人工知能
SofGAN: より高度な制御を可能にするGAN顔生成器
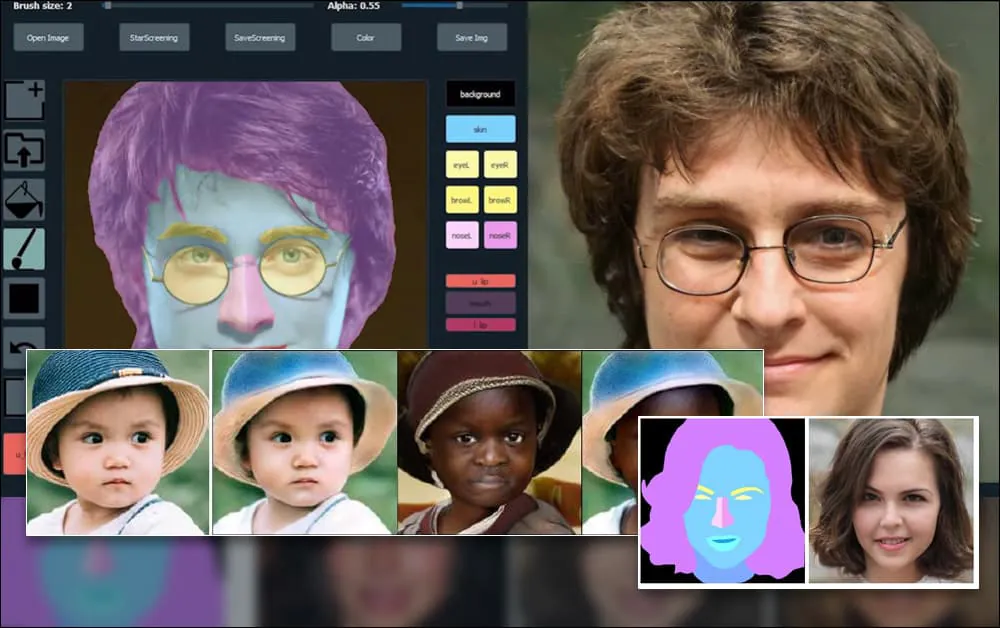
上海と米国の研究者らは、髪、目、メガネ、テクスチャ、色などの個々の要素に対して、これまでにないレベルの制御を可能にし、新しい顔を作成できるGANベースの肖像画生成システムを開発しました。 このシステムの汎用性を示すため、作成者はPhotoshop風のインターフェースを提供しています。ユーザーはセマンティックセグメンテーション要素を直接描画でき、それがリアルな画像に再解釈されます。既存の写真の上に直接描画することで取得することも可能です。 以下の例では、俳優ダニエル・ラドクリフの写真がトレースのテンプレートとして使用されています(目的は彼に似せることではなく、一般的に写実的な画像を生成することです)。ユーザーがメガネなどの個別の要素を含む様々な要素を塗りつぶすと、それらは出力画像で識別・解釈されます。
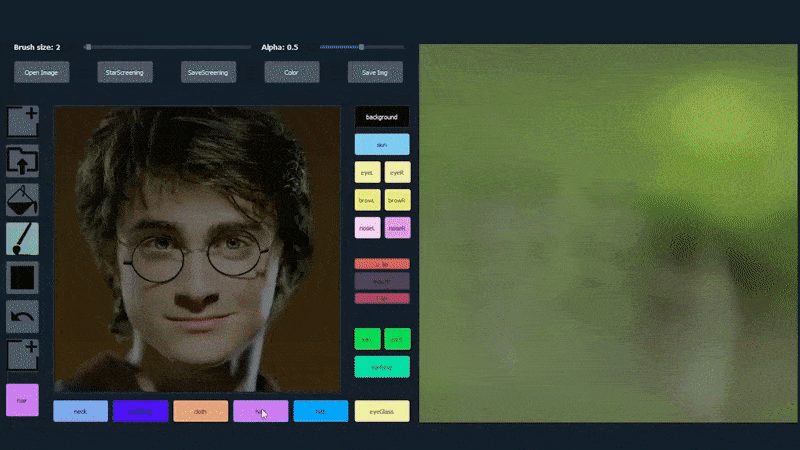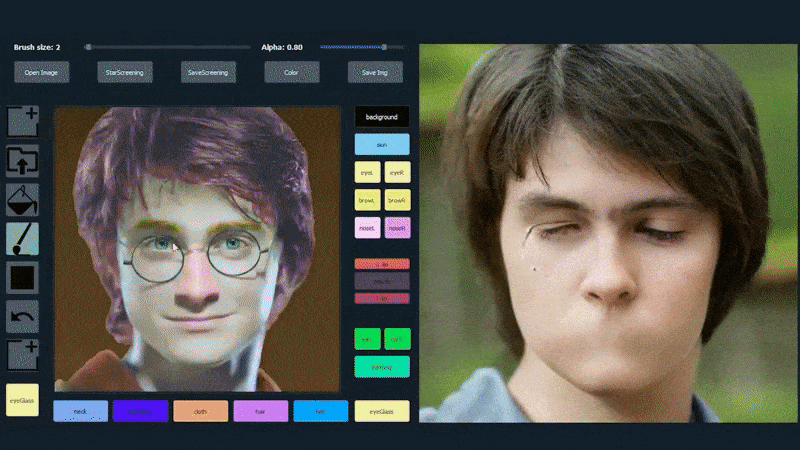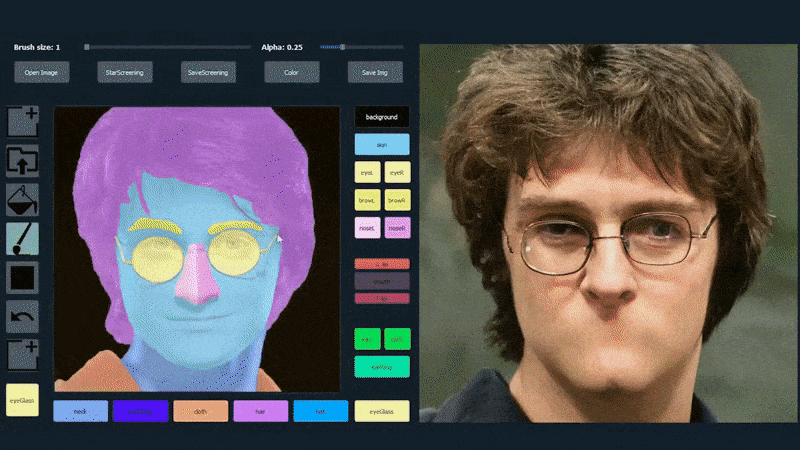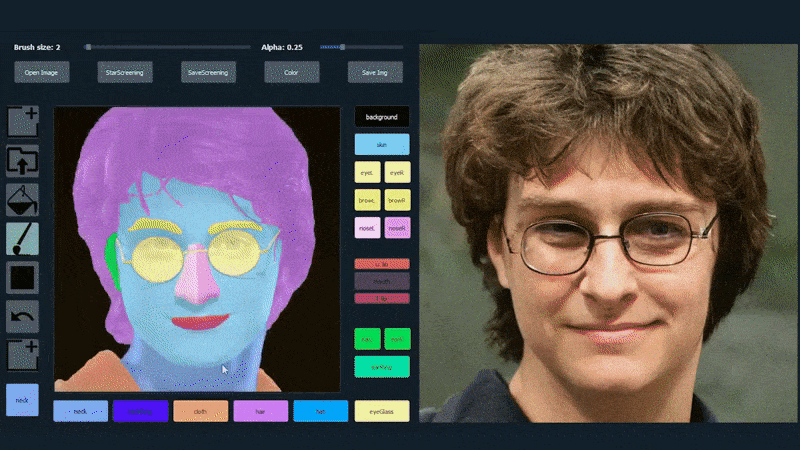
SofGANで生成された肖像画のトレース素材として1枚の画像を使用。 Source: 論文のタイトルはSofGAN: A Portrait Image Generator with Dynamic Stylingで、Anpei ChenとRuiyang Liuが主導し、上海科技大学の他の2名の研究者とカリフォルニア大学サンディエゴ校の1名の研究者が参加しています。
特徴の分離
この研究の主な貢献は、ユーザーフレンドリーなUXを提供することよりも、むしろ学習された顔の特徴(ポーズやテクスチャなど)の特性を「分離」することにあります。これにより、SofGANはカメラ視点に対して間接的な角度にある顔も生成できます。 [caption id="attachment_177109" align="alignnone" width="650"]
テクスチャがジオメトリから分離されたため、顔の形状とテクスチャも別個のエンティティとして操作できるようになりました。実際、これによりソース顔の人種変更が可能になります。これはスキャンダラスな慣行でしたが、現在では作成において、人種的にバランスの取れた機械学習データセットの作成という、潜在的に有用な応用が可能です。 

SofGANは老化を反復的なスタイルとして実装できます。
SofGANの方法論におけるもう一つの画期的な点は、トレーニングにペアになったセグメンテーション/実画像を必要とせず、ペアになっていない実世界の画像で直接トレーニングできることです。 研究者らは、SofGANの「分離」アーキテクチャは、画像の個々の側面を分解する従来の画像レンダリングシステムに触発されたと述べています。視覚効果ワークフローでは、合成のための要素は通常、最も細かいコンポーネントまで分解され、各コンポーネントに専門家が専念しています。
Semantic Occupancy Field (SOF)
これを機械学習の画像合成フレームワークで実現するために、研究者らはsemantic occupancy field (SOF) を開発しました。これは、顔の肖像画の構成要素を個別化する従来のoccupancy fieldの拡張です。SOFは、校正されたマルチビューセマンティックセグメンテーションマップでトレーニングされましたが、グラウンドトゥルースの監督は一切ありませんでした。

単一のセグメンテーションマップ(左下)からの複数の反復。
さらに、2Dセグメンテーションマップは、SOFの出力をレイトレーシングして取得され、その後GANジェネレーターによってテクスチャリングされます。「合成」セマンティックセグメンテーションマップも、3層エンコーダーを介して低次元空間にエンコードされ、視点が変更されたときの出力の連続性が確保されます。 トレーニングスキームは、各セマンティック領域に対して2つのランダムスタイルを空間的に混合します。

SofGANのアーキテクチャ。
研究者らは、SofGANが現在の代替的な最先端(SOTA)アプローチよりも低いFrechet Inception Distance(FID)と、より高いLearned Perceptual Image Patch Similarity(LPIPS)メトリクスを達成すると主張しています。 従来のStyleGANアプローチは、特徴の絡み合いによって頻繁に妨げられてきました。これは、画像を構成する要素が互いに回復不能に結びつき、望ましい要素と一緒に望ましくない要素が現れる(例えば、トレーニング時にイヤリングが特徴の画像によって情報が与えられた耳の形状をレンダリングすると、イヤリングが現れる可能性がある)原因となります。

レイマーチングはセマンティックセグメンテーションマップの体積を計算するために使用され、複数の視点を可能にします。
データセットとトレーニング
SofGANの様々な実装の開発には、3つのデータセットが使用されました:CelebA-HQデータセットから取られた30,000枚の高解像度画像のリポジトリであるCelebAMask-HQ;70,000枚の画像を含むNVIDIAのFlickr-Faces-HQ(FFHQ)(研究者らは事前にトレーニングされた顔パーサーで画像にラベルを付けました);そして手動でラベル付けされたセマンティック領域を持つ122のポートレートスキャンからなる自作のグループです。 SOFは、ハイパーネット、レイマーチャー(上記画像参照)、および分類器の3つのトレーニング可能なサブモジュールで構成されています。このプロジェクトのSemantic Instance Wised (SIW) StyleGANジェネレーターは、いくつかの側面でStyleGAN2と同様に構成されています。データ拡張はランダムなスケーリングとクロッピングによって適用され、トレーニングは4ステップごとにパス正則化を特徴とします。トレーニング全体の手順は、CUDA 10.1上で4つのRTX 2080 Ti GPUを使用して800,000回の反復に達するまで22日間かかりました。 論文は、各11GBから22GBのVRAMを収容できる2080カードの構成については言及していません。つまり、SofGANをトレーニングするためにほぼ1か月間使用された総VRAMは、44GBから88GBのどこかです。 研究者らは、許容できる汎用的で高レベルの結果が、トレーニング開始から3日目、1500回の反復というトレーニングのごく早い段階で現れ始めたと観察しています。トレーニングの残りは、髪や目の細部などの微細なディテールを取得するための予測可能なゆっくりとした進展に費やされました。 SofGANは一般に、単一のセグメンテーションマップから、NVIDIAのSPADEやPix2PixHD、そしてSEANなどの競合手法よりも現実的な結果を達成します。 












