된 데이터에 대한 훈련을 통해 눈에 띄게 향상되었으며 이제 각 탐지기는 보이지 않는 사기성 미디어를 더 많이 탐지할 수 있습니다.
'데이터 증가 방식은 두 검출기의 견고성을 크게 향상시키는 동시에 원본 변경되지 않은 데이터에서 여전히 높은 성능을 유지합니다.'

연구에서 평가된 두 개의 딥페이크 탐지기에서 사용된 원시 및 증강 데이터 세트 간의 성능 비교.
이 논문은 다음과 같이 결론을 내립니다.
'현재 감지 방법은 특정 벤치마크에서 가능한 한 높은 성능을 달성하도록 설계되었습니다. 이것은 종종 보다 현실적인 시나리오에 대한 일반화 능력을 희생시키는 결과를 낳습니다. 본 논문에서는 자연스러운 이미지 저하 과정을 기반으로 신중하게 고안된 데이터 증대 기법을 제안한다.
'광범위한 실험은 간단하지만 효과적인 기술이 일반적인 이미징 워크플로우에서 다양한 사실적인 왜곡 및 처리 작업에 대한 모델 견고성을 크게 향상시킨다는 것을 보여줍니다.'
* 생성된 면의 일치하는 그레인은 변환 프로세스 중 스타일 전송 기능입니다.
29년 2022월 8일에 처음 게시되었습니다. Ffmpeg의 곡물 사용을 명확히 하기 위해 EST 오후 33시 XNUMX분에 업데이트되었습니다.















